Cetacean call recognition and classification model based on multimodal MAE data augmentation network
-
摘要: 被动声学监测中的叫声识别与分类是海洋动物保护与种群调查的重要手段。针对叫声识别与分类中存在的数据稀缺与类间不平衡问题, 数据增强方法具有重要的实用价值与研究意义。然而海洋动物叫声拥有丰富的声学信息, 仅依赖于频域特征提取缺乏对音频结构与语义的建模能力, 难以有效捕捉叫声的深层特征。为此, 文中提出了一种基于多模态掩码自编码器(MAE-MF)的数据增强网络, 突破单模态信息局限, 以梅尔频谱图为主模态, 融合时序特征与帧级统计指标构成多模态输入, 并引入语义标签作为条件引导重建。为科学验证该数据增强网络的有效性与实用价值, 文中基于MAE-MF数据增强网络, 构建鲸豚叫声识别分类模型。模型在Watkins数据集上表现优异, 相较主流算法, 频谱图重建效果更佳。实验测得6类鲸豚物种平均识别准确率达97.6%, 较基础MAE方法提升6.72个百分点。该方案可有效改善样本类别失衡问题, 也为鲸豚保护相关研究提供了可靠的技术支撑。Abstract: Passive acoustic monitoring-based call recognition and classification are essential means for marine animal conservation and population surveys. To address the issues of data scarcity and inter-class imbalance in call recognition and classification, data augmentation methods hold significant practical value and research importance. However, marine animal calls contain rich acoustic information, and relying solely on frequency-domain feature extraction lacks the capability to model audio structure and semantics, making it difficult to effectively capture the deep features of calls. To this end, this paper proposes a data augmentation network based on a multimodal masked autoencoder (MAE-MF), which breaks through the limitations of single-modal information. The network employs Mel-spectrograms as the primary modality, integrates temporal features and frame-level statistical metrics to form multimodal inputs, and incorporates semantic labels as conditional guidance for reconstruction. To scientifically validate the effectiveness and practical value of the proposed data augmentation network, a cetacean call recognition and classification model is further constructed based on the MAE-MF network. Experimental results on the Watkins dataset demonstrate superior performance of the proposed method, with improved spectrogram reconstruction quality compared to mainstream algorithms. The proposed method achieves an average recognition accuracy of 97.6% across six cetacean species, representing an improvement of 6.72 percentage points over the baseline MAE method. This scheme effectively alleviates the inter-class imbalance issue and provides reliable technical support for cetacean conservation research.
-
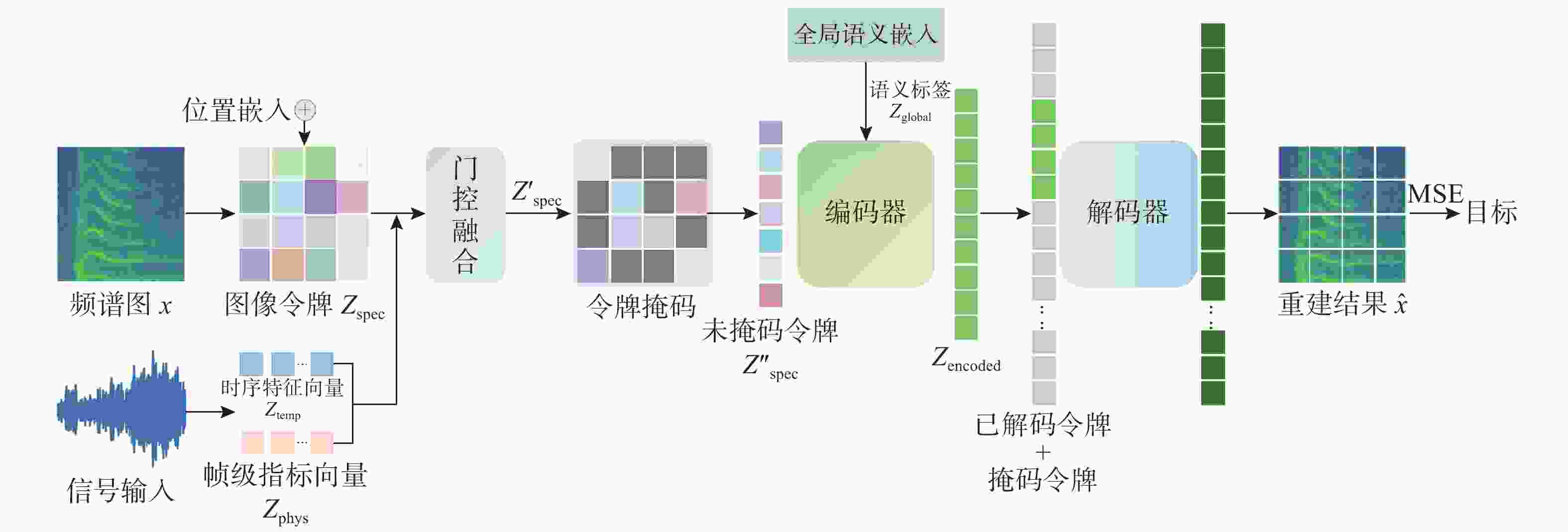
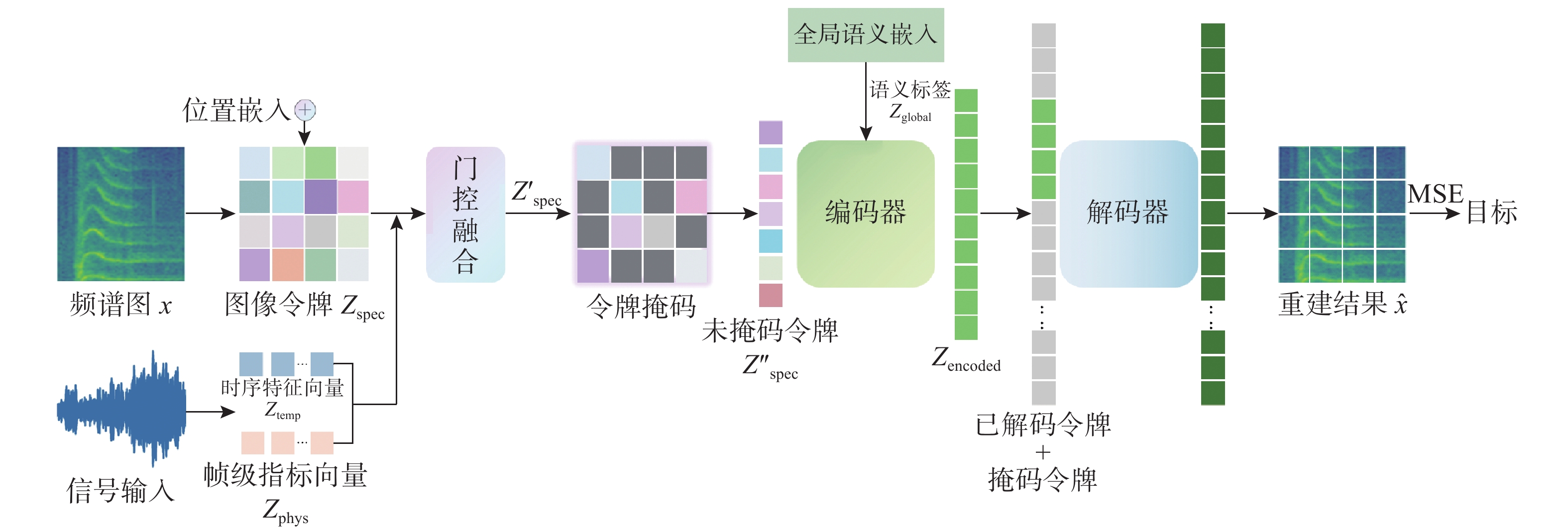
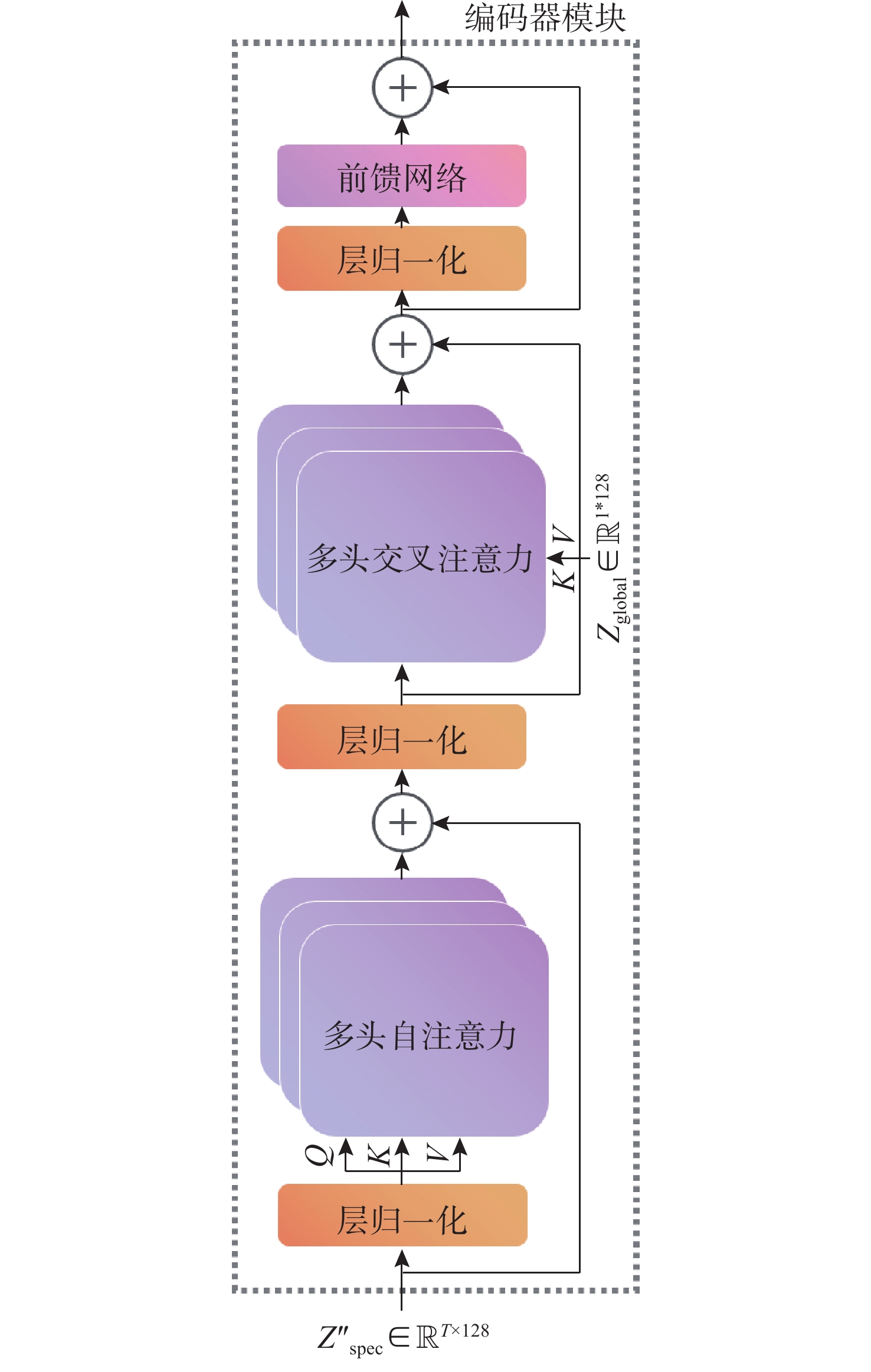
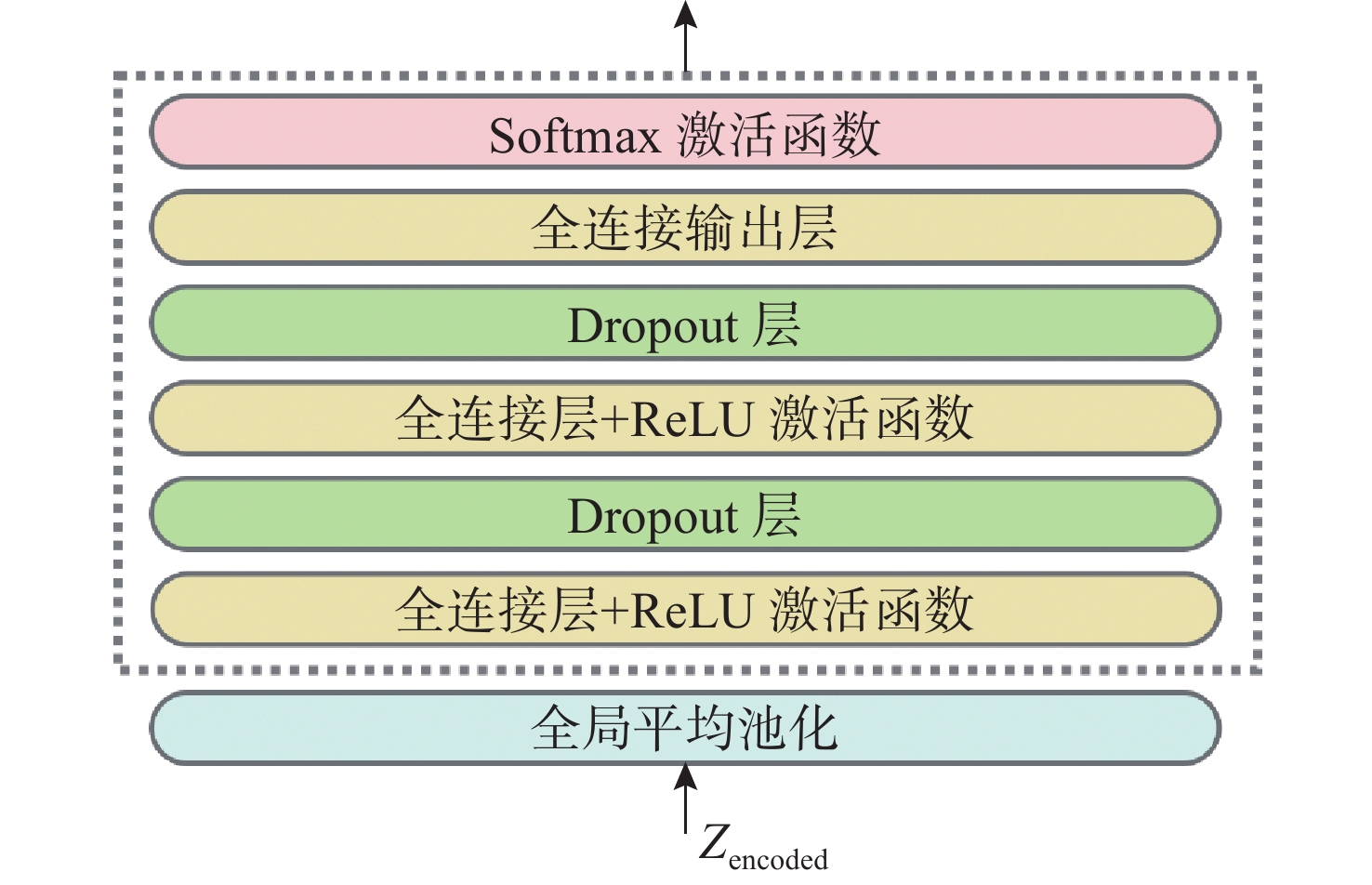
图 1 基于 MAE-MF 数据增强网络的鲸豚类叫声识别与分类模型图
Figure 1. Architecture of the cetacean call recognition and classification model based on the MAE-MF data augmentation network
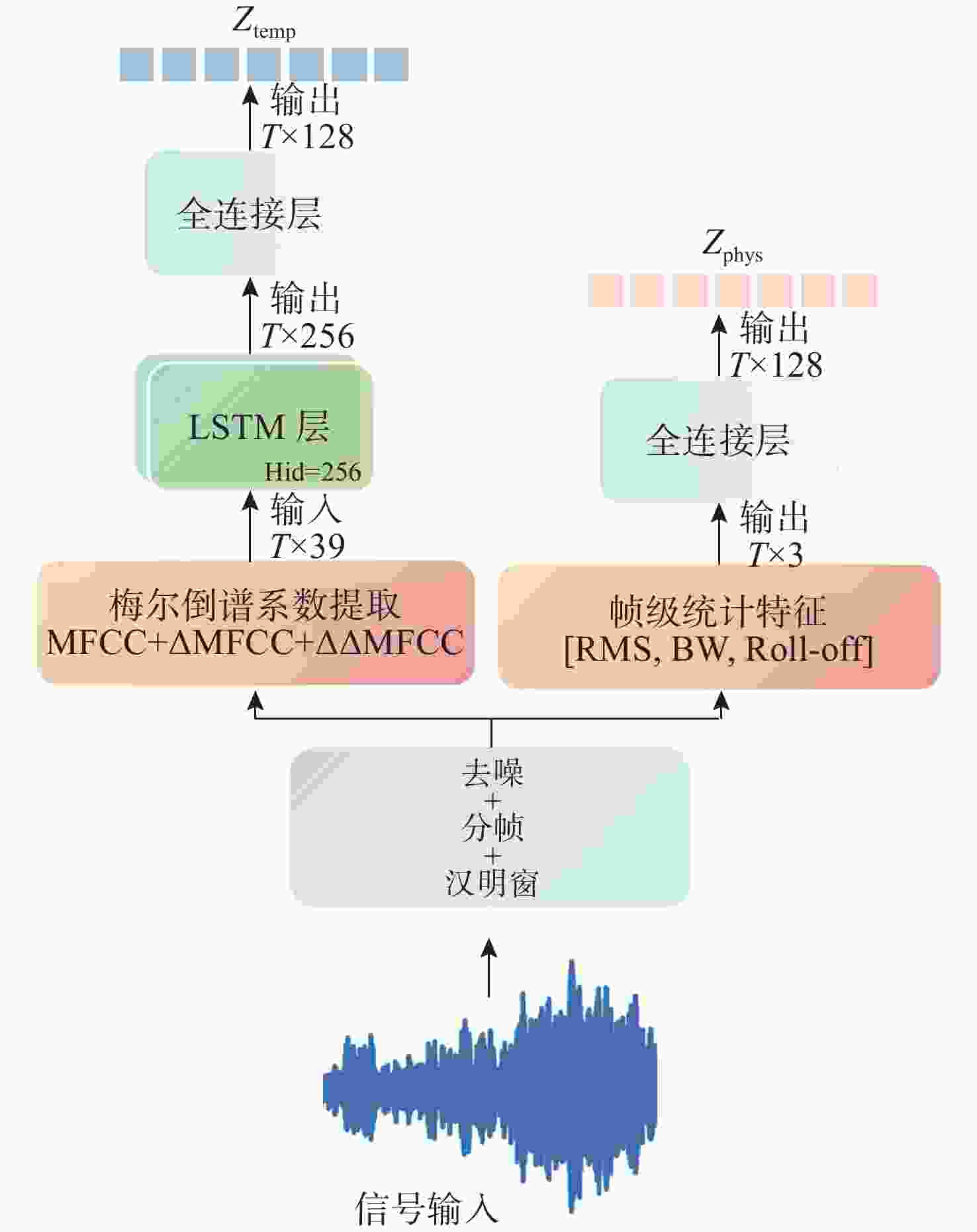
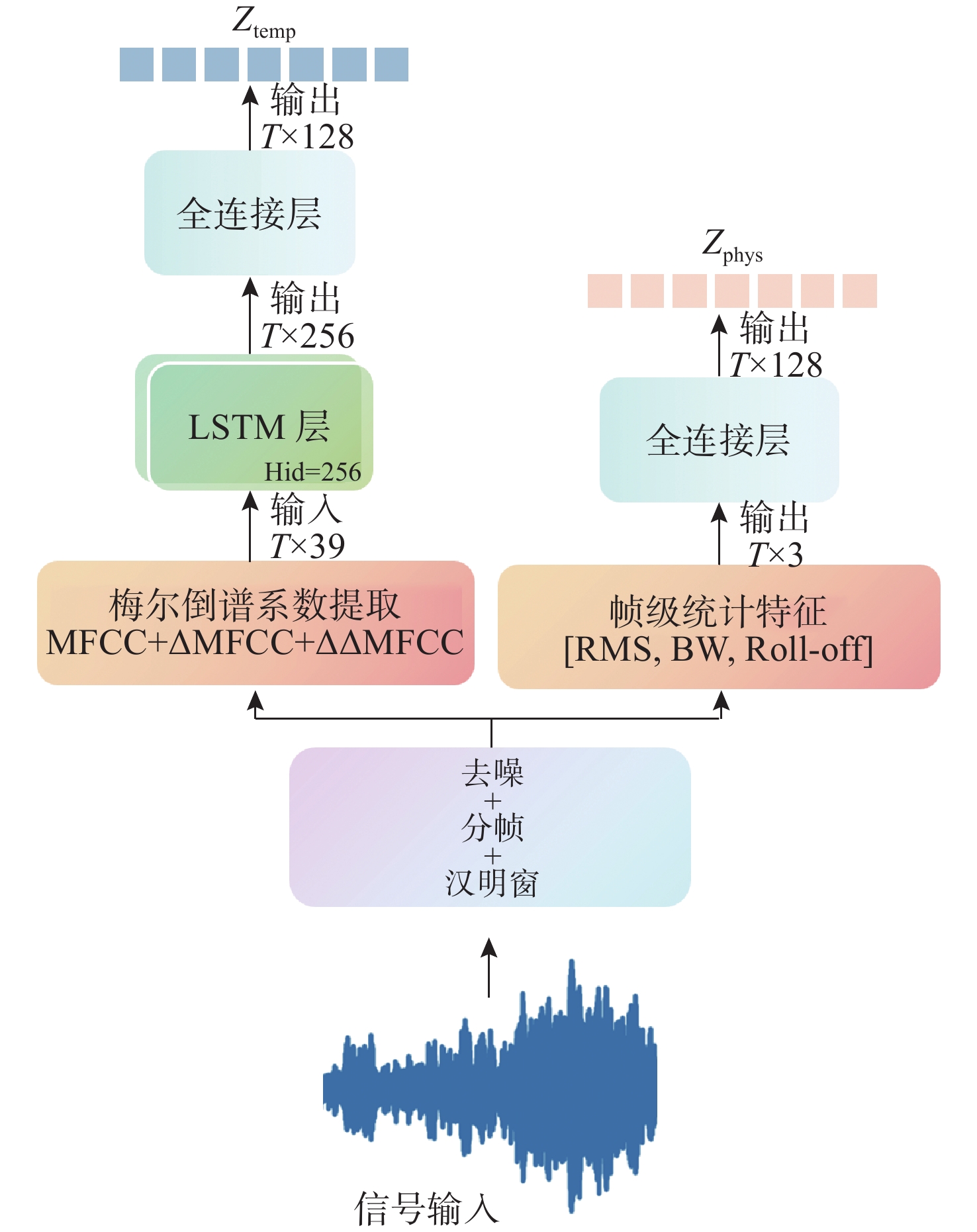
图 2 时序特征和帧级指标提取结构图
Figure 2. Time sequence feature and frame level index extraction structure diagram
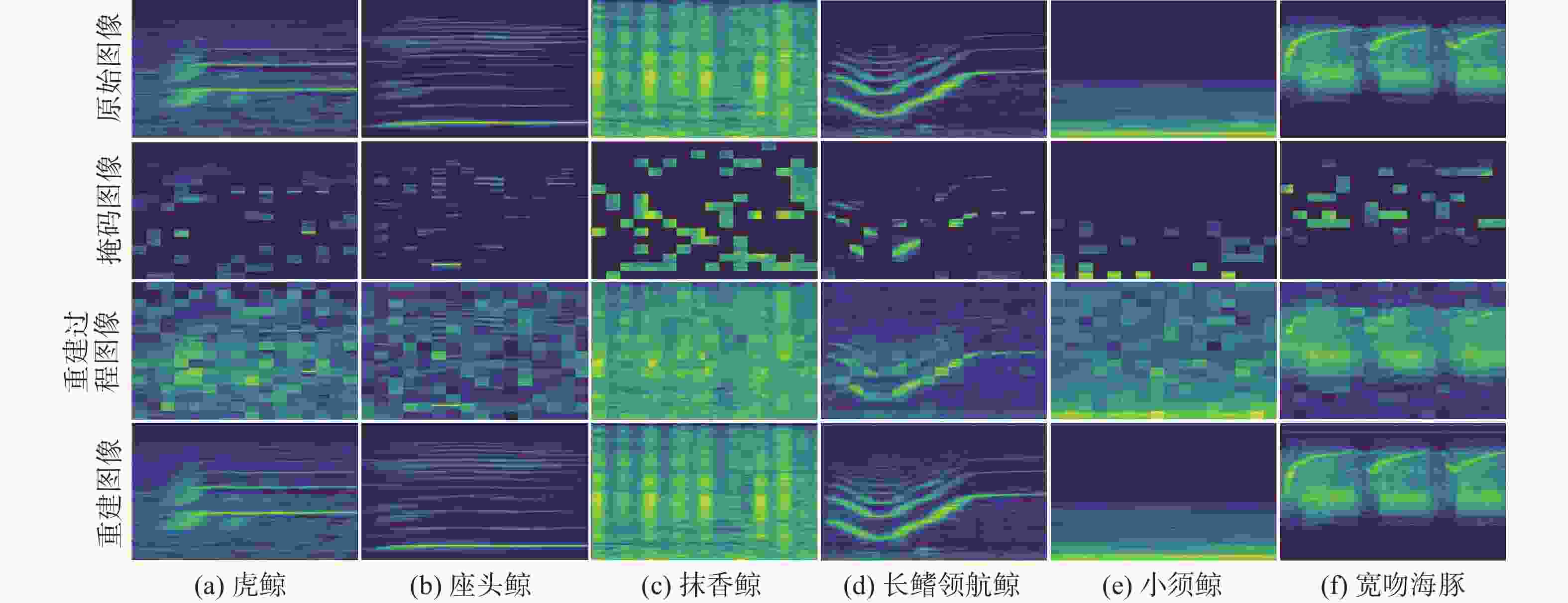
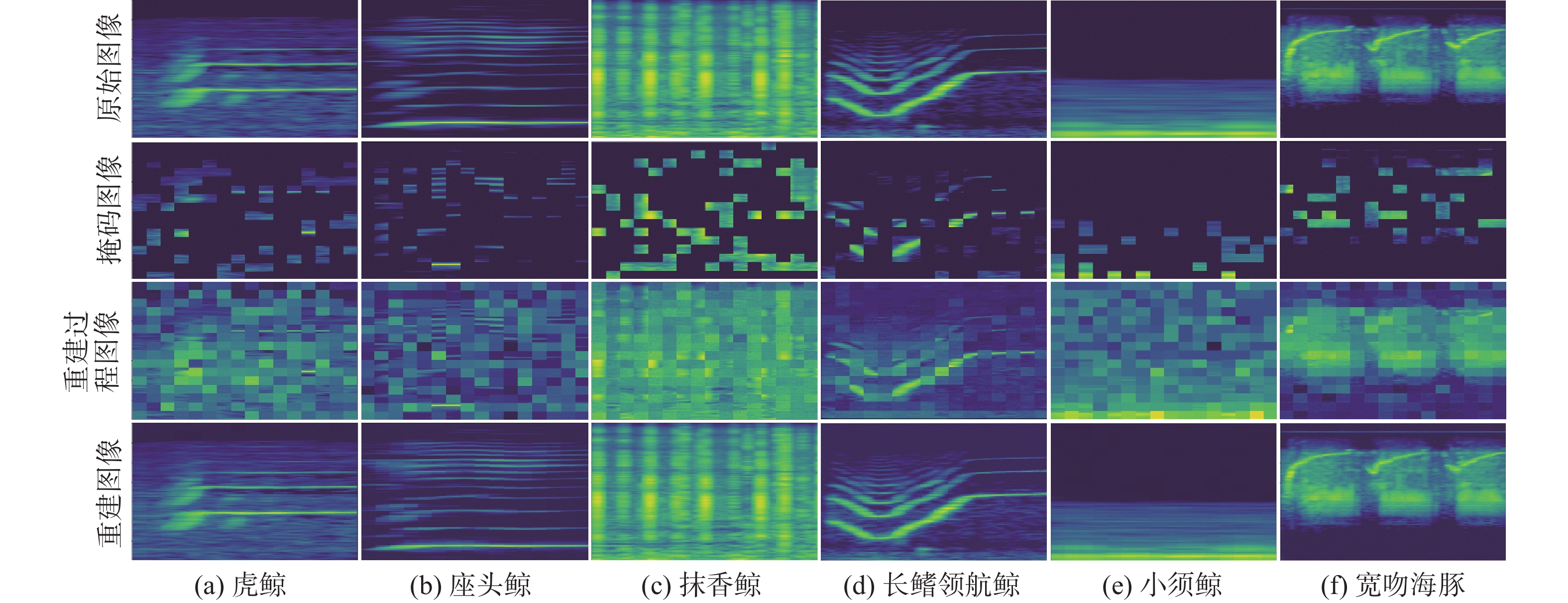
图 6 75%掩码比率下梅尔谱图重建效果图
Figure 6. Reconstruction effect of Mel spectrum at 75% mask ratio
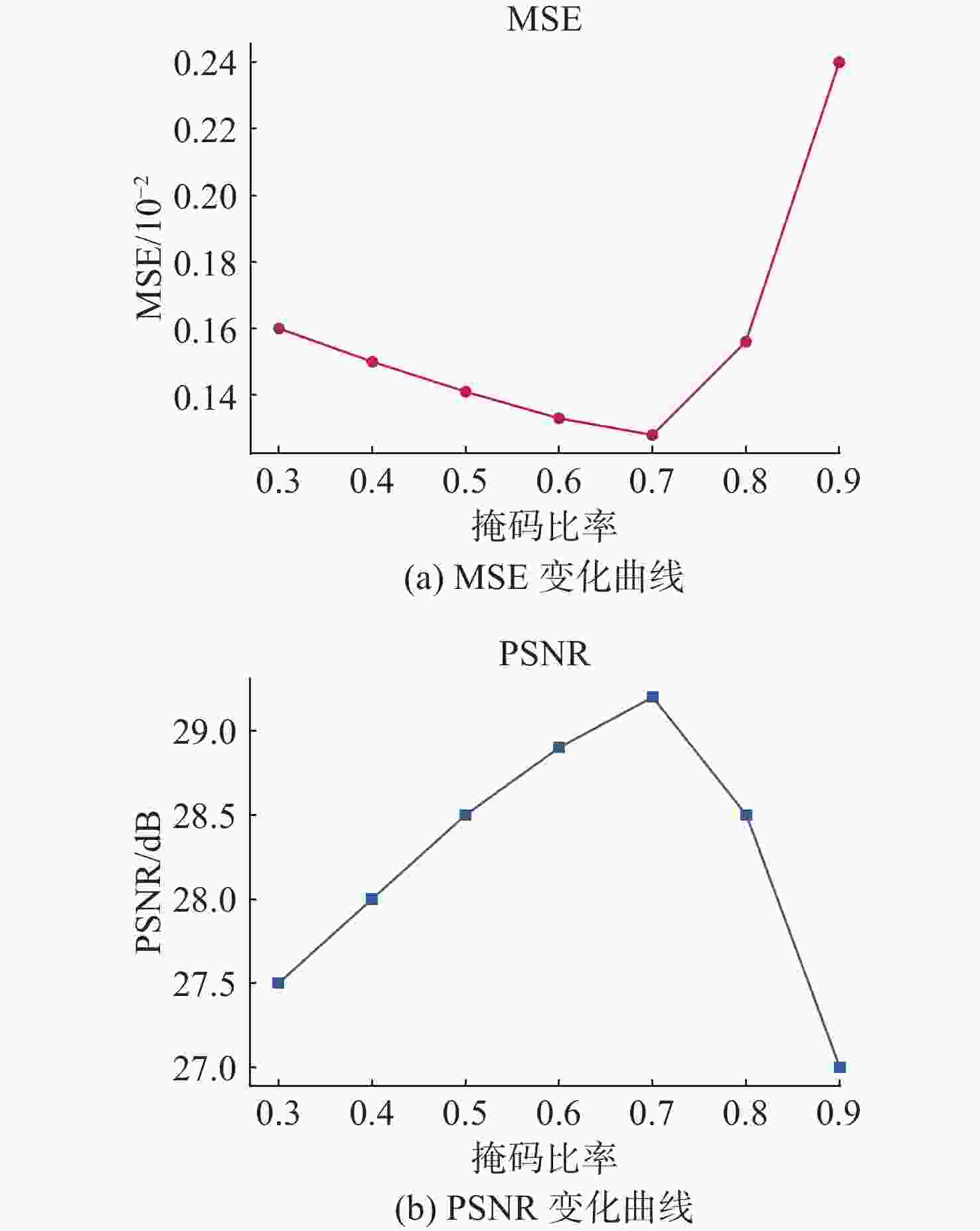
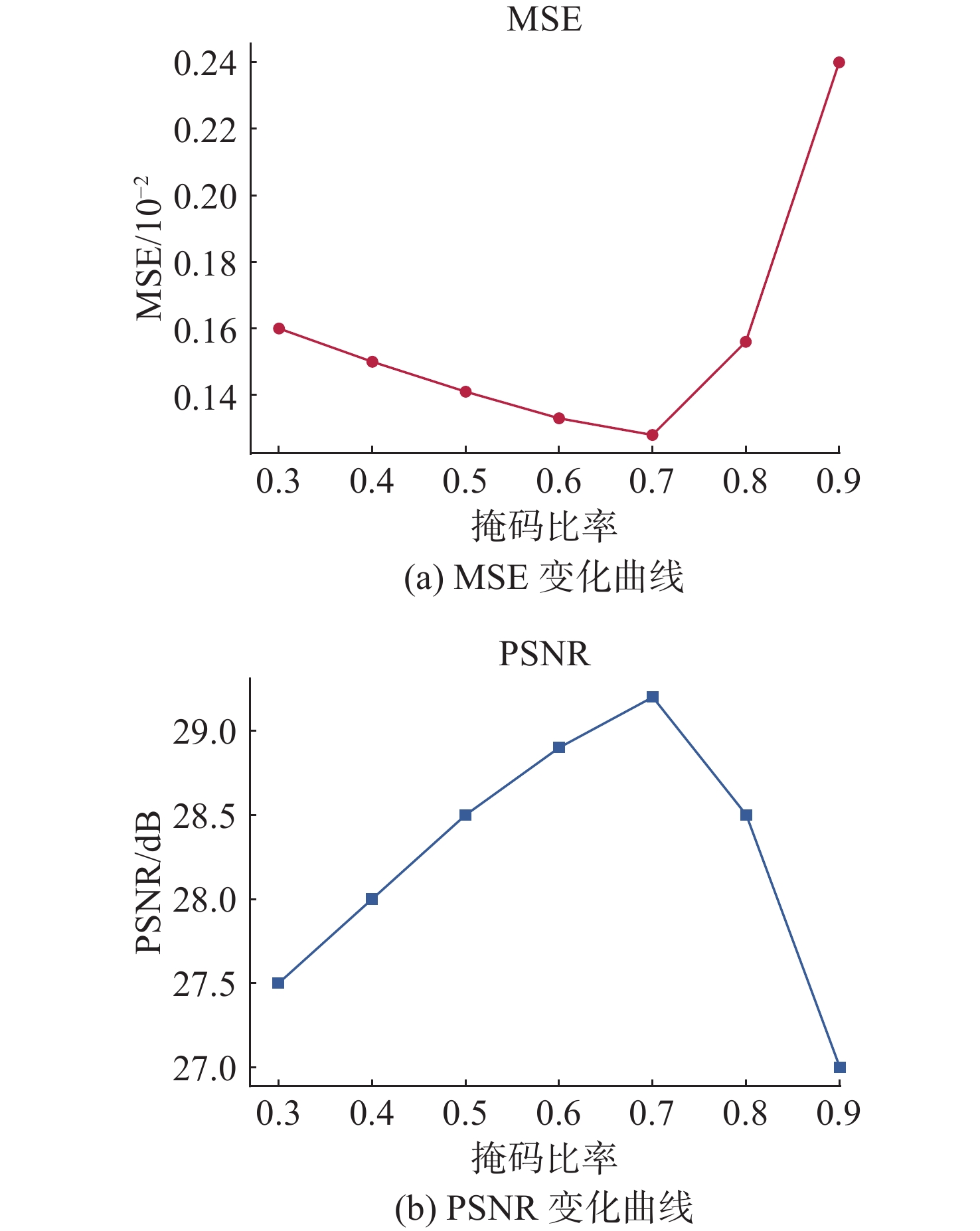
图 7 不同掩码比例下MSE、PSNR的变化曲线
Figure 7. The variation curves of MSE and PSNR under different mask ratios
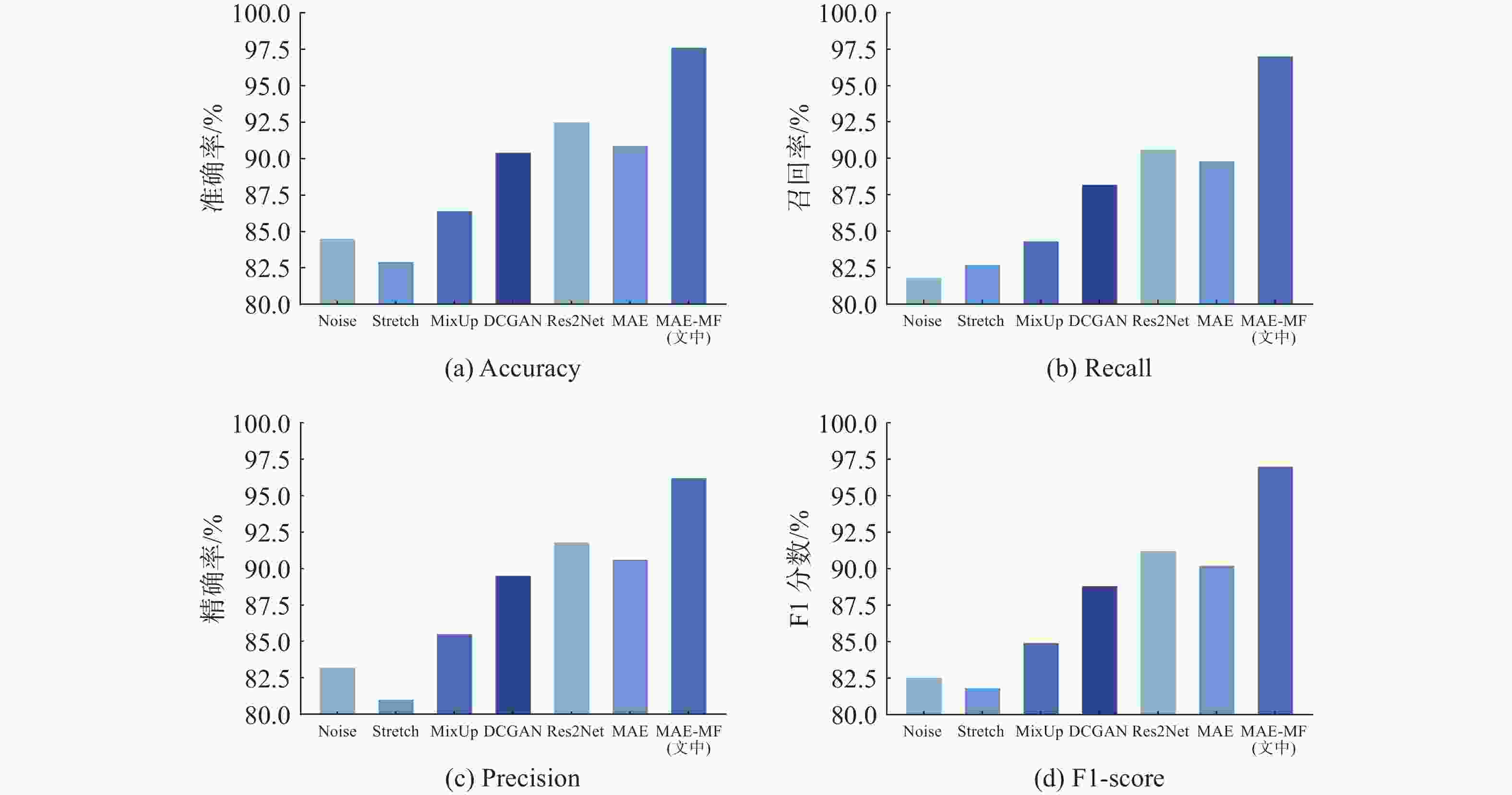
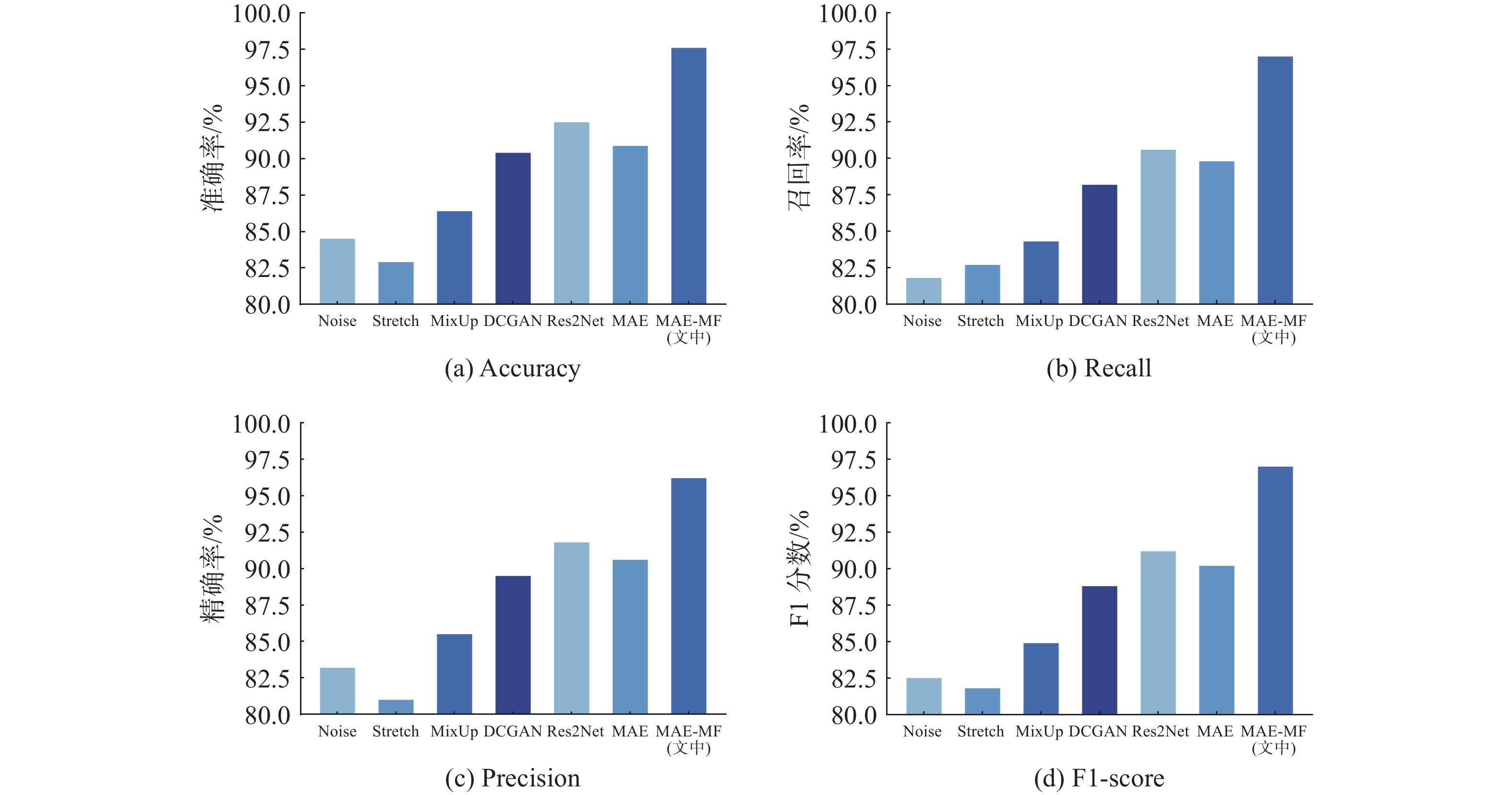
图 8 基于不同网络分类性能对比
Figure 8. Comparison of classification performance based on different networks
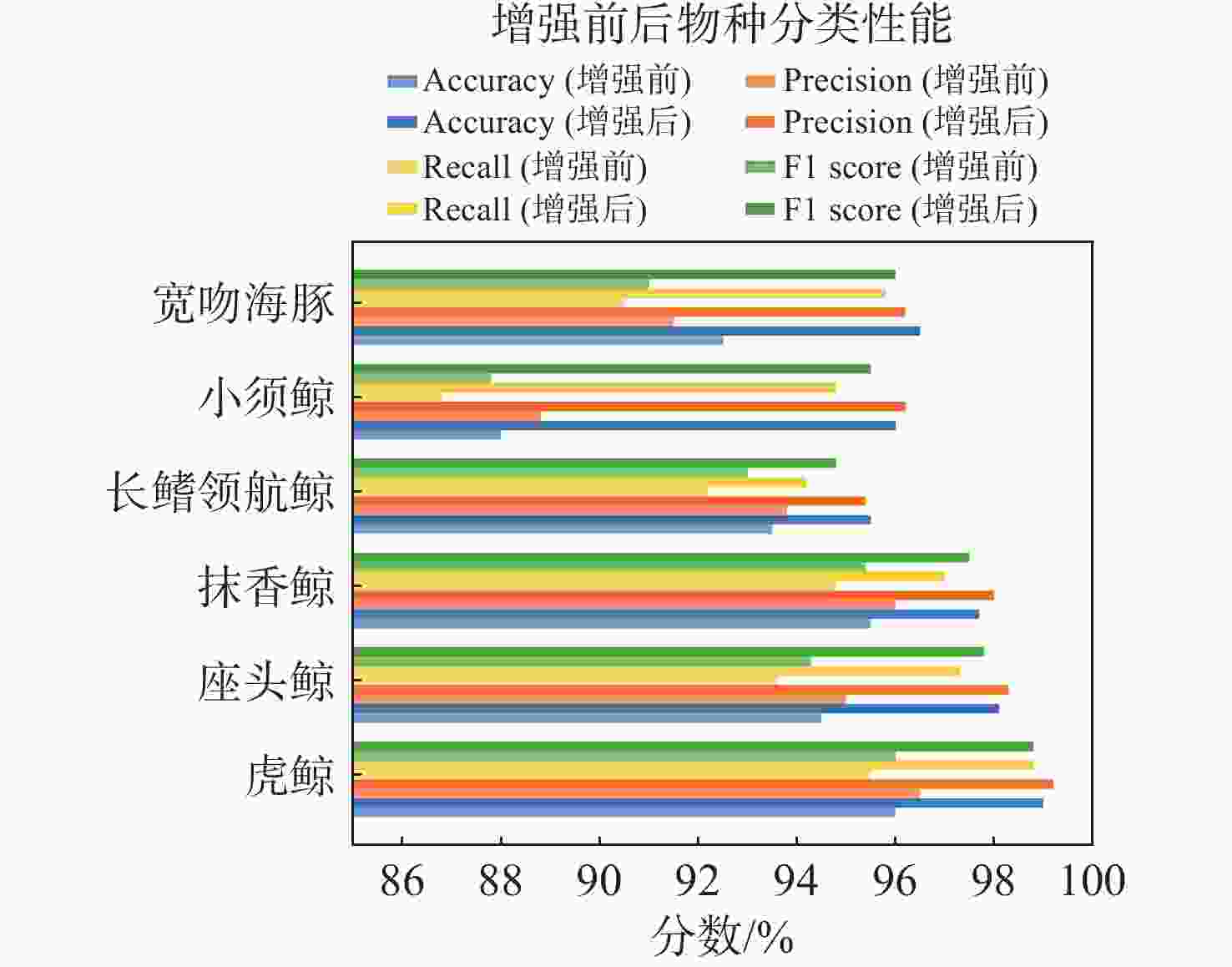
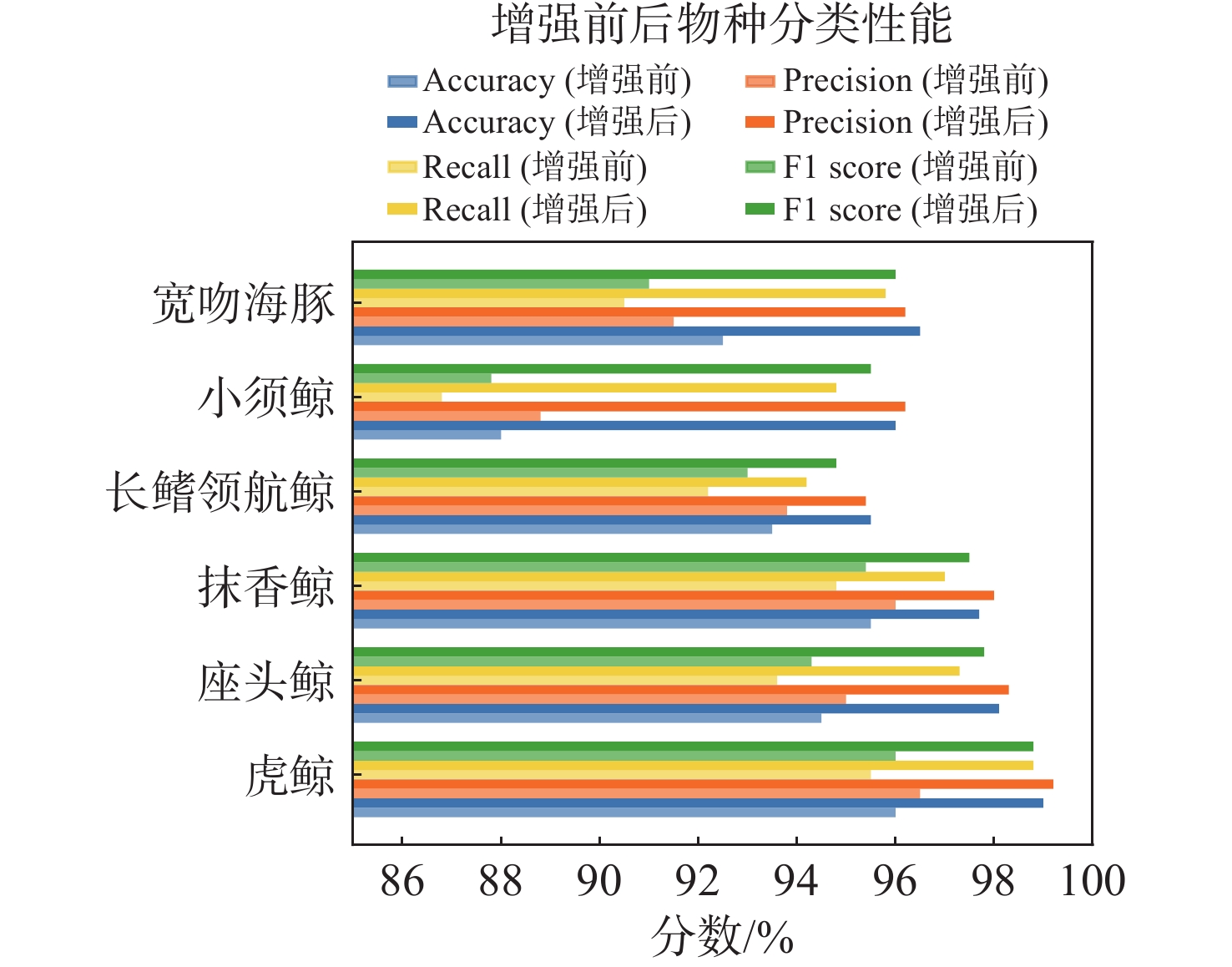
图 9 数据增强前后识别与分类性能的比较
Figure 9. Comparison of recognition and classification performance before and after data enhancement
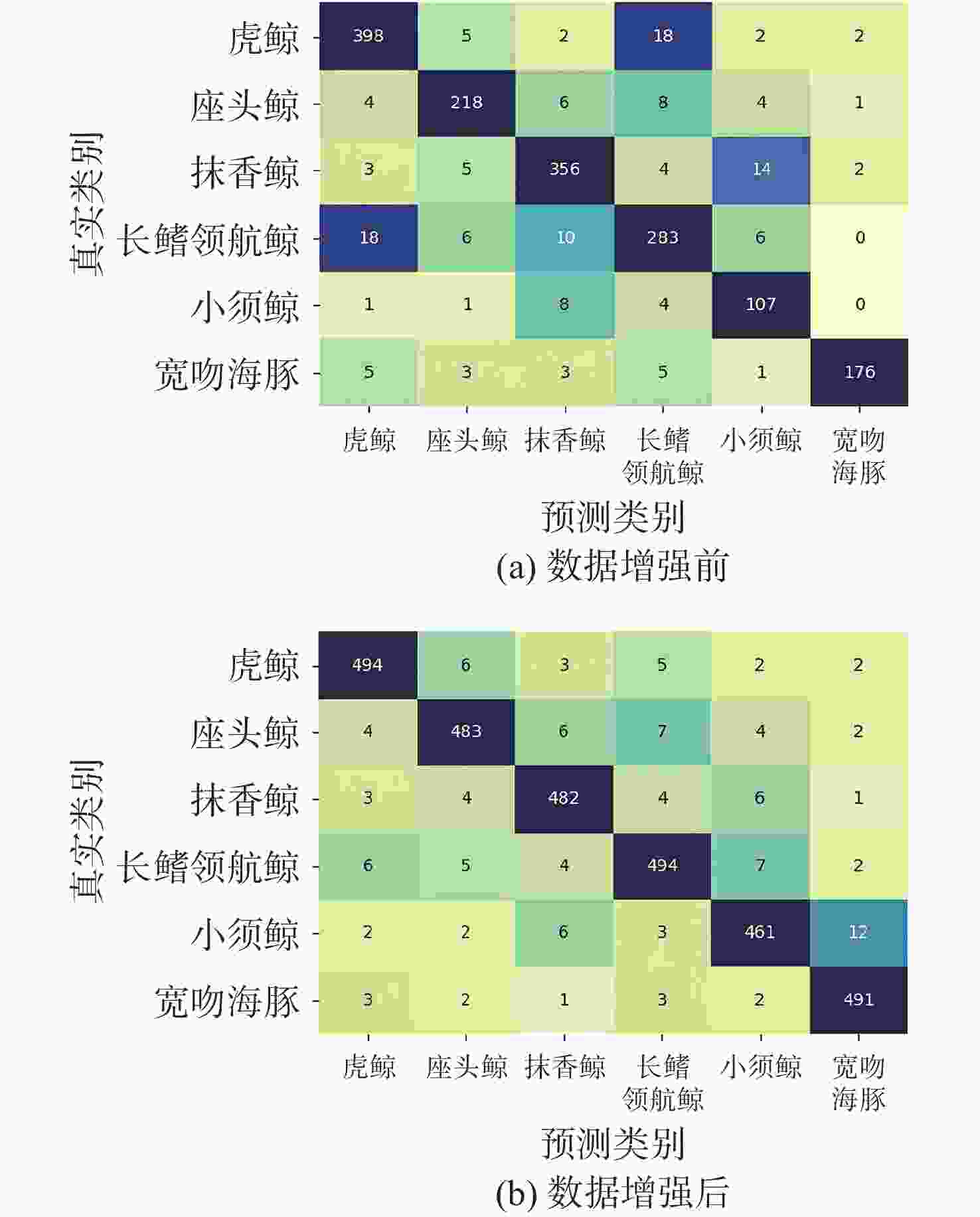
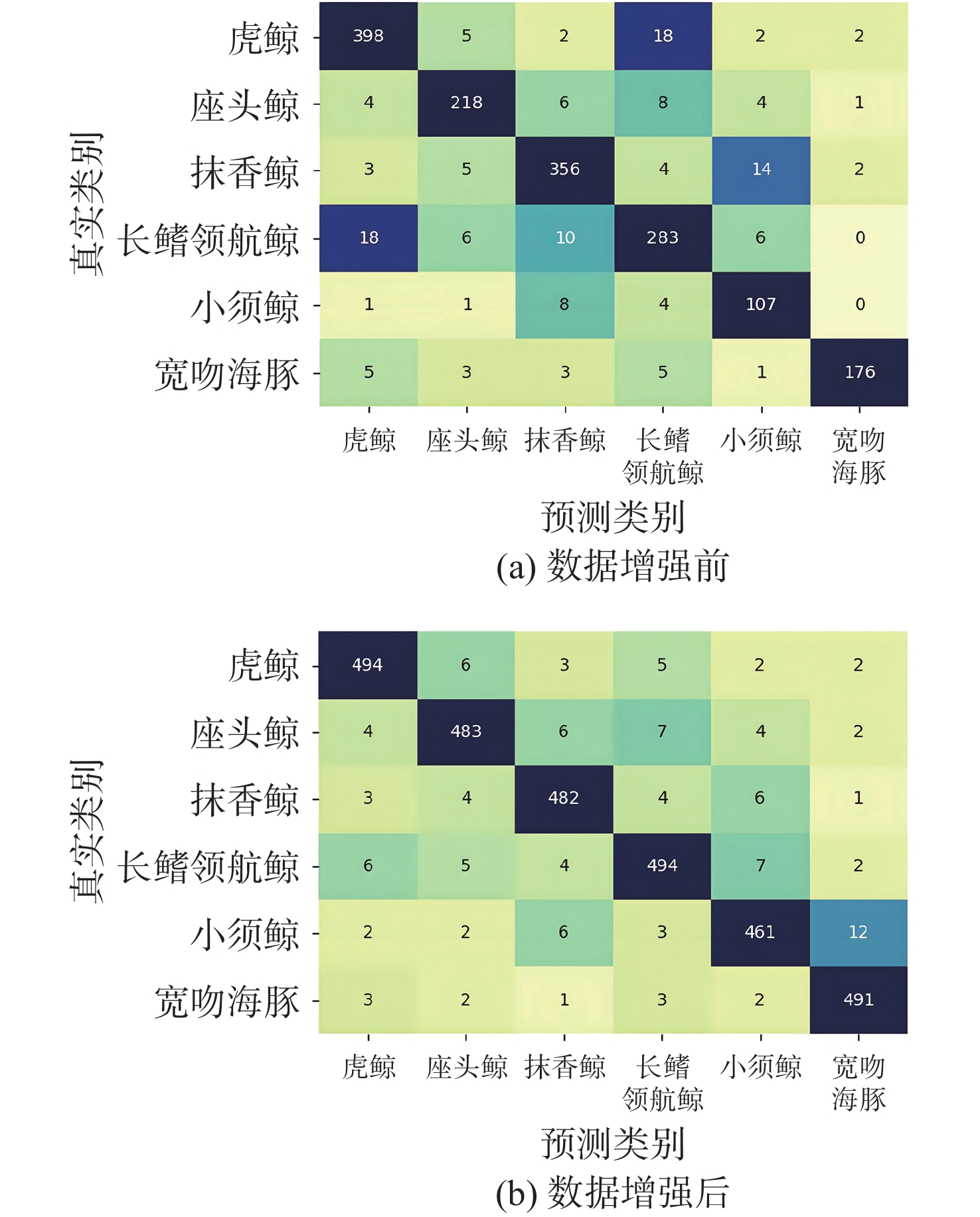
图 10 MAE-MF模型数据增强前后识别分类混淆矩阵图
Figure 10. MAE-MF model recognition and classification confusion matrix before and after data enhancement
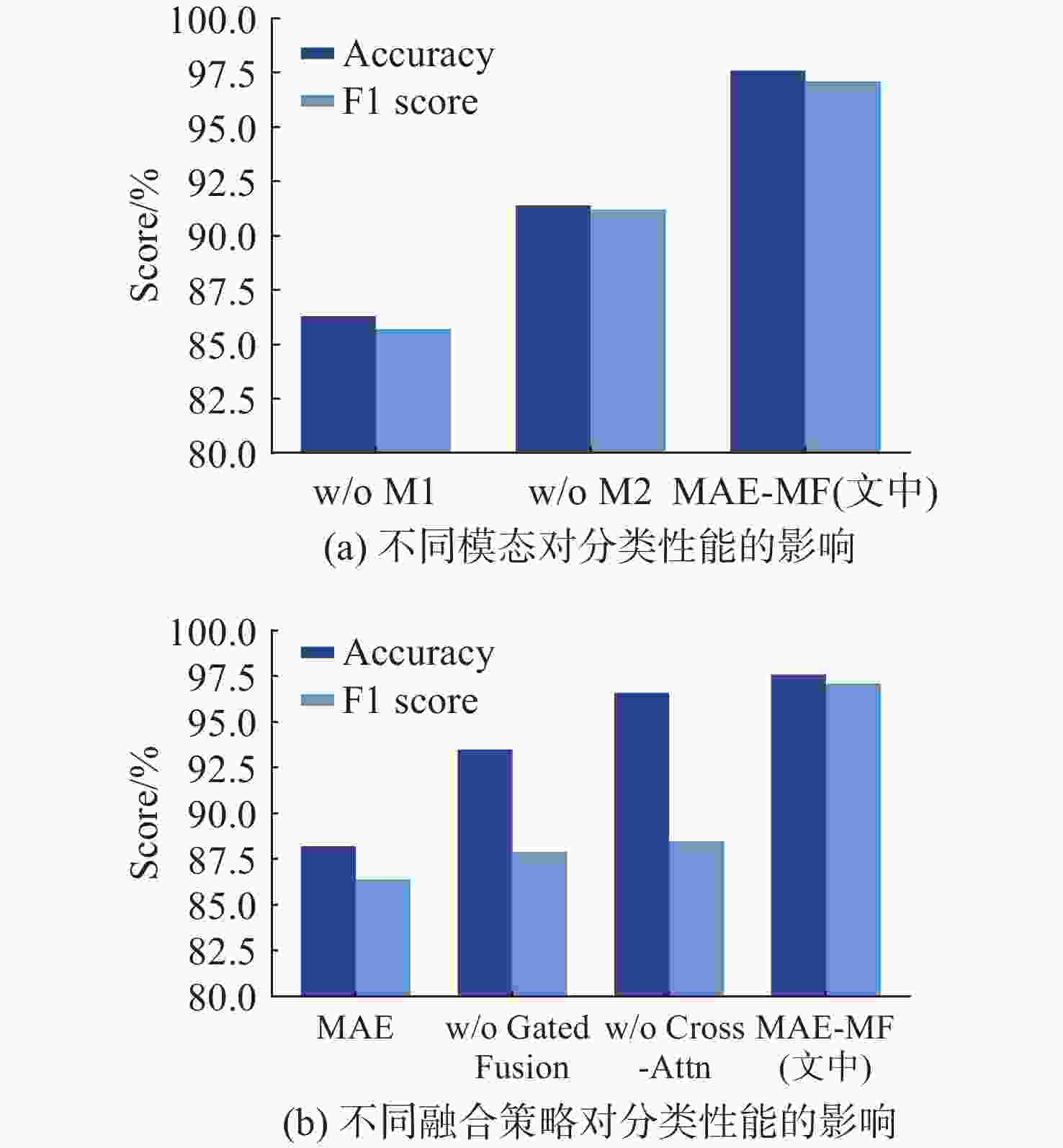
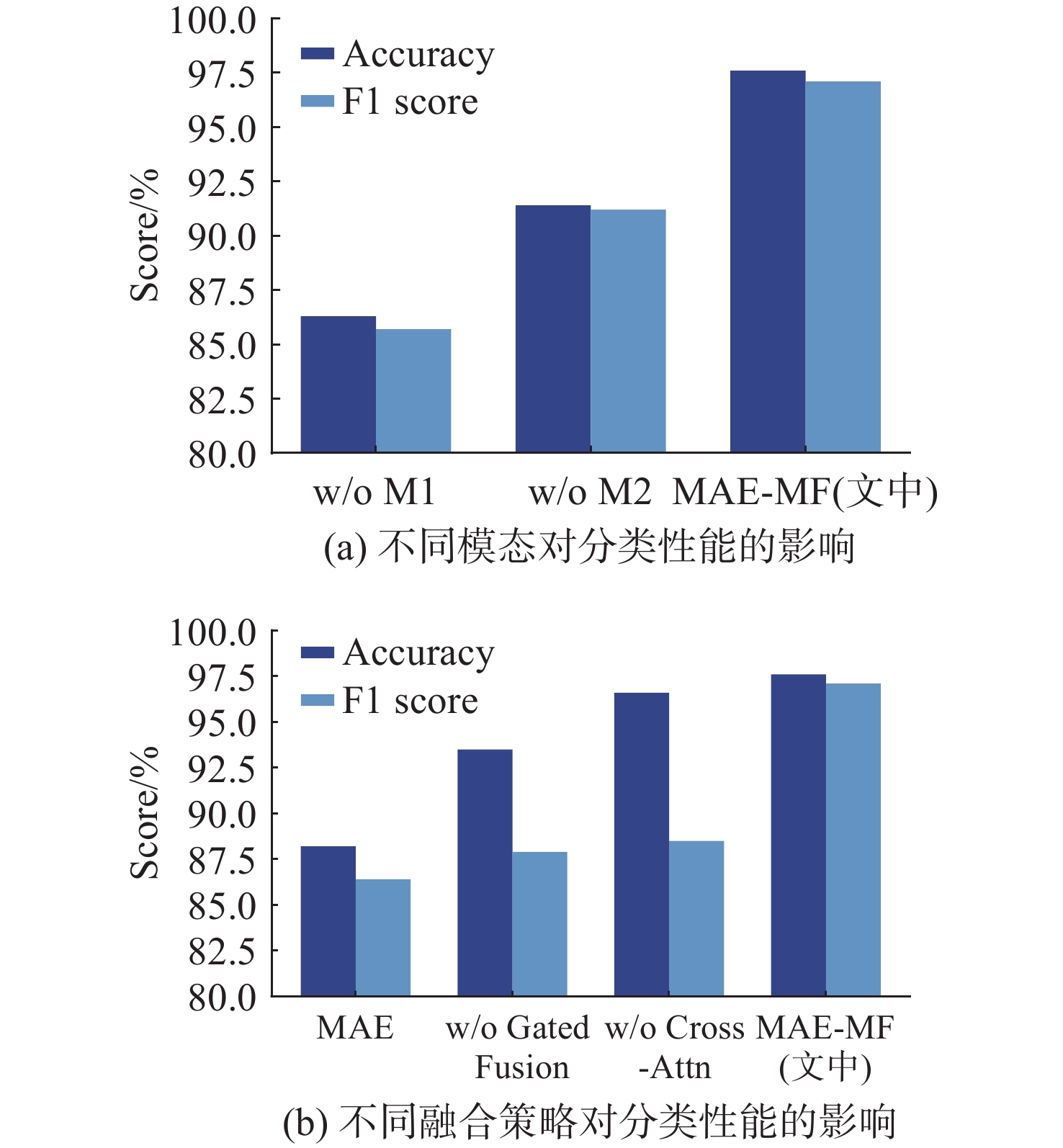
图 11 不同组合对分类性能的影响
Figure 11. Effects of different combinations on classification performance
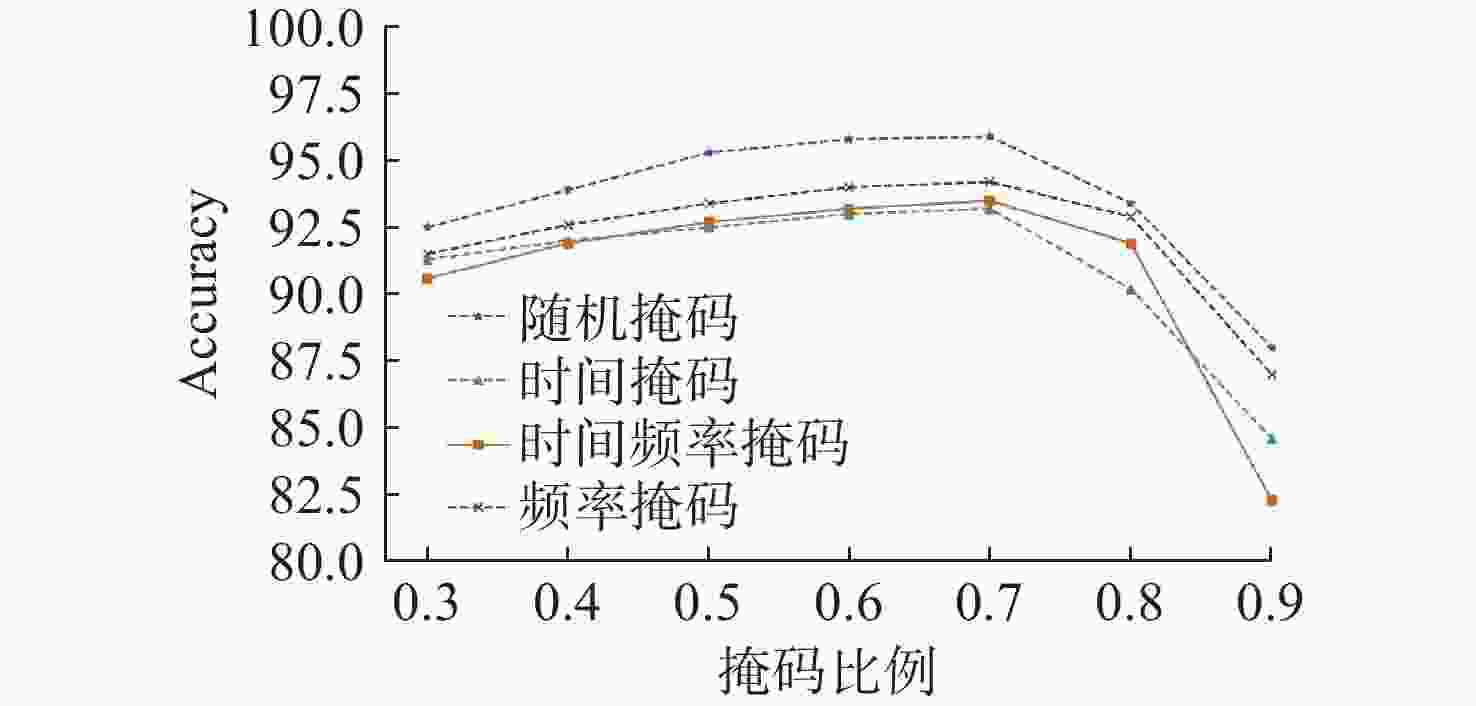
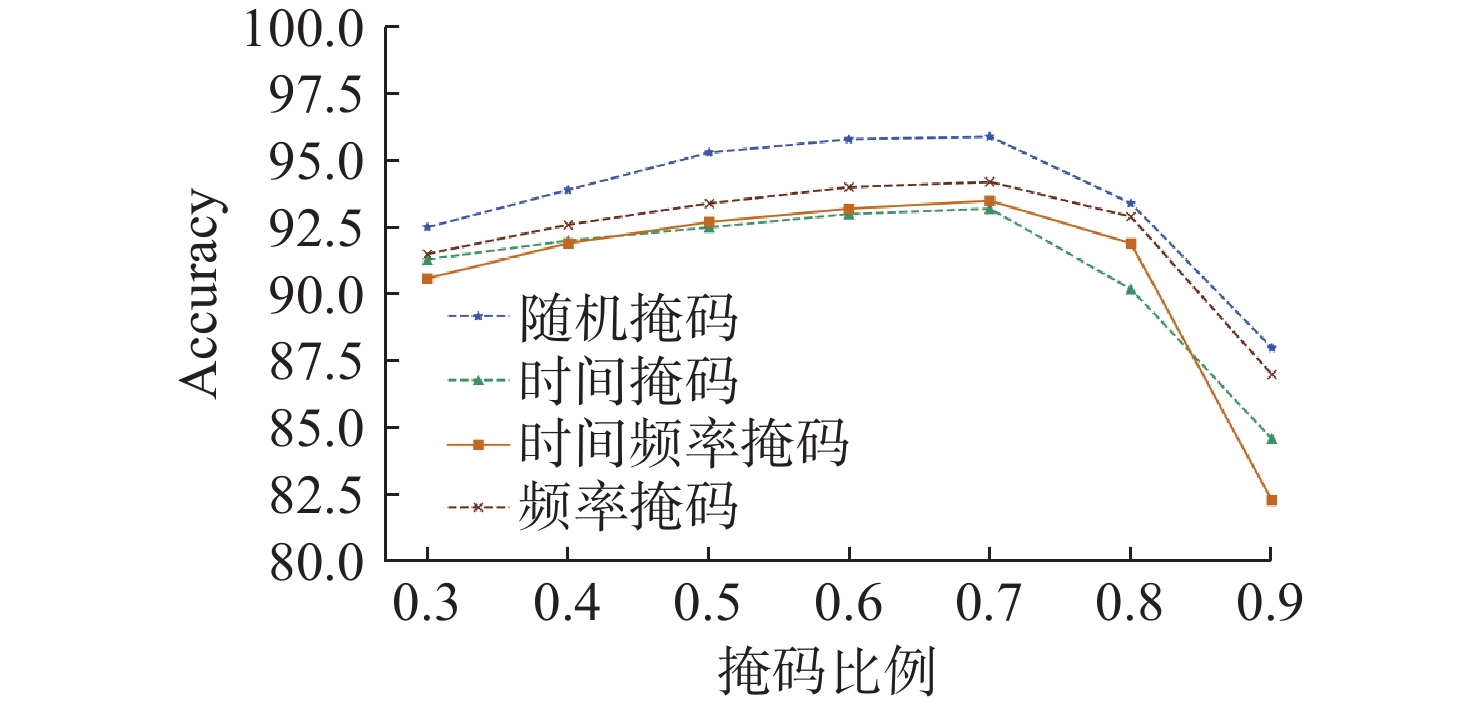
图 12 不同掩码策略与掩码比率性能比较
Figure 12. Performance comparison of different mask strategies and mask ratios
表 1 Watkins数据集的物种分布与样本量
Table 1. Species distribution and sample size of Watkins dataset
序号 物种 样本量 1 虎鲸 2 134 2 座头鲸 1 204 3 抹香鲸 1 922 4 长鳍领航鲸 1 616 5 小须鲸 607 6 宽吻海豚 965  下载: 导出CSV
下载: 导出CSV
表 2 数据增强系数
Table 2. Data enhancement factor
序号 物种 样本量 增强系数 增强后样本量 1 虎鲸 2 134 1.2 2 560 2 座头鲸 1 204 2.1 2 528 3 抹香鲸 1 922 1.3 2 498 4 长鳍领航鲸 1 616 1.6 2 586 5 小须鲸 607 4.0 2 428 6 宽吻海豚 965 2.6 2 509
下载: 导出CSV
表 3 模型训练超参数设置表
Table 3. Model training hyperparameter setting table
阶段 优化器 初始
学习率批量
大小训练
轮数权重衰
减系数训练 AdamW 0.000 2 128 100 $ 5\times {10}^{-2} $ 微调 AdamW 0.000 1 64 50 $ 1\times {10}^{-2} $
下载: 导出CSV
表 4 不同模型频谱重建质量评估结果
Table 4. Evaluation results of spectrum reconstruction quality for different models
模型 MSE($ {\times 10}^{-2} $) PSNR/dB SSIM DCGAN 0.30 25.23 0.82 MAE-Res2Net 0.20 26.99 0.88 MAE 0.18 27.45 0.90 MAE-MF(文中) 0.14 28.66 0.92
下载: 导出CSV
表 5 各类动物频谱重建质量评估结果
Table 5. Evaluation results of spectral reconstruction quality of various animals
物种 MSE($ {\times 10}^{-2} $) PSNR/dB SSIM 虎鲸 0.12 29.21 0.94 座头鲸 0.10 30.00 0.95 抹香鲸 0.14 28.53 0.92 长鳍领航鲸 0.15 28.24 0.90 小须鲸 0.16 27.96 0.89 宽吻海豚 0.19 27.21 0.86
下载: 导出CSV
-
[1] Montgomery J C, Radford C A. Marine bioacoustics[J]. Current Biology, 2017, 27(11): 502-507. doi: 10.1016/j.cub.2017.01.041 [2] Verfuss U K, Gillespie D, Gordon J, et al. Comparing methods suitable for monitoring marine mammals in low visibility conditions during seismic surveys[J]. Marine Pollution Bulletin, 2018, 126: 1-18. doi: 10.1016/j.marpolbul.2017.10.034 [3] Tyack P L. Implications for marine mammals of large-scale changes in the marine acoustic environment[J]. Journal of Mammalogy, 2008, 89(3): 549-558. doi: 10.1644/07-MAMM-S-307R.1 [4] Qiao Z, Liu S, Wang D, et al. Bio-inspired underwater acoustic communication through PCHIP-based whistle generation and improved CSS modulation[J]. Applied Acoustics, 2025, 235: 110673. doi: 10.1016/j.apacoust.2025.110673 [5] Li L, Qiao G, Liu S, et al. Automated classification of Tursiops aduncus whistles based on a depth-wise separable convolutional neural network and data augmentation[J]. The Journal of the Acoustical Society of America, 2021, 150(5): 3861-3873. doi: 10.1121/10.0007291 [6] Abayomi-Alli O O, Damaševičius R, Qazi A, et al. Data augmentation and deep learning methods in sound classification: A systematic review[J]. Electronics, 2022, 11(22): 3795. doi: 10.3390/electronics11223795 [7] Park D S, Chan W, Zhang Y, et al. SpecAugment: A simple data augmentation method for automatic speech recognition[J/OL]. arXiv: 1904.08779. (2019-04-18)[2026-04-16]. https://arxiv.org/abs/1904.08779. [8] Zhang H, Cisse M, Dauphin Y N, et al. Mixup: Beyond empirical risk minimization[J/OL]. arXiv: 1710.09412. (2017-10-25)[2026-04-16]. https://arxiv.org/abs/1710.09412. [9] Kopets E, Shpilevaya T, Vasilchenko O, et al. Generating synthetic sperm whale voice data using StyleGAN2-ADA[J]. Big Data and Cognitive Computing, 2024, 8(4): 40. doi: 10.3390/bdcc8040040 [10] Li P, Roch M A, Klinck H, et al. Learning stage-wise GANs for whistle extraction in time-frequency spectrograms[J]. IEEE Transactions on Multimedia, 2023, 25: 9302-9314. doi: 10.1109/TMM.2023.3251109 [11] Mellinger D K, Clark C W, et al. Recognizing transient low-frequency whale sounds by spectrogram correlation[J]. The Journal of the Acoustical Society of America, 2000, 107(6): 3518-3529. doi: 10.1121/1.429434 [12] Wahlberg M, Jensen F H, Aguilar Soto N, et al. Source parameters of echolocation clicks from wild bottlenose dolphins(tursiops aduncus and tursiops truncatus)[J]. The Journal of the Acoustical Society of America, 2011, 130(4): 2263-2274. doi: 10.1121/1.3624822 [13] Li X, Dong C, Dong G, et al. Marine mammal call classification using a multi-scale two-channel fusion network (MT-resformer)[J]. Journal of Marine Science and Engineering, 2025, 13(5): 944. doi: 10.3390/jmse13050944 [14] Vester H, Hammerschmidt K, Timme M, et al. Bag-of-calls analysis reveals group-specific vocal repertoire in long-finned pilot whales[J/OL]. arXiv: 1410.4711. arXiv(2014-10-17)[2026-04-16]. https://arxiv.org/abs/1410.4711. [15] Constantinescu C, Brad R. An overview of sound features in time and frequency domain[J/OL]. International Journal of Advanced Statistics and IT&C for Economics and Life Sciences, 2023, 13(1): 45-58. https://doi.org/10.2478/ijasitels-2023-0006. [16] Peeters G. A large set of audio features for sound description (similarity and classification) in the CUIDADO project[R]. Paris: IRCAM, 2004: 1-25. [17] Baumann-Pickering S, McDonald M A, Simonis A E, et al. Species-specific beaked whale echolocation signals[J]. The Journal of the Acoustical Society of America, 2013, 134(3): 2293-2301. doi: 10.1121/1.4817832 [18] He K, Chen X, Xie S, et al. Masked autoencoders are scalable vision learners[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022: 16000-16009. [19] Radford A, Metz L, Chintala S. Unsupervised representation learning with deep convolutional generative adversarial networks[PP/OL]. arXiv: 1511.06434v2. arXiv (2015-11-19)[2026-04-16]. https://arxiv.org/abs/1511.06434. [20] Gao S H, Cheng M M, Zhao K, et al. Res2net: A new multi-scale backbone architecture[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2019, 43(2): 652-662. -

 下载:
下载:


 点击查看大图
点击查看大图
计量
- 文章访问数: 161
- HTML全文浏览量: 87
- PDF下载量: 83
- 被引次数: 0