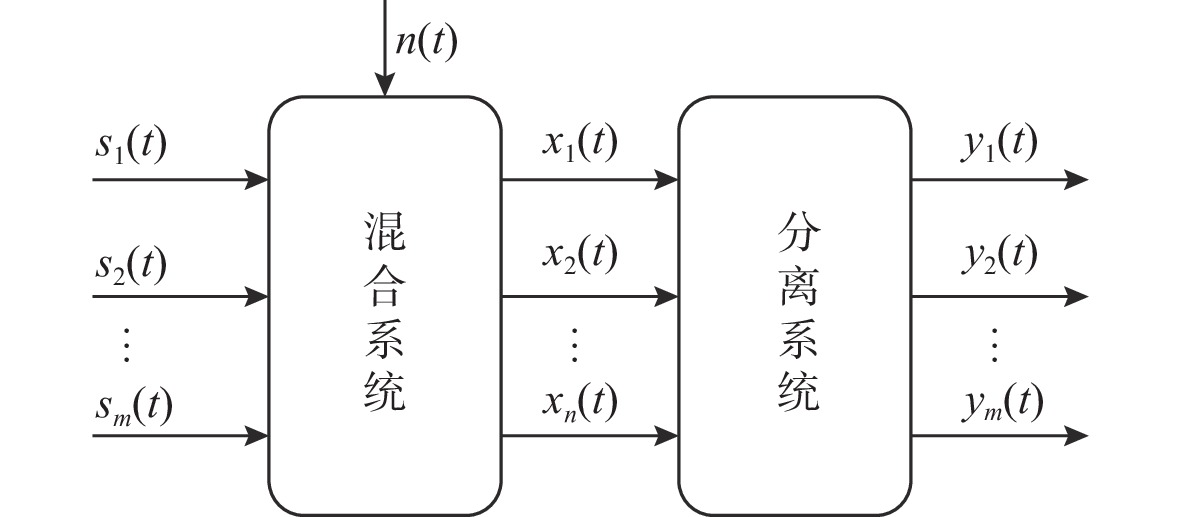
Marine Sound Separation Algorithm Based on Time-Frequency Interleaved Attention and Integrated Filtering Module
-
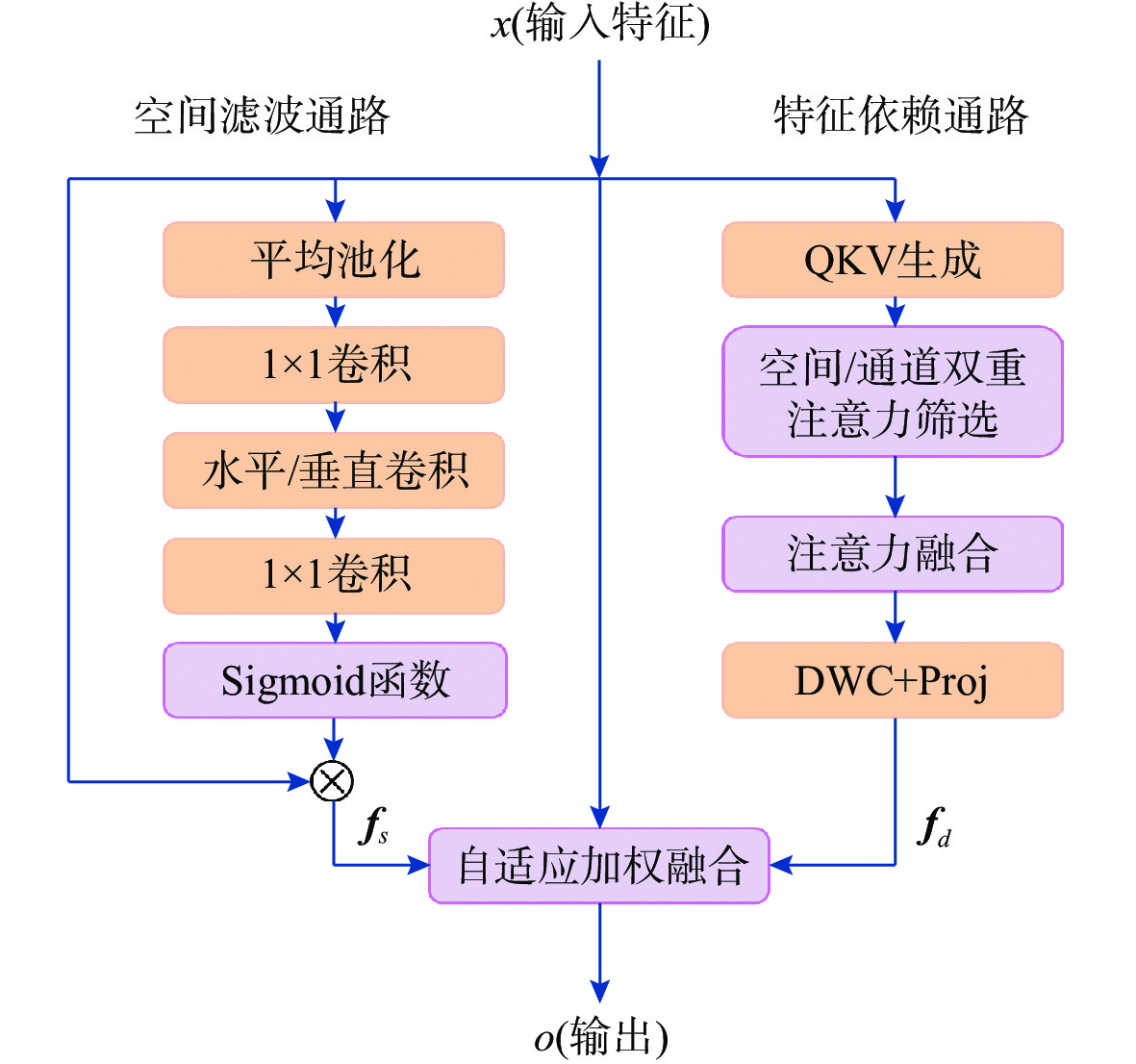
摘要: 针对复杂海洋声景与水下目标信号多变特性导致的声音特征精细化感知与分辨问题, 文中提出基于时频交错注意力与集成滤波模块(IFM)的海洋声音分离算法。采用频带划分策略, 使用编码器将混合音频转换至时频谱, 利用多尺度注意力机制交叉提取时频增益, 并通过IFM将多尺度卷积空间滤波、自注意力特征依赖通路所提取的特征与原始特征进行高效融合, 并将融合后的特征输入解码器以重建高质量的纯净目标音频, 在增强目标信号细节的同时有效滤除背景噪声和干扰。在海洋典型声音数据集上的实验结果表明, 文中所提算法能够显著提升目标音频分离性能, 在座头鲸与客船、虎鲸与客船的音频分离实验中, 源失真比改善量(SDRi)分别达到8.56 dB和10.74 dB, 各项性能指标均优于现有基线模型。Abstract: To address the problems of refined perception and discrimination of sound features caused by complex marine soundscapes and the variable characteristics of underwater target signals, this paper proposed a marine sound separation algorithm based on time-frequency interleaved attention and an integrated filtering module(IFM). The algorithm adopted a frequency band division strategy and used an encoder to convert the mixed audio into a time-frequency spectrogram. A multi-scale attention mechanism was utilized to cross-extract time-frequency gains. The IFM efficiently fused the features extracted from the multi-scale convolutional spatial filtering and the self-attention feature dependency pathway with the original features. The fused features were input into a decoder to reconstruct high-quality pure target audio, enhancing the details of the target signals while effectively filtering out background noise and interference. Experimental results on typical marine sound datasets show that the proposed algorithm significantly improves target audio separation performance. In audio separation experiments involving humpback whales mixed with passenger ships and killer whales mixed with passenger ships, the source-to-distortion ratio improvement(SDRi) reaches 8.56 dB and 10.74 dB, respectively, and all performance indicators are superior to those of existing baseline models.
-
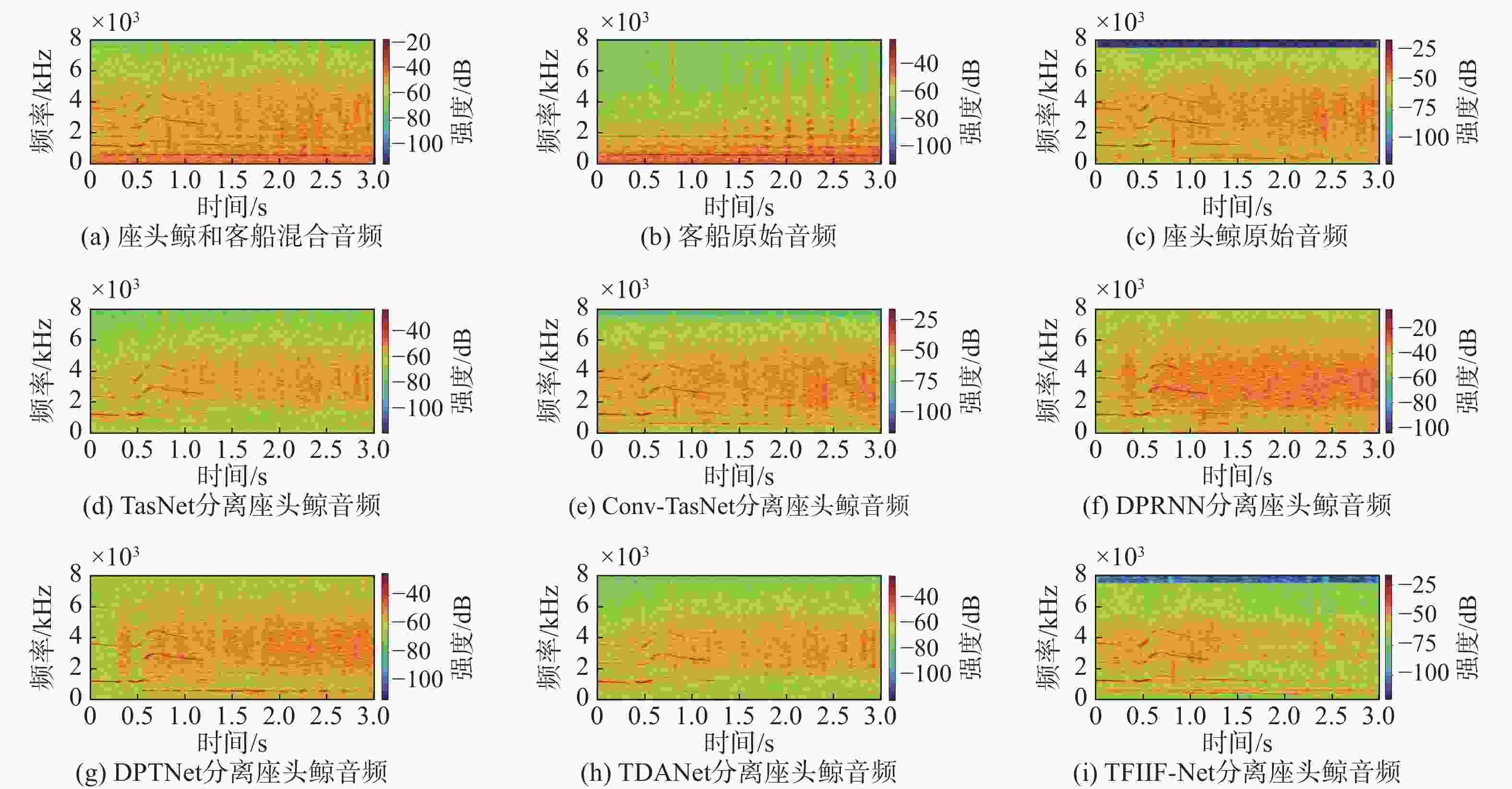
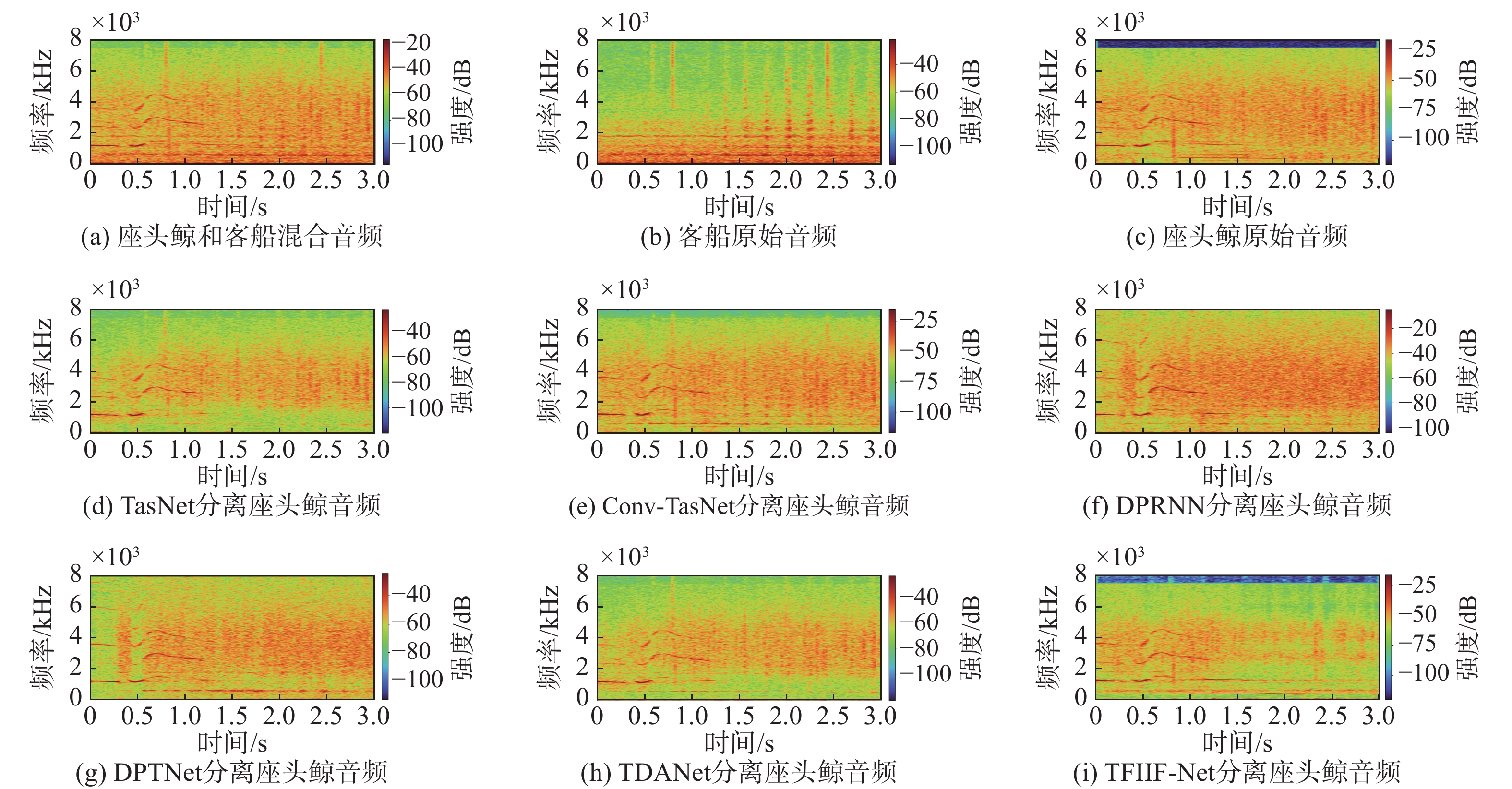
图 5 座头鲸音频分离结果时频谱图
Figure 5. Time-frequency spectrogram of humpback whale audio separation results
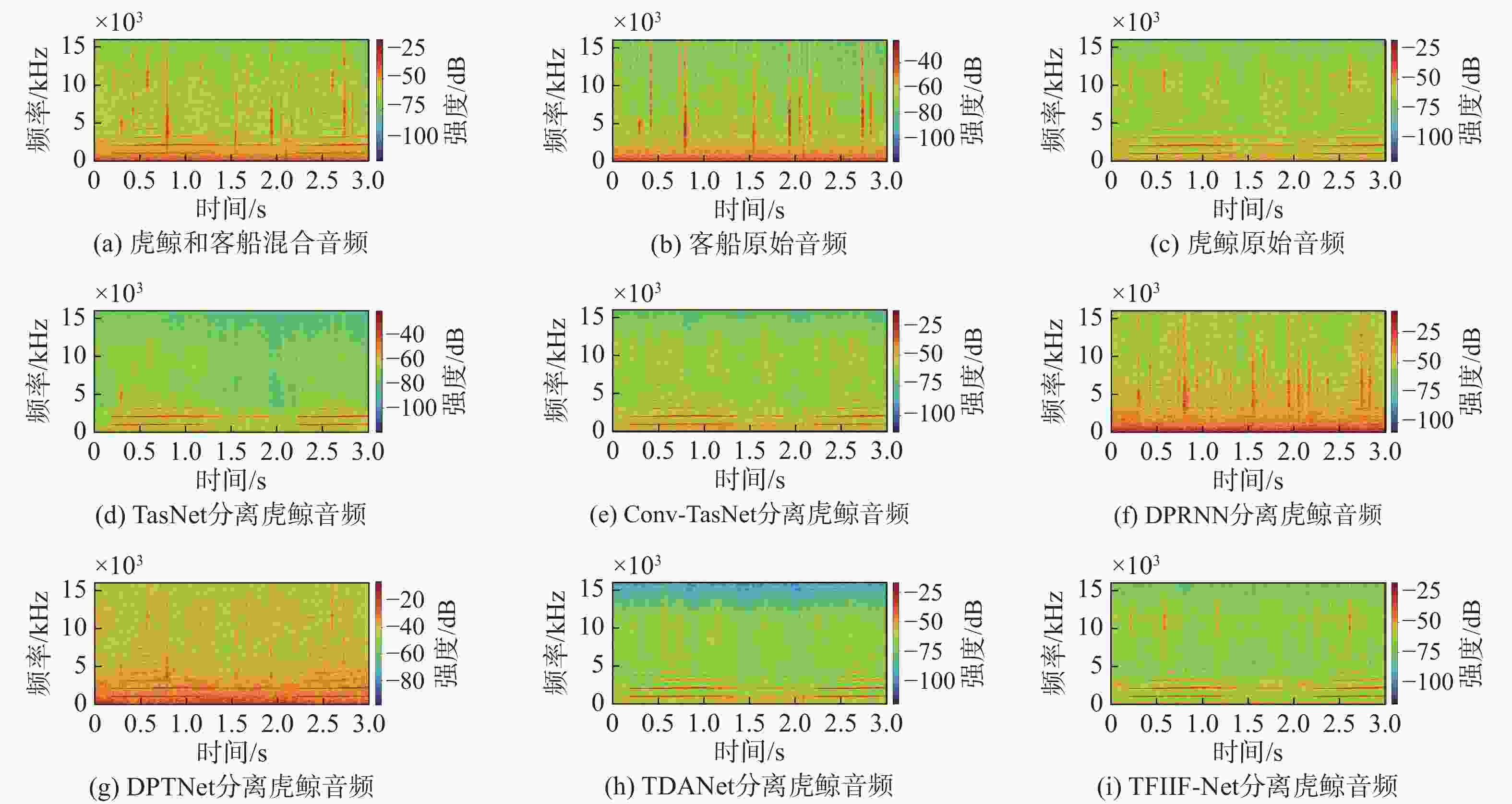
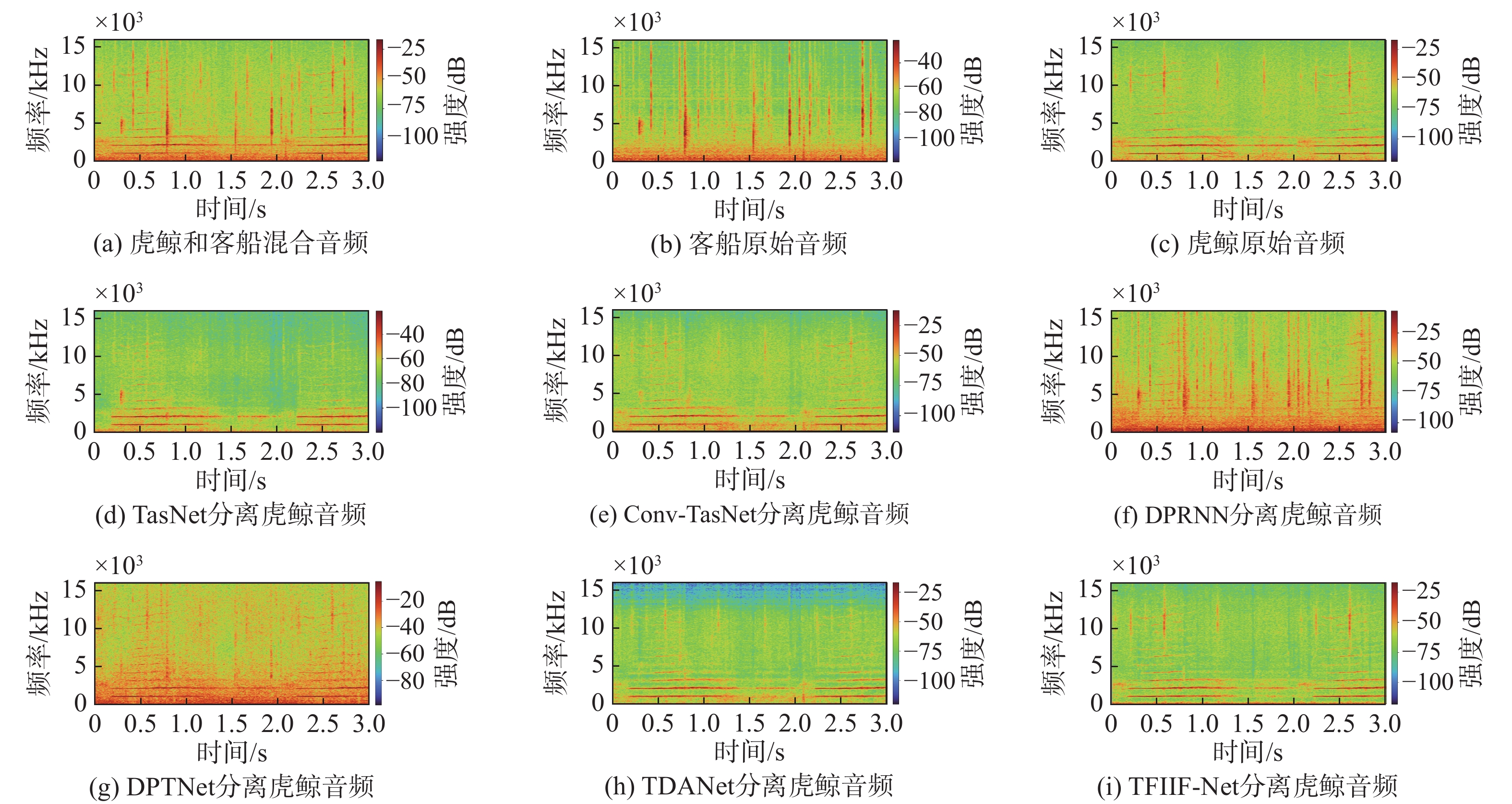
图 6 虎鲸音频分离结果时频谱图
Figure 6. Time-frequency spectrogram of killer whale audio separation results

图 7 真实海洋音频分离结果时频谱图
Figure 7. Time-frequency spectrograms of real marine audio separation results
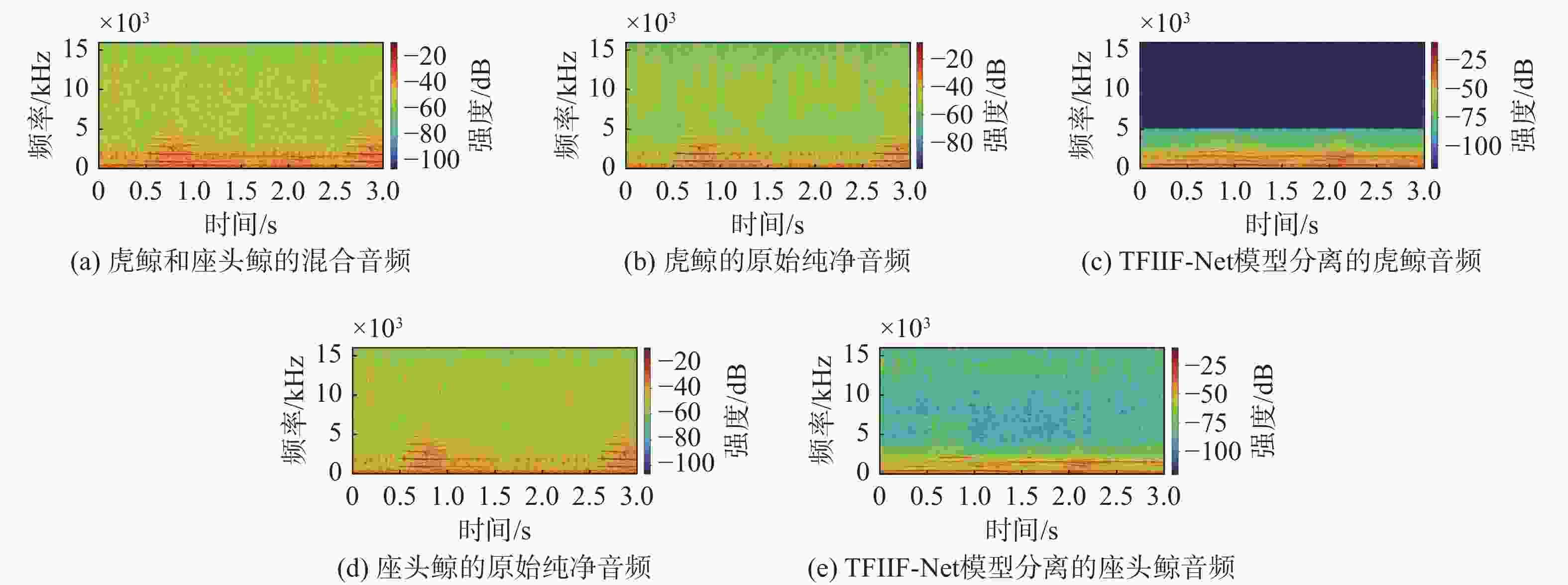
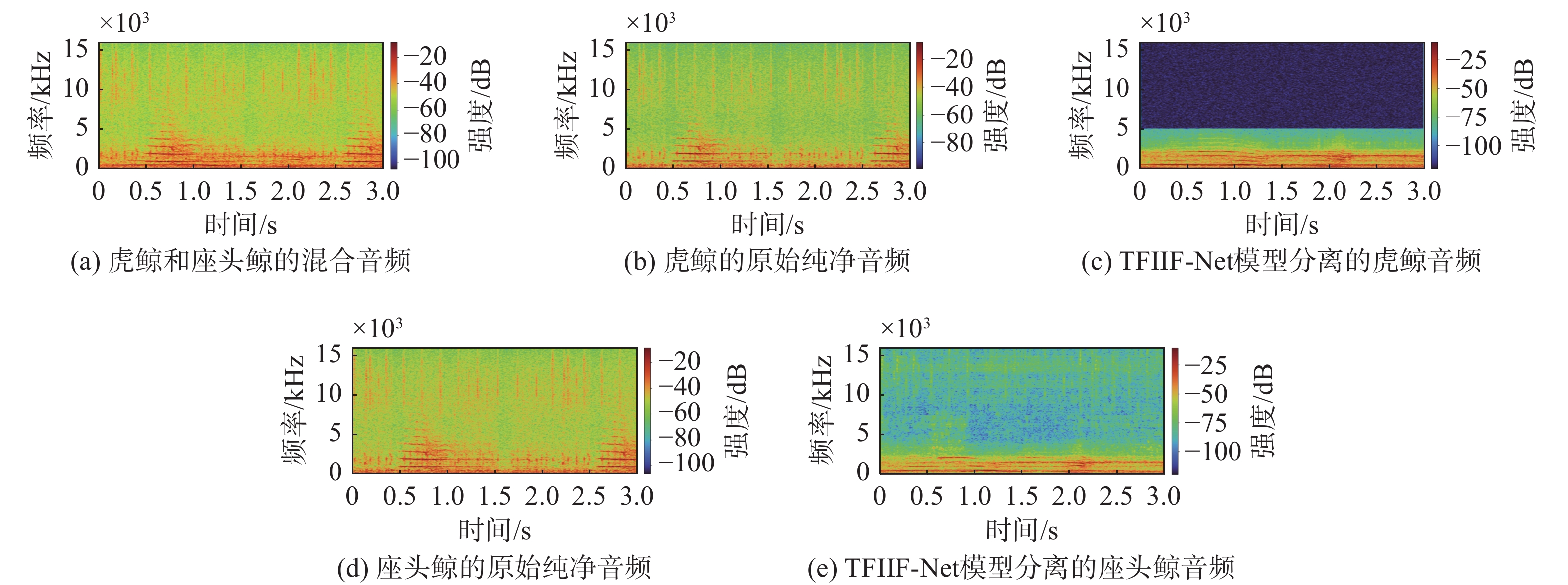
图 8 海洋生物音频分离结果时频谱图
Figure 8. Time-frequency spectrograms of audio separation results from marine organisms
表 1 音频分离模型性能指标对比实验
Table 1. Comparison of performance metrics of audio separation models experiment
实验类别 处理方法 SAR/dB SIR/dB SDR/dB SDRi/dB 实验1 Tas-Net 10.09 10.68 6.71 6.17 Conv-TasNet 11.34 11.84 7.96 7.42 DPRNN 11.33 12.76 8.32 7.78 DPTNet 11.43 11.03 7.63 7.09 TDANet 10.98 11.60 7.71 7.17 TFIIF-Net 11.98 13.32 9.10 8.56 实验2 TasNet 10.09 11.31 7.11 7.01 Conv-TasNet 11.63 13.58 9.04 8.94 DPRNN 11.04 13.44 8.59 8.49 DPTNet 7.11 6.10 2.28 2.18 TDANet 10.99 12.49 8.08 7.98 TFIIF-Net 12.80 16.21 10.84 10.74  下载: 导出CSV
下载: 导出CSV
表 2 消融实验结果
Table 2. Ablation experiment results
方法 SAR/dB SIR/dB SDR/dB SDRi/dB Base 11.83 13.18 8.97 8.43 Spatial 11.95 13.30 9.06 8.52 Feature 11.93 12.83 8.84 8.30 Equalweight 12.68 11.55 8.67 8.13 TFIIF-Net 11.98 13.32 9.10 8.56
下载: 导出CSV
-
[1] BAYRAKCI G, KLINGELHOEFER F. An introduction to the ocean soundscape[M]. Hoboken, Noisy Oceans: Monitoring Seismic and Acoustic Signals in the Marine Environment, Wiley, 2024. [2] DUARTE C M, CHAPUIS L, COLLIN S P, et al. The soundscape of the Anthropocene ocean[J]. Science, 2021, 371(6529): eaba4658. doi: 10.1126/science.aba4658 [3] LI D, WU M, YU L, et al. Single-channel blind source separation of underwater acoustic signals using improved NMF and FastICA[J]. Frontiers in Marine Science, 2023, 9: 1097003. doi: 10.3389/fmars.2022.1097003 [4] 谢加武. 基于深度学习的水下声源分离技术研究[D]. 成都: 电子科技大学, 2019. [5] WANG M, ZHANG W, SHAO M, et al. Separation and extraction of compound-fault signal based on multi-constraint non-negative Matrix factorization[J]. Entropy, 2024, 26(7): 583. doi: 10.3390/e26070583 [6] SCHULZE F K, RICHARD G, KELLEY L, et al. Unsupervised music source separation using differentiable parametric source models[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2023, 31: 1276-1289. doi: 10.1109/TASLP.2023.3252272 [7] ANSARI S, ALATRANY A S, ALNAJJAR K A, et al. A survey of artificial intelligence approaches in blind source separation[J]. Neurocomputing, 2023, 561: 126895. doi: 10.1016/j.neucom.2023.126895 [8] CHANDNA P, CUESTA H, PETERMANN D, et al. A deep-learning based framework for source separation, analysis, and synthesis of choral ensembles[J]. Frontiers in Signal Processing, 2022, 2: 808594. doi: 10.3389/frsip.2022.808594 [9] LUO Y, MESGARANI N. Tasnet: time-domain audio separation network for real-time, single-channel speech separation[C]//2018 IEEE International Conference on Acoustics, Speech and Signal Processing(ICASSP). Calgary, AB, Canada: IEEE, 2018: 696-700. [10] LUO Y, MESGARANI N. Conv-tasnet: Surpassing ideal time–frequency magnitude masking for speech separation[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2019, 27(8): 1256-1266. doi: 10.1109/TASLP.2019.2915167 [11] LUO Y, CHEN Z, YOSHIOKA T. Dual-path RNN: Efficient long sequence modeling for time-domain single-channel speech separation[C]//ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing(ICASSP). Barcelona, Spain: IEEE, 2020: 46-50. [12] CHEN J, MAO Q, LIU D. Dual-path transformer network: Direct context-aware modeling for end-to-end monaural speech separation[EB/OL]. [2025-11-25]. https://arxiv.org/abs/2007.13975. [13] VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[J]. Advances in Neural Information Processing Systems, 2017(30): 5998-6008. [14] ZHANG W, LI X, ZHOU A, et al. Underwater acoustic source separation with deep Bi-LSTM networks[C]//2021 4th International Conference on Information Communication and Signal Processing(ICICSP). Shanghai, China: IEEE, 2021: 254-258. [15] HE Q, WANG H, ZENG X, et al. Ship-radiated noise separation in underwater acoustic environments using a deep time-domain network[J]. Journal of Marine Science and Engineering, 2024, 12(6): 885. doi: 10.3390/jmse12060885 [16] LIU Y, JIANG L. Passive underwater acoustic signal separation based on feature decoupling dual-path network[EB/OL]. [2025-09-25]. https://arxiv.org/abs/2504.08371. [17] XU M, LI K, CHEN G, et al. Tiger: Time-frequency interleaved gain extraction and reconstruction for efficient speech separation[EB/OL]. [2025-09-25]. https://arxiv.org/abs/2410.01469. [18] SAYIGH L, DAHER M A, ALLEN J, et al. The Watkins marine mammal sound database: An online, freely accessible resource[C]//Proceedings of Meetings on Acoustics. Acoustical Society of America. Dublin, Ireland: POMA, 2016: 040013. [19] SANTOS-DOMÍNGUEZ D, TORRES-GUIJARRO S, CARDENAL-LÓPEZ A, et al. ShipsEar: An underwater vessel noise database[J]. Applied Acoustics, 2016, 113: 64-69. doi: 10.1016/j.apacoust.2016.06.008 [20] YUREN B. Research on music source separation technology based on deep learning[J]. Computer Science and Application, 2022, 12: 2788. doi: 10.12677/CSA.2022.1212283 -

 下载:
下载:




 点击查看大图
点击查看大图
计量
- 文章访问数: 324
- HTML全文浏览量: 144
- PDF下载量: 158
- 被引次数: 0