

A Review of Research on Path Planning of Unmanned Surface Vessel Swarm: Deep Reinforcement Learning
-
摘要: 无人艇(USV)集群在复杂海洋任务中展现出显著优势, 但其路径规划面临高维、动态以及多约束等挑战。传统路径规划算法因协同机制薄弱与适应性不足, 难以满足日渐复杂的需求, 而深度强化学习(DRL)技术的发展为USV集群路径规划提供了新的研究方向。文中系统综述了基于DRL的USV集群协同路径规划技术框架及典型算法。首先, 梳理了USV集群路径规划的技术演进脉络与多维约束条件, 分析了集中式和分布式决策框架的适用场景与局限性; 其次, 探讨了多种典型DRL算法的原理、应用场景及改进方向, 分析了其优势与不足; 最后, 总结了该领域面临的主要挑战和发展方向, 旨在为基于DRL的USV集群协同路径规划研究提供参考。Abstract: An unmanned surface vessel(USV) swarm has shown significant advantages in complex marine missions, but its path planning faces high-dimensional, dynamic, and multi-constraint challenges. Traditional path planning algorithms are difficult to meet increasingly complex needs due to weak coordination mechanisms and insufficient adaptability, while the development of deep reinforcement learning(DRL) technology provides a new research direction for the path planning of USV swarms. This paper systematically reviewed the technical framework and typical algorithms for collaborative path planning of USV swarms based on DRL. Firstly, the technical evolution context and multi-dimensional constraints of path planning of USV swarms were sorted out, and the applicable scenarios and limitations of centralized and distributed decision frameworks were analyzed. Secondly, the principle, application scenarios, and improvement directions of various typical DRL algorithms were discussed, and their advantages and disadvantages were analyzed. Finally, the main challenges and development directions in this field were summarized. This paper aims to provide a reference for the research on DRL-based collaborative path planning of USV swarms.
-
表 1 集中式与分布式决策框架特点对比
Table 1. Comparison of features between centralized and distributed decision-making frameworks
对比维度 集中式 分布式 可靠性 单一中心节点统一决策, 故障风险高 多节点自主决策, 容错性高 扩展性 扩展困难, 需重构中心架构 扩展灵活, 通过增加节点实现扩展 通信需求 各USV与中心节点频繁交互, 需具有足够的通信带宽 节点间通信, 需协调调度 优化能力 基于全局状态可获取全局最优解 基于局部状态获取局部最优解 资源消耗 中心节点计算、存储压力较大 计算分散至各节点, 负载均衡  下载: 导出CSV
下载: 导出CSV
表 2 集中式与分布式决策框架应用
Table 2. Centralized and distributed decision framework applications
下载: 导出CSV
表 3 基于不同DRL典型算法的USV集群路径规划特点
Table 3. Characteristics of USV swarm path planning based on different typical DRL algorithms
下载: 导出CSV
-
[1] 孙峰. 一种基于海空无人集群的自杀式无人艇防御策略[J]. 水下无人系统学报, 2024, 32(2): 267-274, 319.SUN F. Defense strategy for suicide unmanned surface vessels based on sea and air unmanned clusters[J]. Journal of Unmanned Undersea Systems, 2024, 32(2): 267-274, 319. [2] 翁磊, 杨扬, 钟雨轩. 多无人艇协同遍历路径规划算法[J]. 水下无人系统学报, 2020, 28(6): 634-641.WENG L, YANG Y, ZHONG Y X. Collaborative traversal path planning algorithm of for multiple unmanned survey vessels[J]. Journal of Unmanned Undersea Systems, 2020, 28(6): 634-641. [3] 王宁, 刘永金, 高颖. 未知扰动下的无人艇编队优化轨迹跟踪控制[J]. 中国舰船研究, 2024, 19(1): 178-190.WANG N, LIU Y J, GAO Y. Optimal trajectory tracking control of unmanned surface vehicle formation under unknown disturbances[J]. Chinese Journal of Ship Research, 2024, 19(1): 178-190. [4] 王秀玲, 尹勇, 赵延杰, 等. 无人艇海上搜救路径规划技术综述[J]. 船舶工程, 2023, 45(4): 50-57.WANG X L, YIN Y, ZHAO Y J, et al. Overview of USV maritime search and rescue path planning technology[J]. Ship Engineering, 2023, 45(4): 50-57. [5] 焦宇航, 王宁. 欠驱动无人船集群有限时间跟踪控制[J]. 中国舰船研究, 2023, 18(6): 76-87.JIAO Y H, WANG N. Finite-time trajectory tracking control of underactuated surface vehicles swarm[J]. Chinese Journal of Ship Research, 2023, 18(6): 76-87. [6] WANG N, HE H, HOU Y, et al. Model-free visual servo swarming of manned-unmanned surface vehicles with visibility maintenance and collision avoidance[J]. IEEE Transactions on Intelligent Transportation Systems, 2024, 25(1): 697-709. doi: 10.1109/TITS.2023.3310430 [7] WANG N, LIU Y, LIU J, et al. Reinforcement learning swarm of self-organizing unmanned surface vehicles with unavailable dynamics[J]. Ocean Engineering, 2023, 289: 116313. doi: 10.1016/j.oceaneng.2023.116313 [8] NIU Y, MU Y, ZHANG K, et al. Path planning and search effectiveness of USV based on underwater target scattering model[J]. Journal of Physics: Conference Series, 2023, 2478(10): 102035. [9] MA Y, ZHAO Y, LI Z, et al. CCIBA*: An improved BA* based collaborative coverage path planning method for multiple unmanned surface mapping vehicles[J]. IEEE Transactions on Intelligent Transportation Systems, 2022, 23(10): 19578-88. doi: 10.1109/TITS.2022.3170322 [10] XUE K, HUANG Z, WANG P, et al. An exact algorithm for task allocation of multiple unmanned surface vehicles with minimum task time[J]. Journal of Marine Science and Engineering, 2021, 9(8): 907. doi: 10.3390/jmse9080907 [11] 刘祥, 叶晓明, 王泉斌, 等. 无人水面艇局部路径规划算法研究综述[J]. 中国舰船研究, 2021, 16(z1): 1-10.LIU X, YE X M, WANG Q B, et al. Review on the research of local path planning algorithms for unmanned surface vehicles[J]. Chinese Journal of Ship Research, 2021, 16(z1): 1-10. [12] LIN X, LIU Y. Research on multi-USV cooperative search method[C]//2019 IEEE International Conference on Mechatronics and Automation. Tianjin, China: IEEE, 2019. [13] 徐善文, 曾庆化, 李方东, 等. 无人集群系统协同导航资源及算法综述[J]. 导航与控制, 2024, 23(5): 25-37.XU S W, ZENG Q H, LI F D, et al. A review of cooperative navigation resources and algorithms for unmanned swarm systems[J]. Navigation and Control, 2024, 23(5): 25-37. [14] WANG H, FU Z, ZHOU J, et al. Cooperative collision avoidance for unmanned surface vehicles based on improved genetic algorithm[J]. Ocean Engineering, 2021, 222: 108612. doi: 10.1016/j.oceaneng.2021.108612 [15] ZHAO L, BAI Y, PAIK J K. Global path planning and waypoint following for heterogeneous unmanned surface vehicles assisting inland water monitoring[J]. Journal of Ocean Engineering and Science, 2023, 10(1): 88-108. [16] MENG X, SUN B, ZHU D. Harbour protection: Moving invasion target interception for multi-AUV based on prediction planning interception method[J]. Ocean Engineering, 2021, 219: 108268. doi: 10.1016/j.oceaneng.2020.108268 [17] GAN W, QU X, SONG D, et al. Multi-USV cooperative chasing strategy based on obstacles assistance and deep reinforcement learning[J]. IEEE Transactions on Automation Science and Engineering, 2023, 21(4): 5895-910. [18] YAN X, JIANG D, MIAO R, et al. Formation control and obstacle avoidance algorithm of a multi-USV system based on virtual structure and artificial potential field[J]. Journal of Marine Science and Engineering, 2021, 9(2): 161. doi: 10.3390/jmse9020161 [19] 欧阳子路, 王鸿东, 黄一, 等. 基于改进RRT算法的无人艇编队路径规划技术[J]. 中国舰船研究, 2020, 15(3): 18-24.OUYANG Z L, WANG H D, HUANG Y, et al. Path planning technologies for USV formation based on improved RRT[J]. Chinese Journal of Ship Research, 2020, 15(3): 18-24. [20] LI Y, ZHANG J, LI Y, et al. Research on the frame of formation of multi-USV[C]//2022 5th World Conference on Mechanical Engineering and Intelligent Manufacturing(WCMEIM). Ma’anshan, China: IEEE, 2022: 746-749. [21] SANG T, XIAO J, XIONG J, et al. Path planning method of unmanned surface vehicles formation based on improved A* algorithm[J]. Journal of Marine Science and Engineering, 2023, 11(1): 176. doi: 10.3390/jmse11010176 [22] 宋利飞, 徐凯凯, 史晓骞, 等. 多无人艇协同围捕智能逃跑目标方法研究[J]. 中国舰船研究, 2023, 18(1): 52-59.SONG L F, XU K K, SHI X Q, et al. Multiple USV cooperative algorithm method for hunting intelligent escaped targets[J]. Chinese Journal of Ship Research, 2023, 18(1): 52-59. [23] SANG H, YOU Y, SUN X, et al. The hybrid path planning algorithm based on improved A* and artificial potential field for unmanned surface vehicle formations[J]. Ocean Engineering, 2021, 223: 108709. doi: 10.1016/j.oceaneng.2021.108709 [24] YU J, CHEN Z, ZHAO Z, et al. A traversal multi-target path planning method for multi-unmanned surface vessels in space-varying ocean current[J]. Ocean Engineering, 2023, 278: 114423. doi: 10.1016/j.oceaneng.2023.114423 [25] SHARMA A, SHOVAL S, SHARMA A, et al. Path planning for multiple targets interception by the swarm of UAVs based on swarm intelligence algorithms: A review[J]. IETE Technical Review, 2022, 39(3): 675-697. doi: 10.1080/02564602.2021.1894250 [26] NAZARAHARI M, KHANMIRZA E, DOOSTIE S. Multi-objective multi-robot path planning in continuous environment using an enhanced genetic algorithm[J]. Expert Systems with Applications, 2019, 115: 106-120. doi: 10.1016/j.eswa.2018.08.008 [27] LUO Q, YAN X, WU D, et al. Unmanned surface vehicle cooperative task assignment based on genetic algorithm[C]//2022 Global Reliability and Prognostics and Health Management. Yantai, China: IEEE, 2022: 1-5. [28] YAO P, WU K, LOU Y. Path planning for multiple unmanned surface vehicles using Glasius bio-inspired neural network with Hungarian algorithm[J]. IEEE Systems Journal, 2022, 17(3): 3906-17. [29] TANG F. Coverage path planning of unmanned surface vehicle based on improved biological inspired neural network[J]. Ocean Engineering, 2023, 278: 114354. doi: 10.1016/j.oceaneng.2023.114354 [30] ZHAI H, WANG W, ZHANG W, et al. Path planning algorithms for USVs via deep reinforcement learning[C]//2021 China Automation Congress. Beijing, China: IEEE, 2021: 4281-86. [31] YANG C, ZHAO Y, CAI X, et al. Path planning algorithm for unmanned surface vessel based on multi-objective reinforcement learning[J]. Computational Intelligence and Neuroscience, 2023, 2023(1): 2146314. doi: 10.1155/2023/2146314 [32] CHEN C, CHEN X Q, MA F, et al. A knowledge-free path planning approach for smart ships based on reinforcement learning[J]. Ocean Engineering, 2019, 189: 106299. doi: 10.1016/j.oceaneng.2019.106299 [33] ZHAO Y, MA Y, HU S. USV formation and path-following control via deep reinforcement learning with random braking[J]. IEEE Transactions on Neural Networks and Learning Systems, 2021, 32(12): 5468-78. doi: 10.1109/TNNLS.2021.3068762 [34] LUIS S Y, REINA D G, MARÍN S L T. A multiagent deep reinforcement learning approach for path planning in autonomous surface vehicles: The Ypacaraí lake patrolling case[J]. IEEE Access, 2021, 9: 17084-99. doi: 10.1109/ACCESS.2021.3053348 [35] 彭周华, 吴文涛, 王丹, 等. 多无人艇集群协同控制研究进展与未来趋势[J]. 中国舰船研究, 2021, 16(1): 51-64.PENG Z H, WU W T, WANG D, et al. Coordinated control of multiple unmanned surface vehicles: Recent advances and future trends[J]. Chinese Journal of Ship Research, 2021, 16(1): 51-64. [36] LIU Y, CHEN C, QU D, et al. Multi-USV system antidisturbance cooperative searching based on the reinforcement learning method[J]. IEEE Journal of Oceanic Engineering, 2023, 48(4): 1019-47. doi: 10.1109/JOE.2023.3281630 [37] ZHANG J, REN J, CUI Y, et al. Multi-USV task planning method based on improved deep reinforcement learning[J]. IEEE Internet of Things Journal, 2024, 11(10): 18549-67. doi: 10.1109/JIOT.2024.3363044 [38] LI Y, LI X, WEI X, et al. Sim-real joint experimental verification for an unmanned surface vehicle formation strategy based on multi-agent deterministic policy gradient and line of sight guidance[J]. Ocean Engineering, 2023, 270: 113661. doi: 10.1016/j.oceaneng.2023.113661 [39] WANG C C, WANG Y L, HAN Q L, et al. Multi-USV cooperative formation control via deep reinforcement learning with deceleration[EB/OL]. [2024-12-06]. https://ieeexplore.ieee.org/document/10621696. [40] WANG C, WANG Y, SHI P, et al. Scalable-MADDPG-based cooperative target invasion for a multi-USV system[J]. IEEE Transactions on Neural Networks and Learning Systems, 2023, 35(12): 17867-77. [41] WEI X, WANG H, TANG Y. Deep hierarchical reinforcement learning based formation planning for multiple unmanned surface vehicles with experimental results[J]. Ocean Engineering, 2023, 286: 115577. doi: 10.1016/j.oceaneng.2023.115577 [42] JIN K, WANG J, WANG H, et al. Soft formation control for unmanned surface vehicles under environmental disturbance using multi-task reinforcement learning[J]. Ocean Engineering, 2022, 260: 112035. doi: 10.1016/j.oceaneng.2022.112035 [43] 任璐, 柯亚男, 柳文章, 等. 基于优势函数输入扰动的多无人艇协同策略优化方法[J]. 自动化学报, 2024, 51(4): 1-11.REN L, KE Y N, LIU W Z, et al. Multi-USVs cooperative policy optimization method based on disturbed input of advantage function[J]. Acta Automatica Sinica, 2025, 51(4): 1-11. [44] YAO P, LOU Y, WU K. Cooperative path planning for USVs assembly task[C]//2023 38th Youth Academic Annual Conference of Chinese Association of Automation (YAC). Hefei, China: IEEE, 2023: 526-531. [45] 于长东, 刘新阳, 陈聪, 等. 基于多智能体深度强化学习的无人艇集群博弈对抗研究[J]. 水下无人系统学报, 2024, 32(1): 79-86. doi: 10.11993/j.issn.2096-3920.2023-0159YU C D, LIU X Y, CHEN C, et al. Research on game confrontation of unmanned surface vehicles swarm based on multi-agent deep reinforcement learning[J]. Journal of Unmanned Undersea Systems, 2024, 32(1): 79-86. doi: 10.11993/j.issn.2096-3920.2023-0159 [46] LI F, YIN M, WANG T, et al. Distributed pursuit-evasion game of limited perception USV swarm based on multiagent proximal policy optimization[J]. IEEE Transactions on Systems, Man, and Cybernetics: Systems, 2024, 54(10): 6435-46. doi: 10.1109/TSMC.2024.3429467 [47] XIA J, LUO Y, LIU Z, et al. Cooperative multi-target hunting by unmanned surface vehicles based on multi-agent reinforcement learning[J]. Defence Technology, 2023, 29: 80-94. doi: 10.1016/j.dt.2022.09.014 [48] QU X, GAN W, SONG D, et al. Pursuit-evasion game strategy of USV based on deep reinforcement learning in complex multi-obstacle environment[J]. Ocean Engineering, 2023, 273: 114016. doi: 10.1016/j.oceaneng.2023.114016 [49] LOWE R, WU Y I, TAMAR A, et al. Multi-agent actor-critic for mixed cooperative-competitive environments [C]//NIPS'17: Proceedings of the 31st International Conference on Neural Information Processing Systems. Long Beach, USA: ACM, 2017: 6383-93. [50] REYNOLDS C W. Flocks, herds and schools: A distributed behavioral model[C]//Proceedings of the 14th annual conference on Computer graphics and interactive techniques. [S.l.]: Publication History, 1987: 25-34. [51] WANG Z, JIN X, ZHANG T, et al. Expert system-based multiagent deep deterministic policy gradient for swarm robot decision making[J]. IEEE Transactions on Cybernetics, 2022, 54(3): 1614-24. [52] SCHULMAN J, WOLSKI F, DHARIWAL P, et al. Proximal policy optimization algorithms[EB/OL]. [2025-02-20]. https://arxiv.org/abs/1707.06347. [53] XUE D, WU D, YAMASHITA A S, et al. Proximal policy optimization with reciprocal velocity obstacle based collision avoidance path planning for multi-unmanned surface vehicles[J]. Ocean Engineering, 2023, 273: 114005. doi: 10.1016/j.oceaneng.2023.114005 -

 下载:
下载:

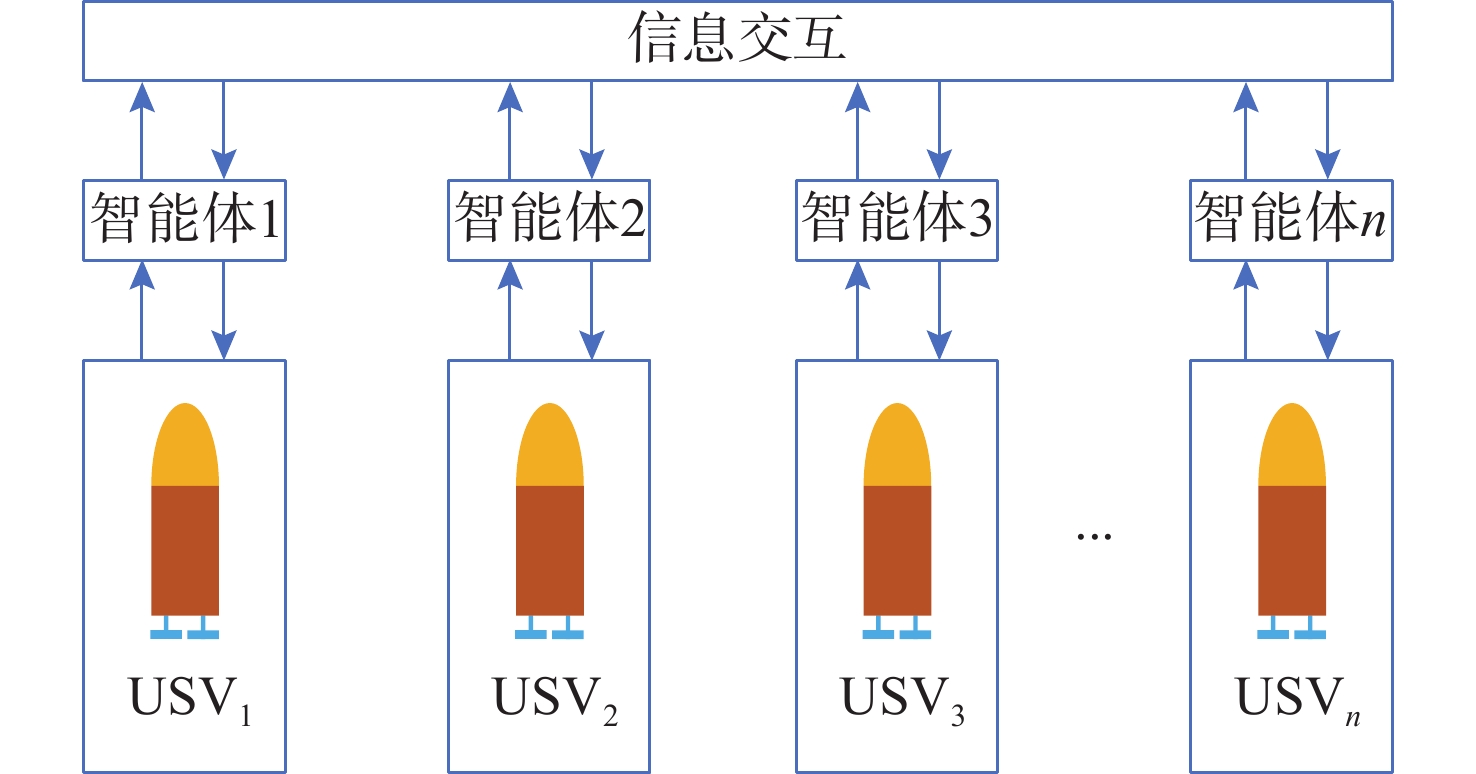
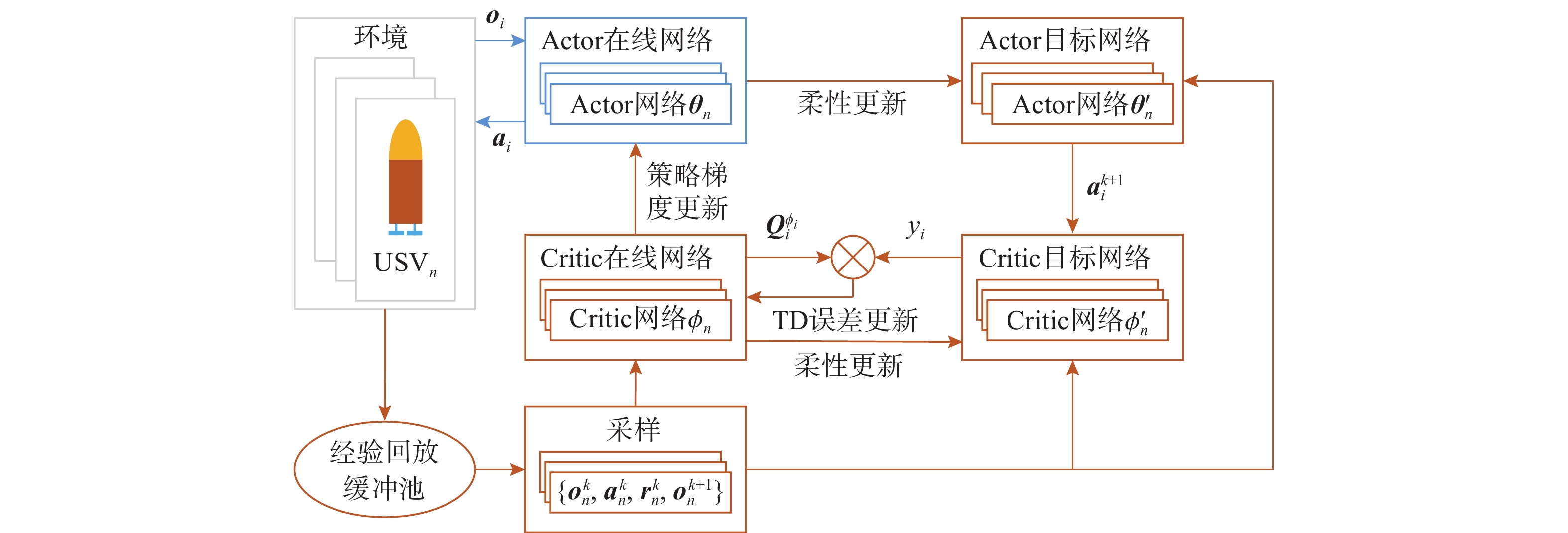
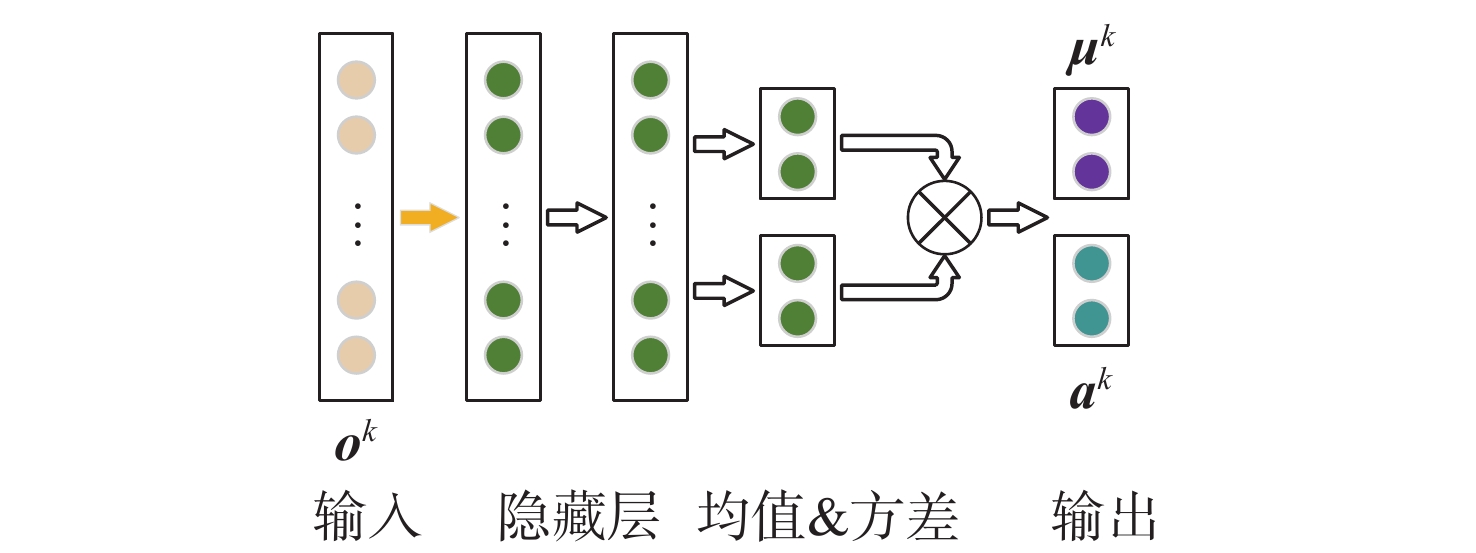

 点击查看大图
点击查看大图
计量
- 文章访问数: 2422
- HTML全文浏览量: 713
- PDF下载量: 346
- 被引次数: 0

图(5) / 表(3)




