

MARL-TS Method for Underwater Acoustic Networks in Time-Varying Channels
-
摘要: 水声通信因其高传播时延、信道时变特性及带宽受限等因素, 在传输调度决策方面面临诸多挑战。为提升复杂水声环境下的通信效率, 文中提出了一种基于多智能体强化学习(MARL)的水声网络跨层传输调度(TS)方法MARL-TS。该方法针对高水声传播时延和动态信道环境, 以传输节点的数据缓存状态与信道条件为基础, 以通信网络的传输效率和传输时延为优化目标, 自适应地进行跨层优化, 实现功率分配与时隙资源调度的联合优化。为学习最优传输策略, 文中构建了可学习的策略网络与价值网络, 并结合多智能体协同学习, 提升策略优化的效率与自适应决策能力。仿真实验表明, 与现有基于强化学习的多路访问控制协议相比, MARL-TS在传输能效优化和传输时延降低等方面表现出显著优势, 尤其在多节点高负载场景下展现了更强的适应性与稳定性, 为复杂水下通信系统的优化提供了新思路。Abstract: Underwater acoustic communication faces numerous challenges in transmission scheduling and decision-making due to its high propagation delay, time-varying channel characteristics, and limited bandwidth. To enhance communication efficiency in complex underwater acoustic environments, this paper proposed a multi-agent reinforcement learning(MARL)-based cross-layer transmission scheduling(TS) method for underwater acoustic networks, termed MARL-TS. This method addressed the high propagation delay and dynamic channel environments by leveraging transmission node buffer states and channel conditions as the foundation while optimizing transmission efficiency and transmission delay of the communication network. It adaptively performs cross-layer optimization to jointly optimize power allocation and timeslot resource scheduling. To learn the optimal transmission strategy, this paper constructed a learnable policy network and a value network, integrating multi-agent cooperative learning to improve strategy optimization efficiency and adaptive decision-making capabilities. Simulation results demonstrate that compared with existing reinforcement learning-based multiple access control(MAC) protocols, MARL-TS significantly enhances transmission efficiency and reduces transmission delay. Notably, it exhibits superior adaptability and stability in multi-node and high-load scenarios, offering a novel approach for optimizing complex underwater communication systems.
-
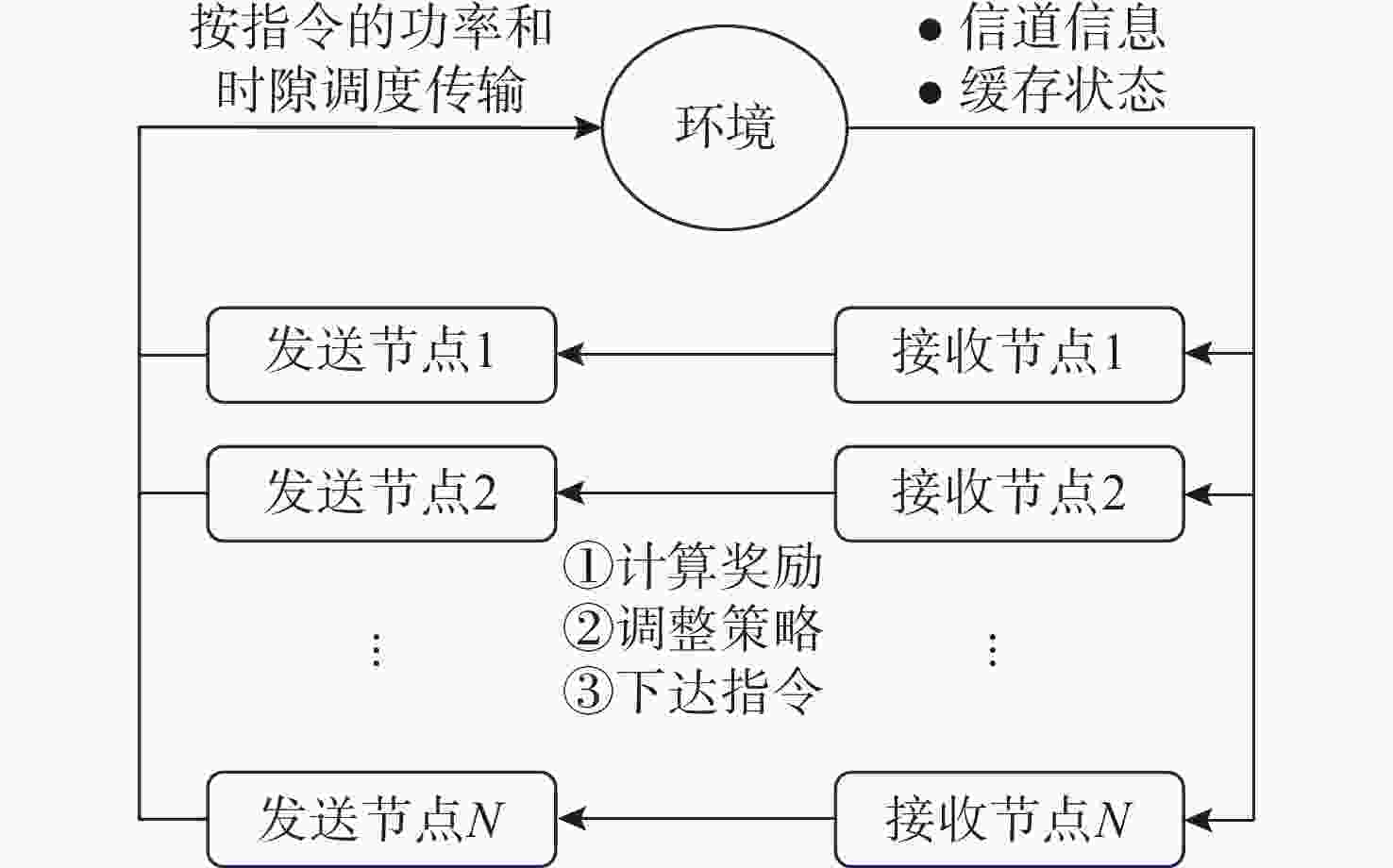
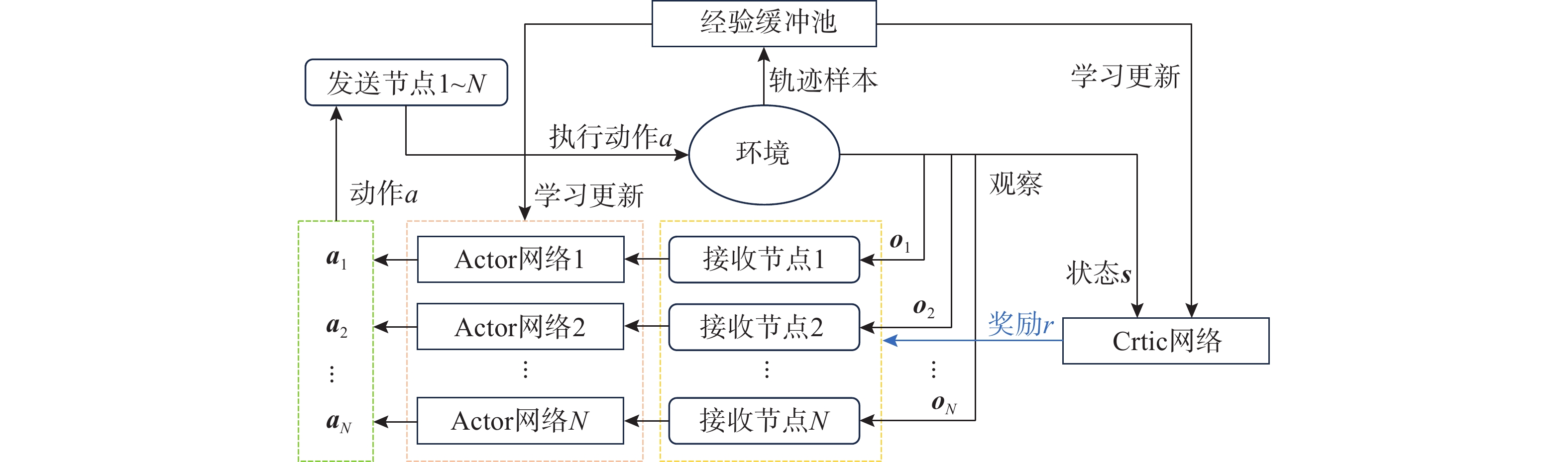
图 3 MARL-TS协议中多智能体与环境交互示意图
Figure 3. Schematic diagram of the interaction between multiple agents and the environment in the MARL-TS protocol
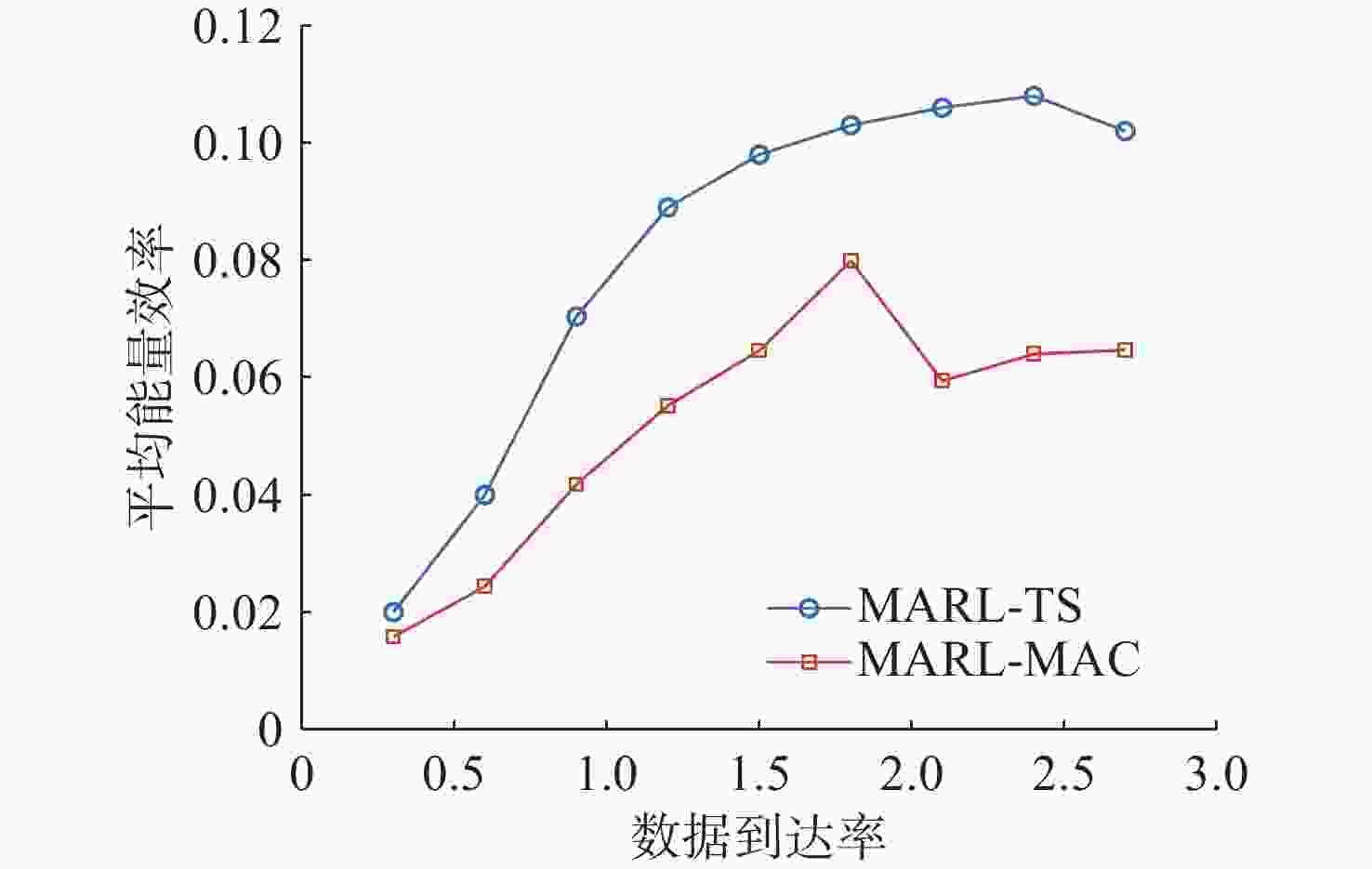
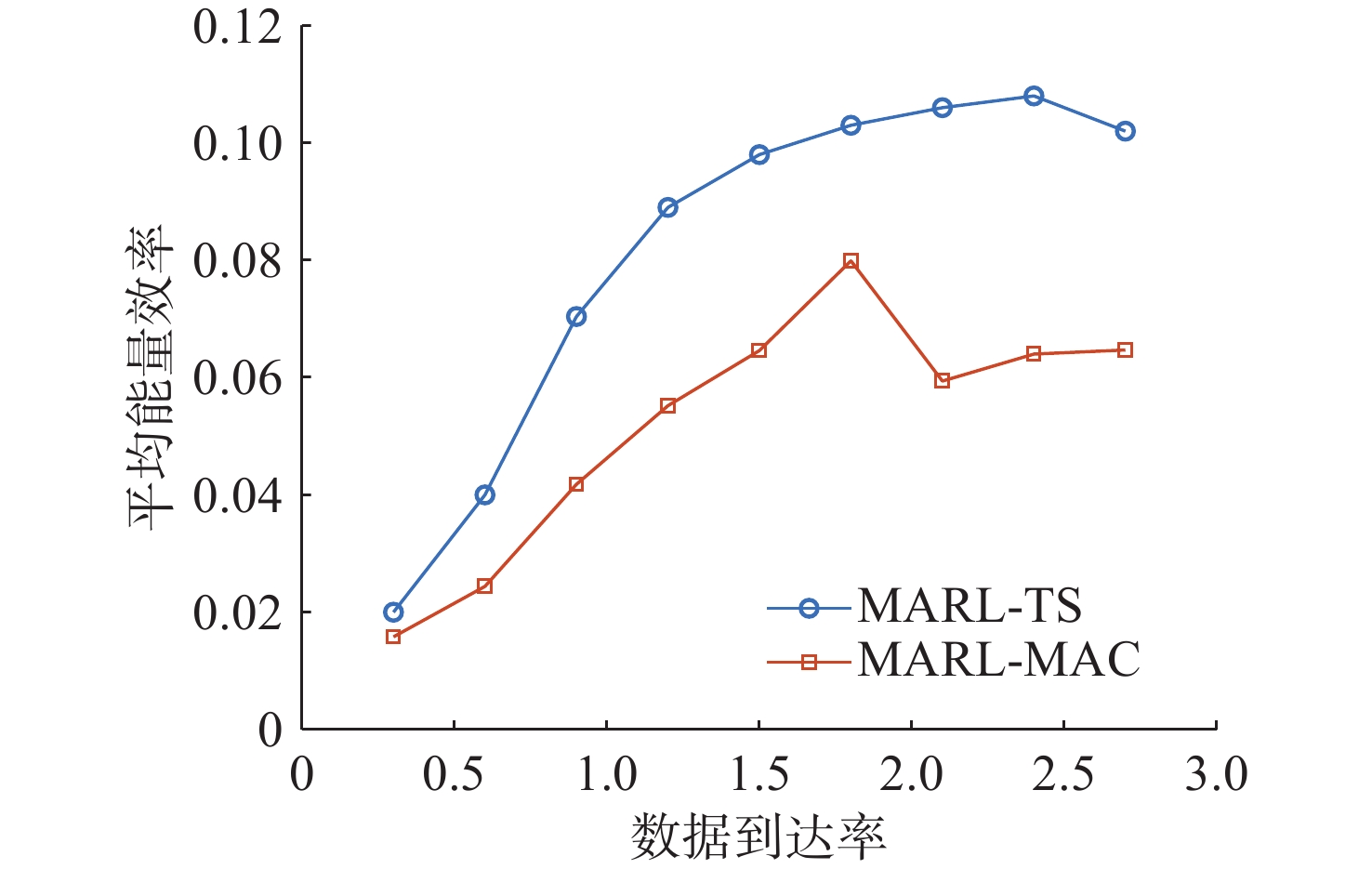
图 6 不同数据到达率下能量效率对比
Figure 6. Comparison of energy efficiency at different data arrival rates
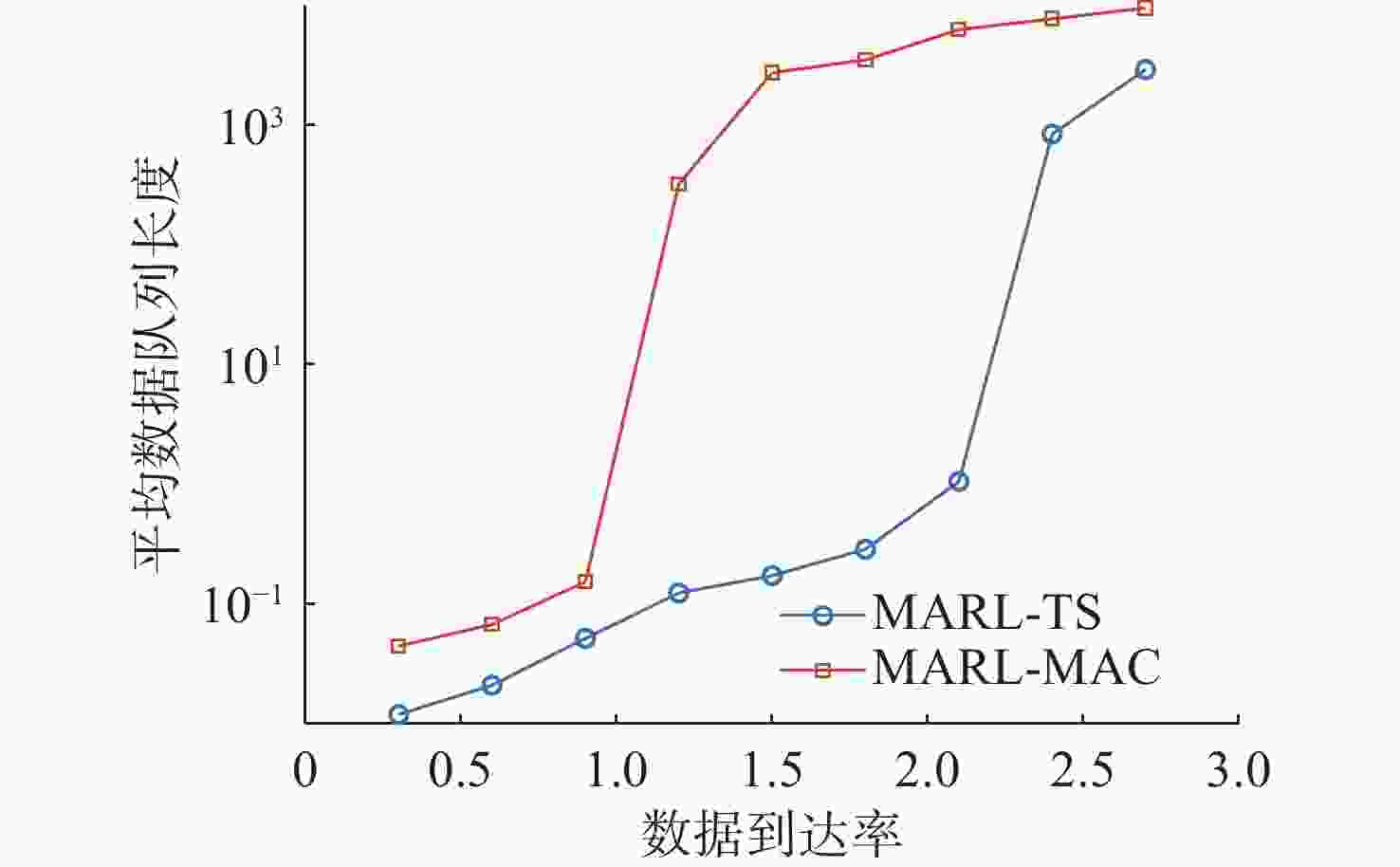
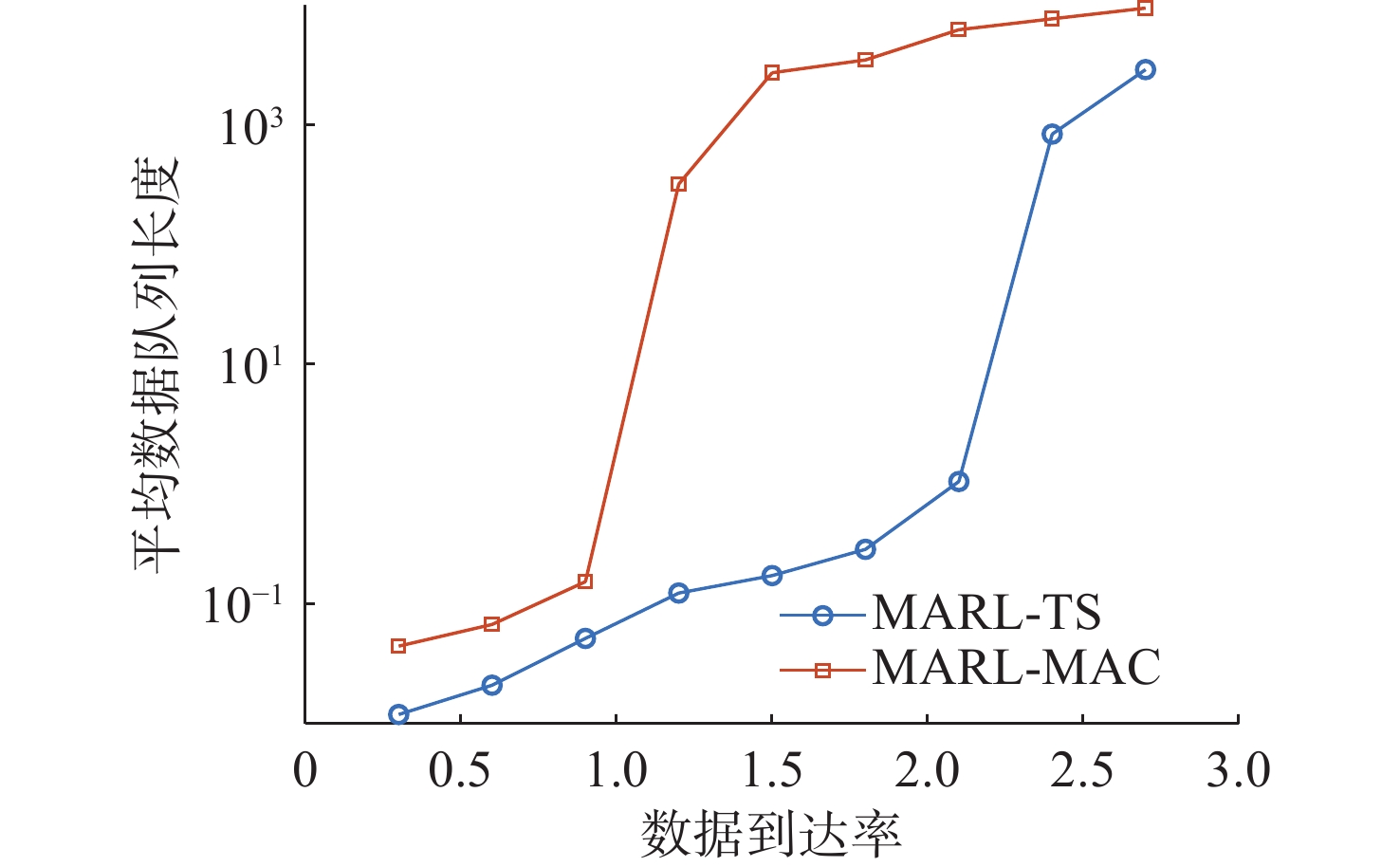
图 7 不同数据到达率下平均数据队列长度对比
Figure 7. Comparison of average data queue length at different data arrival rates
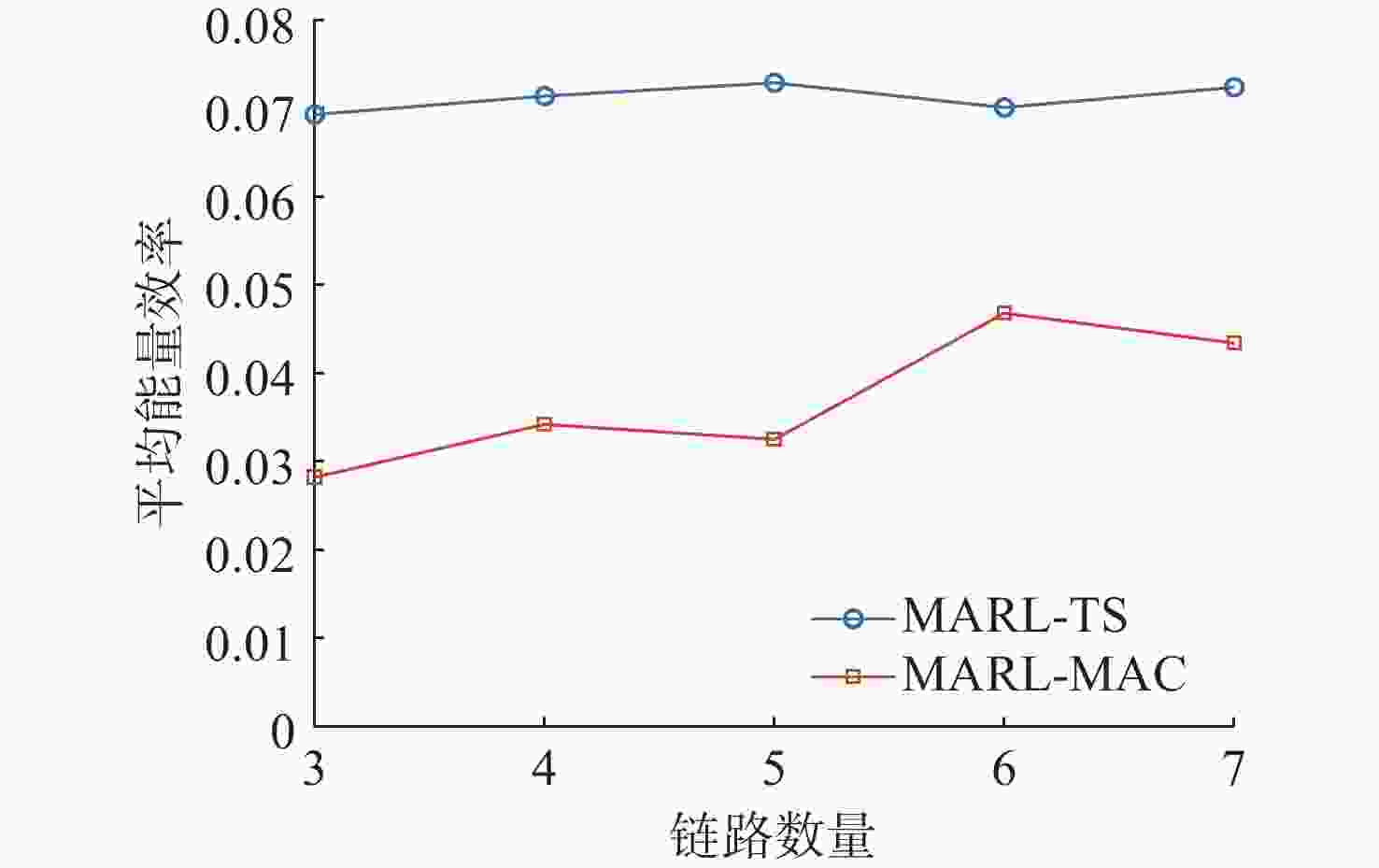
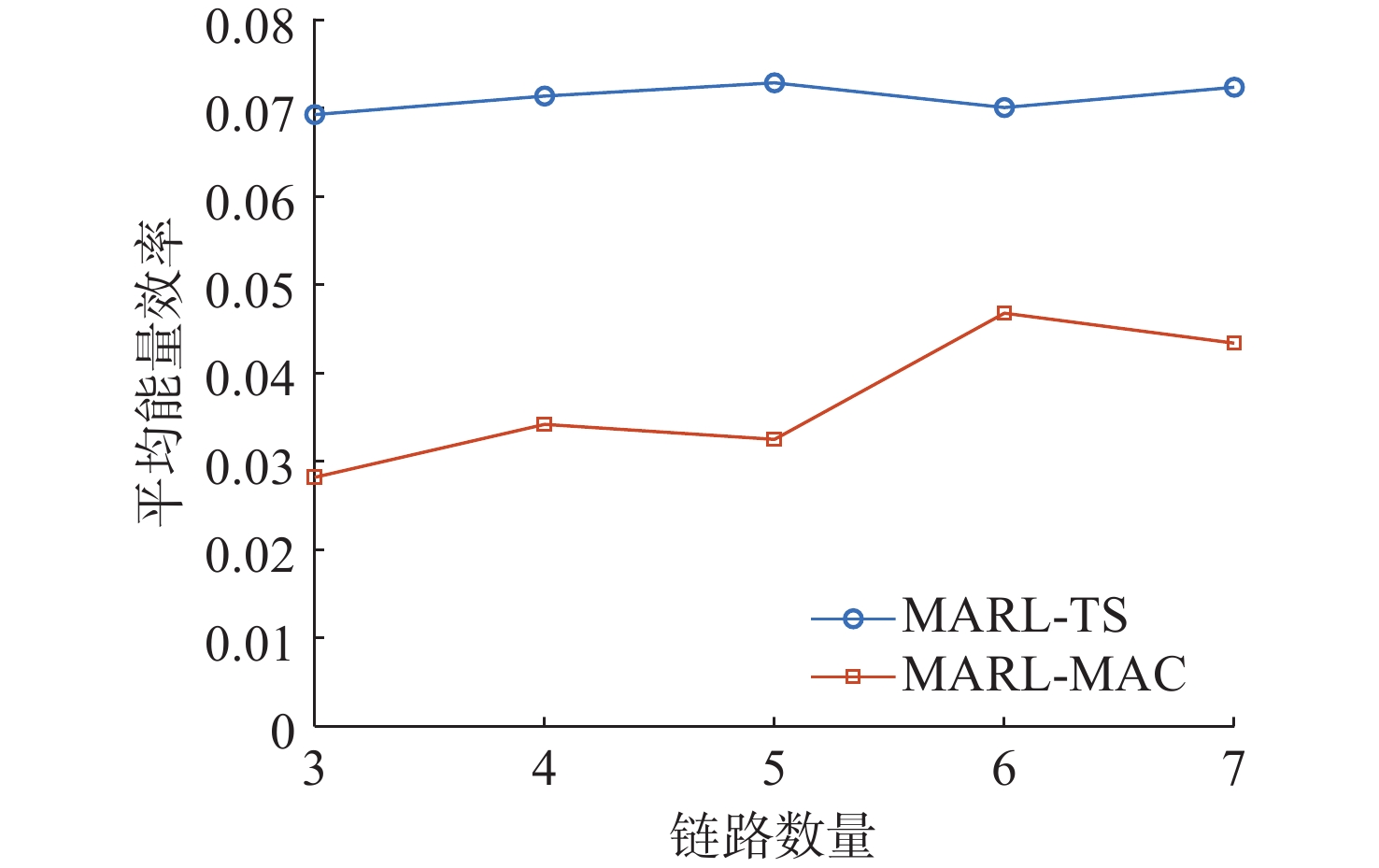
图 8 不同链路数量下能量效率对比
Figure 8. Comparison of energy efficiency with different number of links
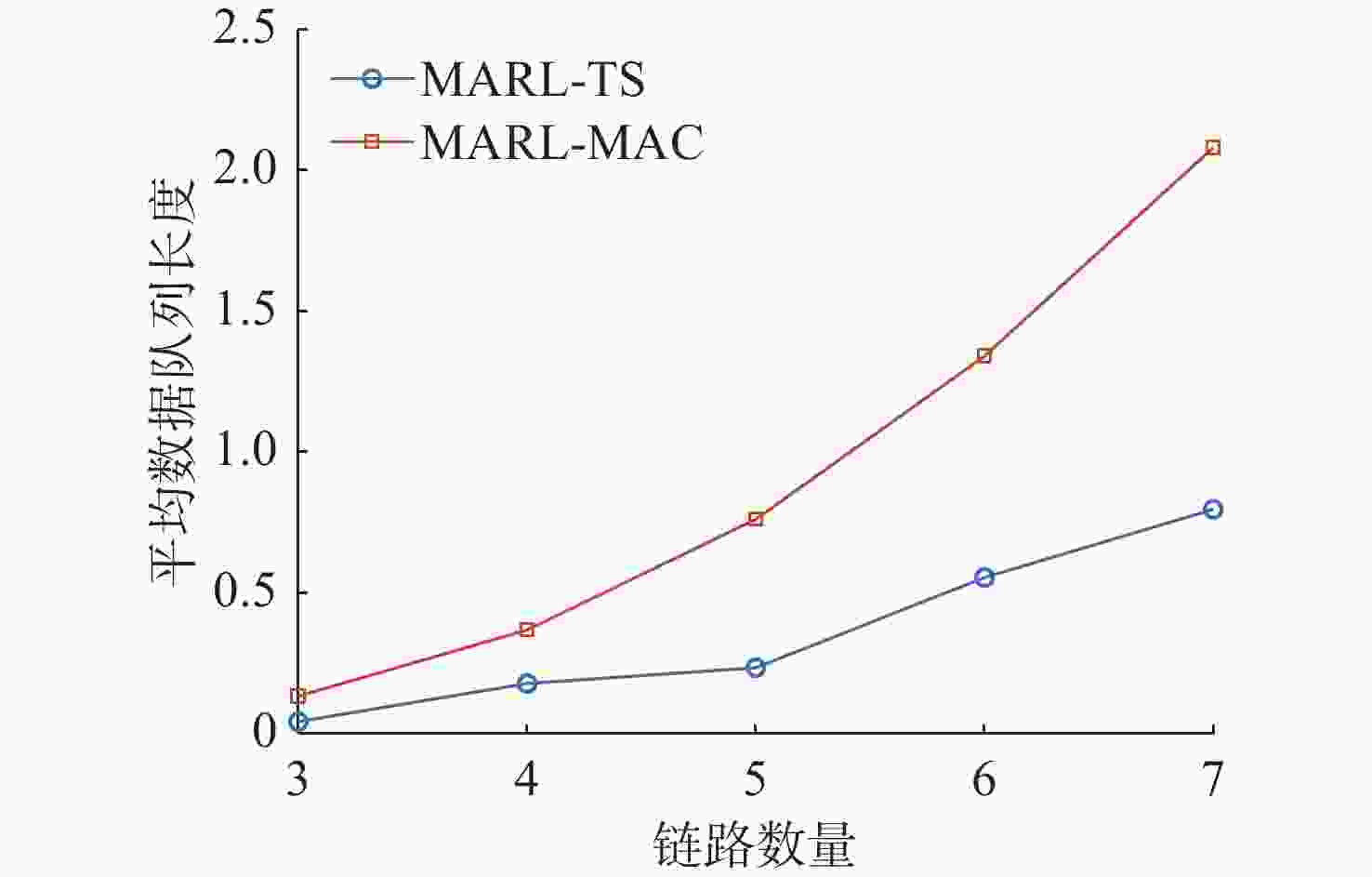
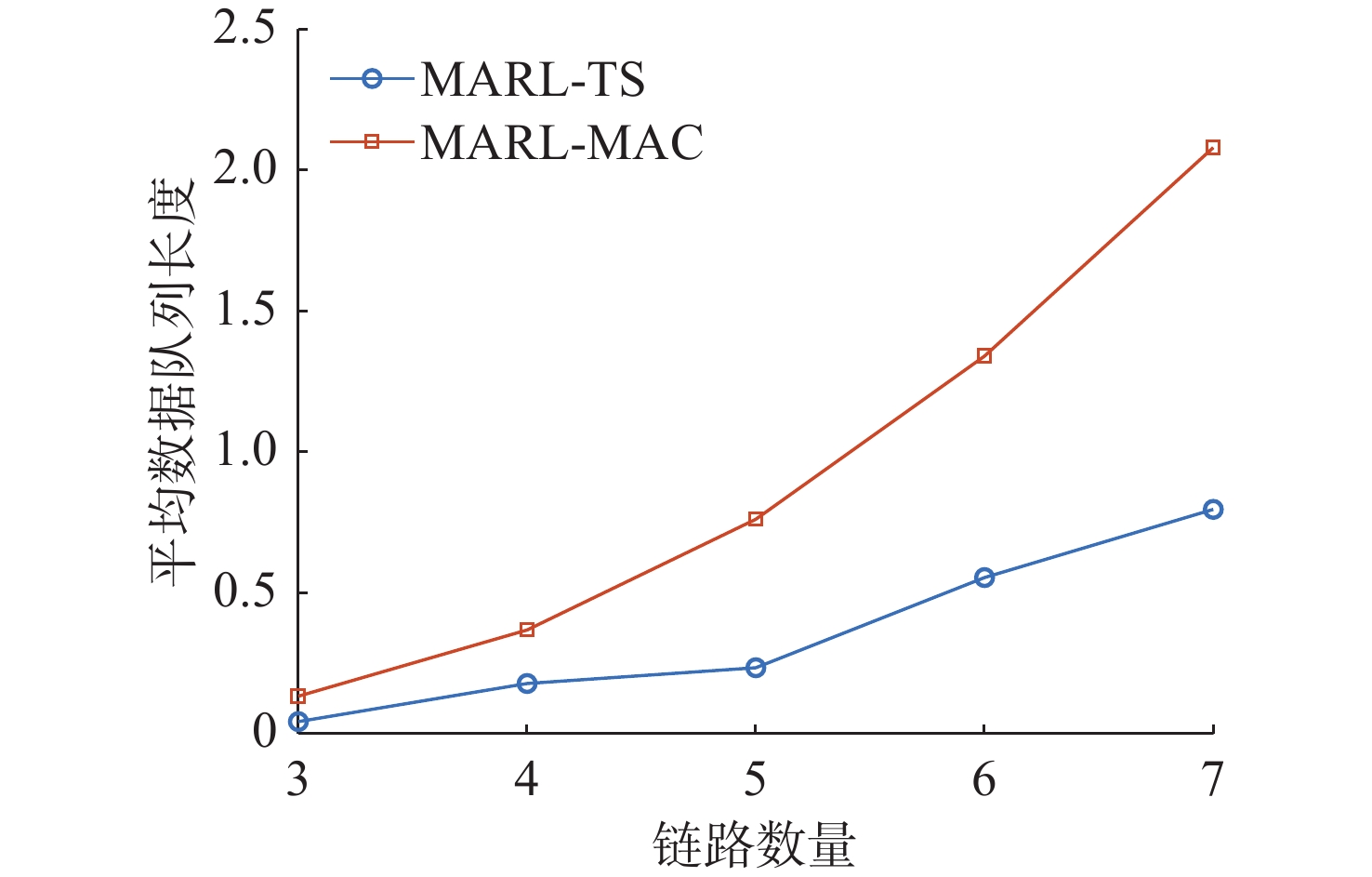
图 9 不同链路数量下平均数据队列长度对比
Figure 9. Comparison of the average data queue length for different number of links
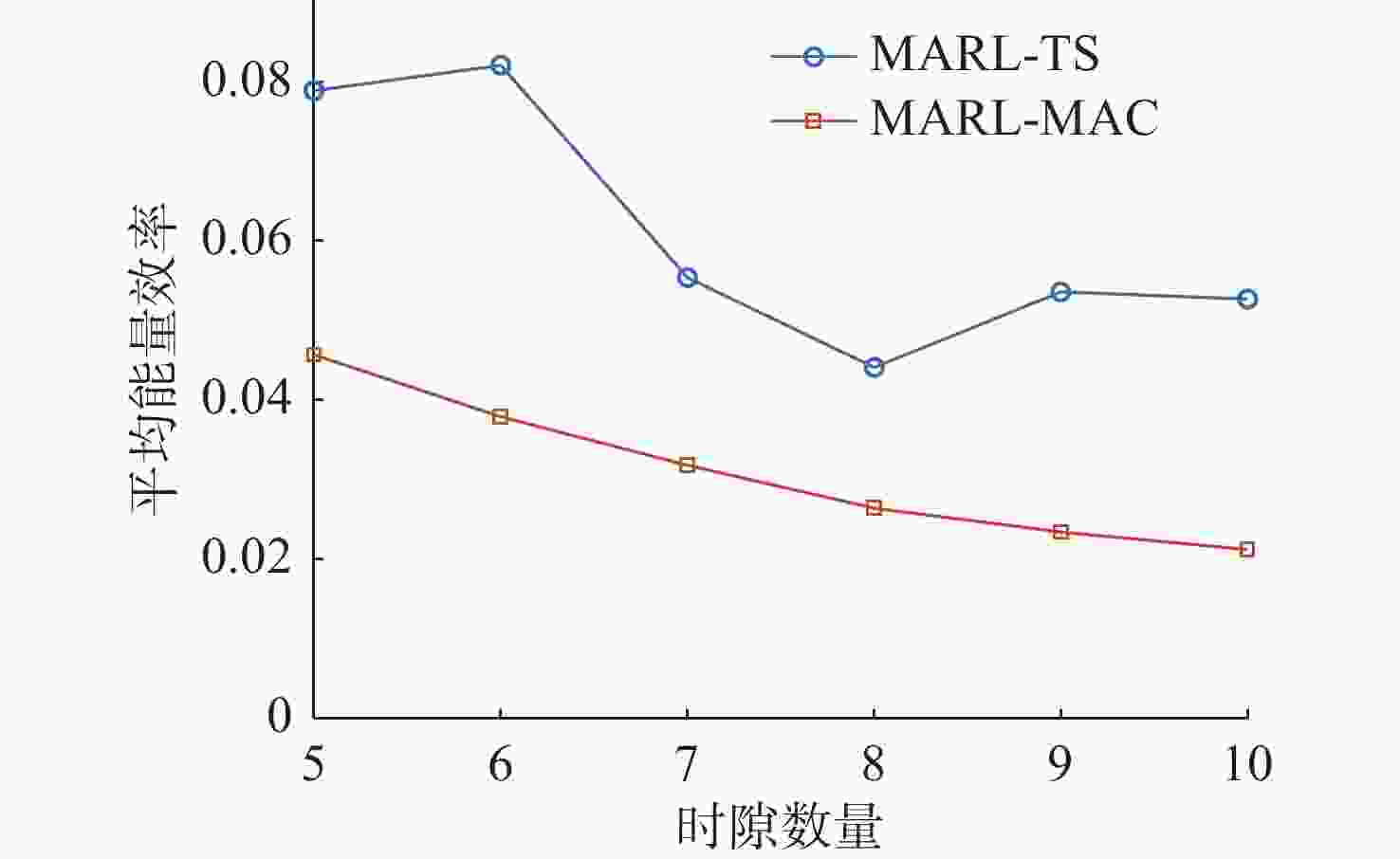
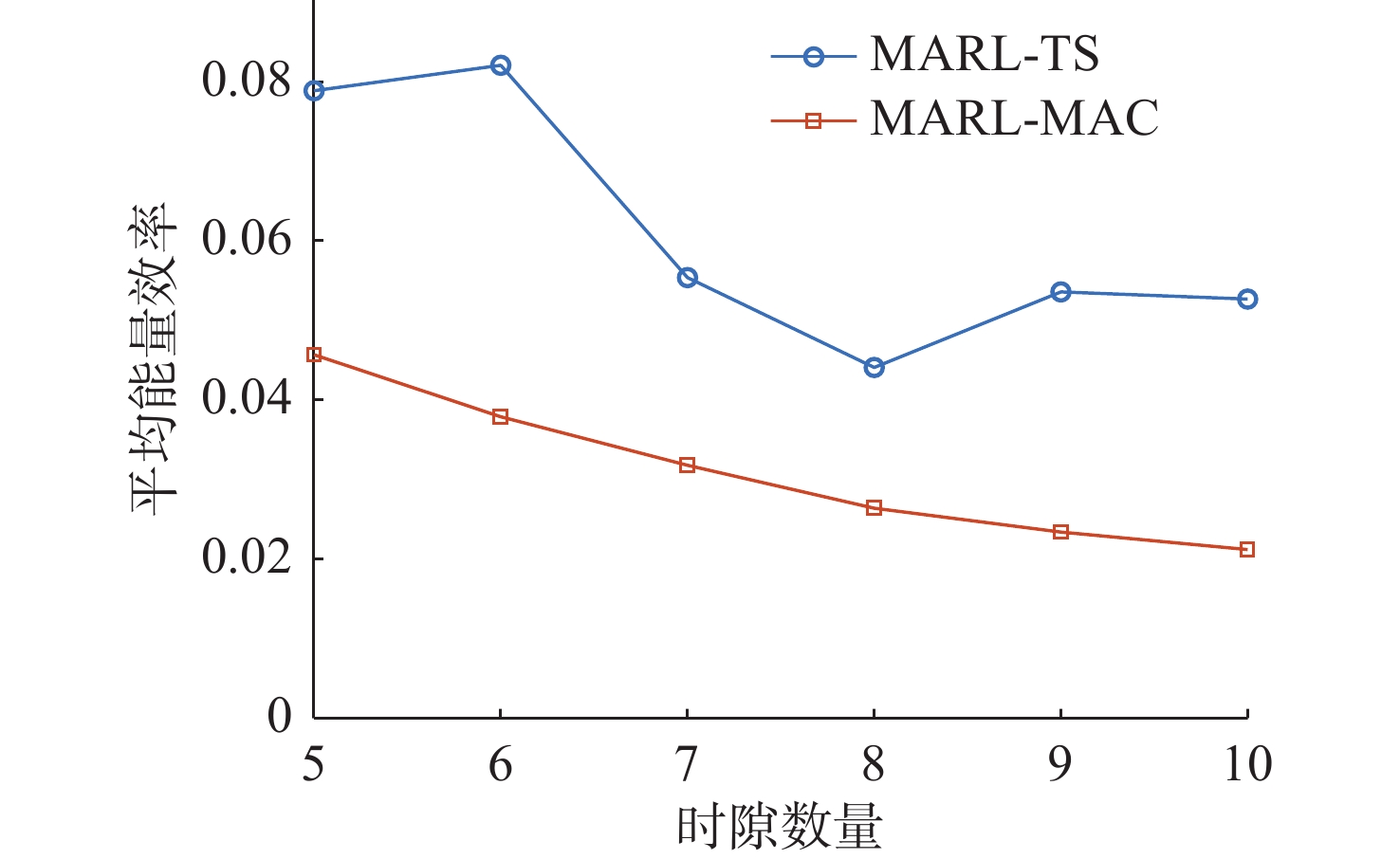
图 10 不同时隙数量下能量效率对比
Figure 10. Comparison of energy efficiency at different number of time slots
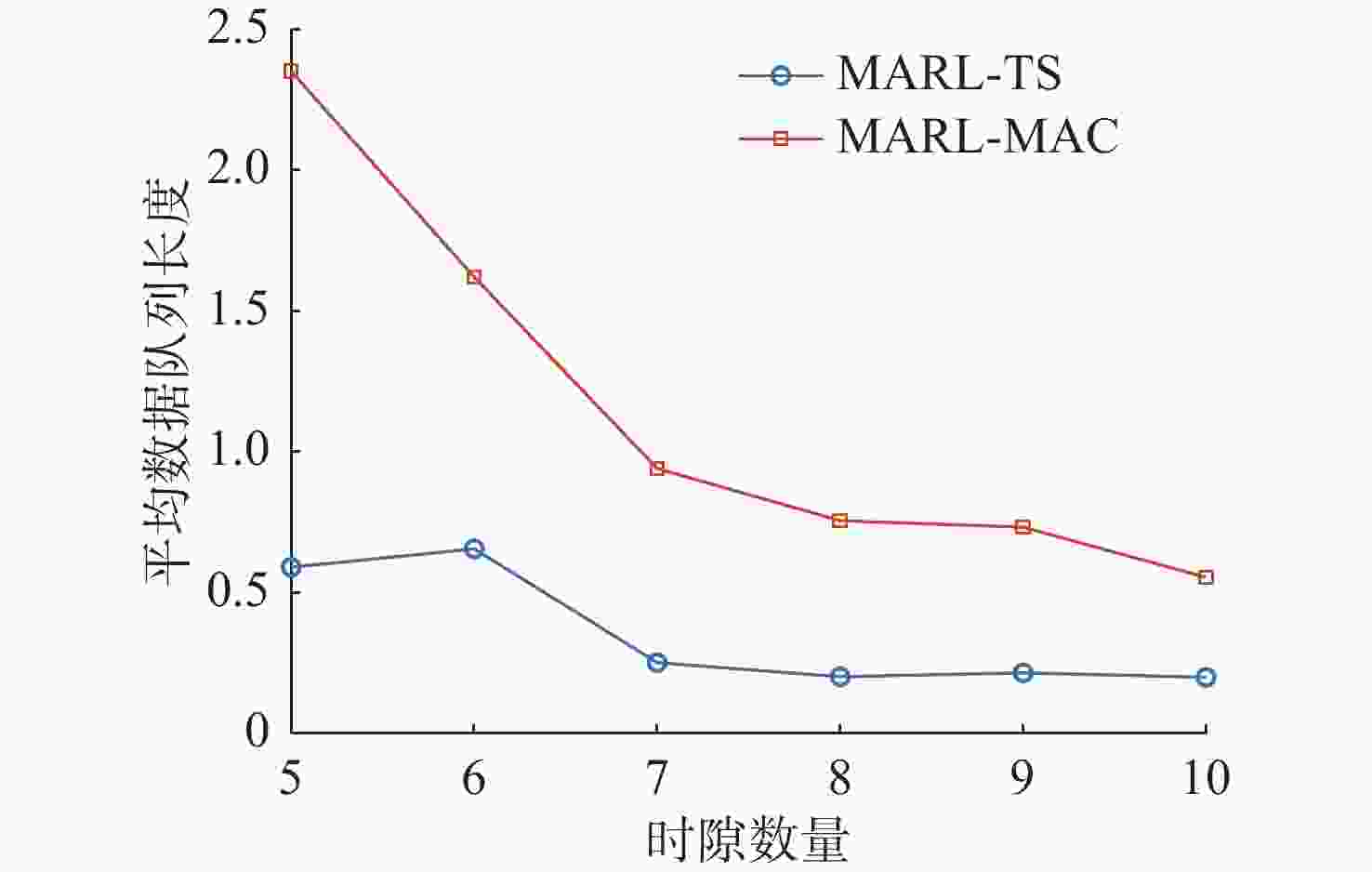
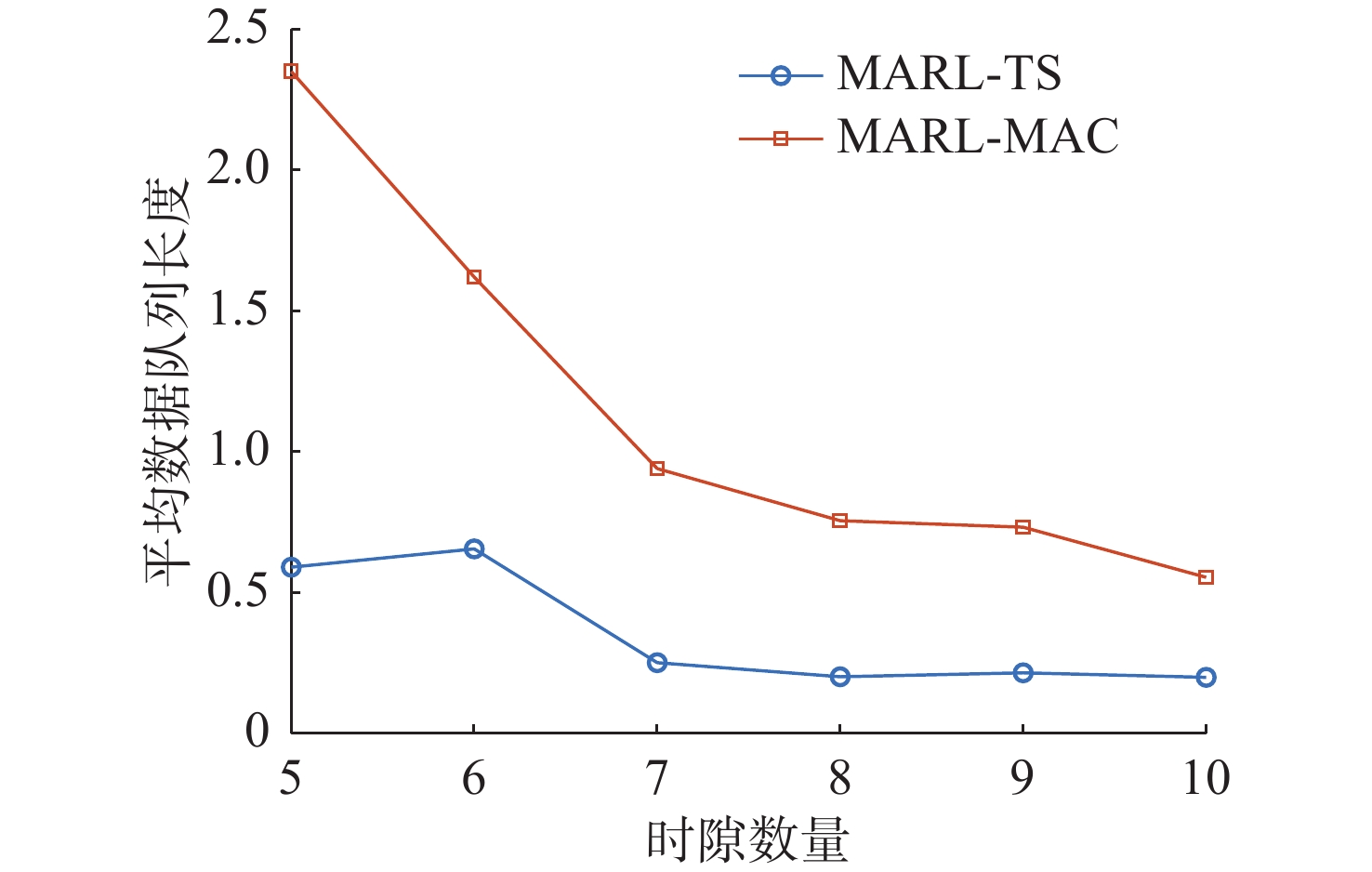
图 11 不同时隙数量下平均数据队列长度对比
Figure 11. Comparison of average data queue length for different number of time slots

图 12 高信噪比信道条件下传输模式范例
Figure 12. Example of transmission patterns under high signal-to-noise ratio channel conditions
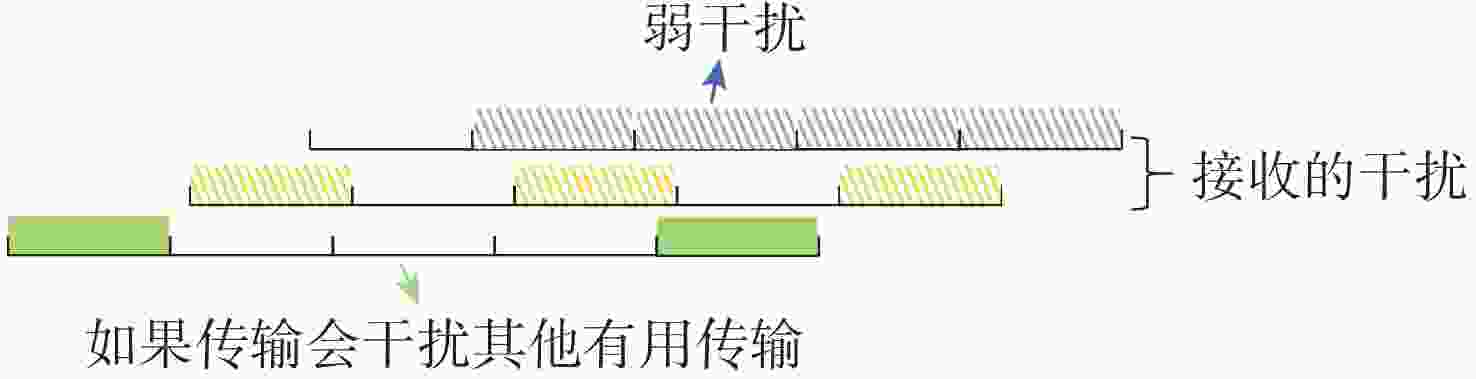
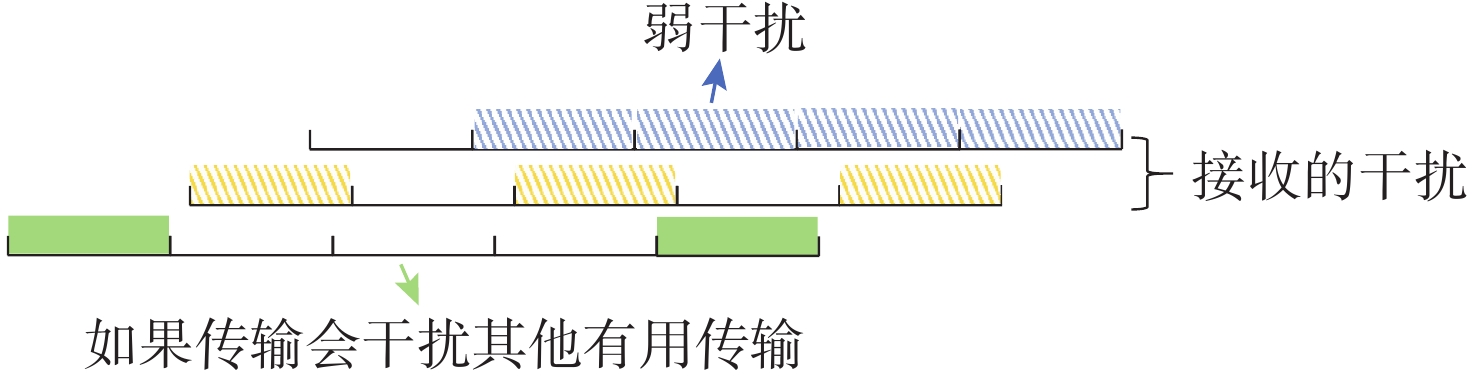
图 13 弱干扰条件下传输模式范例
Figure 13. Example of transmission patterns under weak interference conditions
表 1 典型场景中MARL-TS与SARL-TS能效与传输时延对比
Table 1. Comparison of energy efficiency and transmission delay between MARL-TS and SARL-TS in typical scenarios
方法 EE/(packet/J) 场景1 场景2 场景3 MARL-TS 0.078 9 0.069 3 0.078 9 SARL-TS 0.069 7 0.038 0 0.045 7 方法 DQL/(packet/J) 场景1 场景2 场景3 MARL-TS 0.119 0 0.042 8 0.199 0 SARL-TS 0.370 0 0.226 0 0.534 0  下载: 导出CSV
下载: 导出CSV
-
[1] NEIRA J, SEQUEIROS C, HUAMANI R, et al. Review on unmanned underwater robotics, structure designs, materials, sensors, actuators, and navigation control[J]. Journal of Robotics, 2021, 1: 5542920. [2] 江子龙, 王焱, 钟雪峰, 等. 基于NS-3的声电协同网络实现及路由性能分析[J]. 电子与信息学报, 2022, 44(6): 2014-2023. doi: 10.11999/JEIT211274JIANG Z L, WANG Y, ZHONG X F, et al. Implementation of acoustic-electric cooperative networks and routing performance analysis based on NS-3[J]. Journal of Electronics & Information Technology, 2022, 44(6): 2014-2023. doi: 10.11999/JEIT211274 [3] 刘千里, 吴晖. 水下无线传感器网络通信技术研究现状及趋势[J]. 舰船电子工程, 2022, 42(9): 20-24.LIU Q L, WU H. Research status and trends of underwater wireless sensor network communication technology[J]. Ship Electronic Engineering, 2022, 42(9): 20-24. [4] 瞿逢重, 付雁冰, 杨劭坚, 等. 应用于海洋物联网的水声通信技术发展综述[J]. 哈尔滨工程大学学报, 2023, 44(11): 1937-1949. doi: 10.11990/jheu.202306023QU F Z, FU Y B, YANG S J, et al. An overview of the development status of underwater acoustic communication technology applied to ocean internet-of-things[J]. Journal of Harbin Engineering University, 2023, 44(11): 1937-1949. doi: 10.11990/jheu.202306023 [5] CHAUDHARY M, GOYAL N, BENSLIMANE A, et al. Underwater wireless sensor networks: Enabling technologies for node deployment and data collection challenges[J]. IEEE Internet of Things Journal, 2022, 10(4): 3500-3524. [6] ZHAO N, YAO N, GAO Z. An adaptive MAC protocol based on time-domain interference alignment for UWANs[J]. The Computer Journal, 2023, 66(12): 3015-3028. [7] 赵昊. 基于深度学习的水声通信物理层技术研究[D]. 广州: 华南理工大学, 2023. [8] PALLARES O, BOUVET P J, RIO J D. TS-MUWSN: Time synchronization for mobile underwater sensor networks[J]. IEEE Journal of Oceanic Engineering, 2016, 41(4): 763-775. doi: 10.1109/JOE.2016.2581658 [9] HSU C C, KUO M S, CHOU C F, et al. The elimination of spatial-temporal uncertainty in underwater sensor networks[J]. IEEE/ACM Transactions on Networking, 2013, 21(4): 1229-1242. [10] HUANG Q H, LI W, ZHAN W C, et al. Dynamic underwater acoustic channel tracking for correlated rapidly time-varying channels[EB/OL]. (2021-03-01)[2025-03-20]. https://arXiv:2103.00859. [11] DU H, WANG X, SUN W, et al. An adaptive MAC protocol for underwater acoustic networks based on deep reinforcement learning[C]//The 6th International Conference on Communications, Information System and Computer Engineering. Guangzhou, China: IEEE, 2025. [12] TOMOVIC S, RADUSINOVI I. DR-ALOHA-Q: A Q-Learning-based adaptive MAC protocol for underwater acoustic sensor networks[J]. Sensors, 2023, 23(9): 4474. [13] HUANG Y, WANG H, CHEN Y, et al. Distributed deep reinforcement learning with prioritized replay for power allocation in underwater acoustic communication networks[J]. IEEE Internet of Things Journal, 2024, 11(6): 9915-9928. [14] YE X, YU Y, FU L. Deep reinforcement learning based MAC protocol for underwater acoustic networks[J]. IEEE Transactions on Mobile Computing, 2020, 21(5): 1625-1638. [15] HUANG J J, YE X W, FU L Q. MAC protocol for underwater acoustic multi-cluster networks based on multi-agent reinforcement learning[C]//The 17th International Conference on Underwater Networks & Systems. Guangzhou, China: ACM, 2023, 10: 1-5. [16] WANG C, WANG Z, SUN W, et al. Reinforcement learning-based adaptive transmission in time-varying underwater acoustic channels[J]. IEEE Access, 2017, 6: 2541-2558. [17] WANG H, LI Y, QIAN J. Self-adaptive resource allocation in underwater acoustic interference channel: A reinforcement learning approach[J]. IEEE Internet of Things Journal, 2020, 7(4): 2816-2827. [18] STOJANOVIC M, PREISIG J. Underwater acoustic communication channels: Propagation models and statistical characterization[J]. IEEE Communications Magazine, 2009, 47(1): 84-89. [19] WANG C F, ZHAO W K, BI Z C, et al. A joint power allocation and scheduling algorithm based on quasi-interference alignment in underwater acoustic networks[C]//Oceans 2022, Virginia, USA: IEEE, 2022. [20] TSATSANIS M K, GIANNAKIS G B, ZHOU G. Estimation and equalization of fading channels with random coefficients[J]. Signal Processing, 1996, 53(2-3): 211-229. [21] SCHULMAN J, WOLSKI F, DHARIWAL P, et al. Proximal policy optimization algorithms[EB/OL]. (2007-8-28)[2025-3-11]. https://arxiv.org/abs/1707.06347. [22] YU C, VELU A, VINITSKY E, et al. The surprising effectiveness of PPO in cooperative multi-agent games[J]. Advances in Neural Information Processing Systems, 2022, 35: 24611-24624. [23] LIU W, CAI W, JIANG K, et al. XUANCE: A comprehensive and unified deep reinforcement learning library[EB/OL]. (2023-12-25)[2025-3-11]. https://arxiv.or-g.abs/2312.16248. -

 下载:
下载:


 点击查看大图
点击查看大图
计量
- 文章访问数: 607
- HTML全文浏览量: 304
- PDF下载量: 123
- 被引次数: 0





