

Multi-Underwater Target Interception Strategy Based on Deep Reinforcement Learning
-
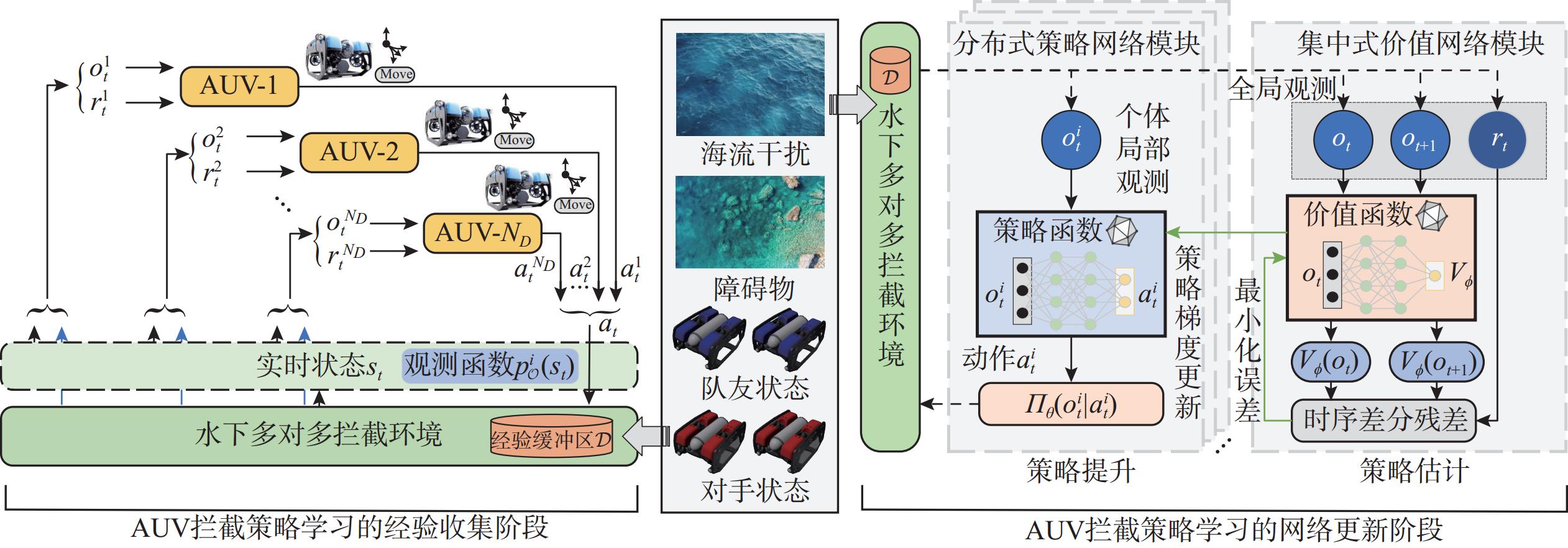
摘要: 在多自主水下航行器(AUV)拦截水下目标时, AUV需在竞争与合作的双重挑战下根据敌友信息作出精准决策。现有研究多集中于简单环境下的单目标拦截, 缺乏对复杂环境下多目标拦截协作机制的深入探讨。针对这一问题, 文中提出一种多智能体深度强化学习框架, 帮助AUV在具有复杂障碍和时变海流的环境中学习拦截策略, 重点开发其在多对多态势下的协作机制。首先设计了一种分层机动框架, 通过3层循环增强AUV决策能力;然后基于多智能体近端策略优化算法, 构建可伸缩的状态和动作空间, 并设计复合奖励函数, 以提高AUV拦截效率和协同能力;最后在集中训练-分布式执行架构下, 提出种群扩展-课程式学习训练方案, 帮助AUV掌握具有泛化性的协同策略。训练结果表明, 所提框架下的拦截策略能快速收敛, 保障高成功率。仿真实验表明, 训练得到的AUV团队可在多种群配置下使用同一套模型, 在避开障碍物的同时,通过合作有效拦截多个入侵目标。Abstract: In the context of multiple autonomous undersea vehicles(AUVs) executing underwater target interception missions, AUVs are required to make precise decisions based on both enemy and partner information, navigating the dual challenges of competition and cooperation. Most existing research typically focuses on single-target interception in simple environments and lacks a detailed exploration of collaborative mechanisms for multi-target interception mechanisms in complex environments. Therefore, this paper proposed a multi-agent deep reinforcement learning framework for AUVs to learn interception strategies in environments with complex obstacles and time-vary ocean currents, with a focus on cooperation in many-to-many game scenarios. First, a hierarchical maneuvering framework was introduced to improve the decision-making ability of AUVs through a three-layer loop structure. Next, the multi-agent proximal policy optimization algorithm was used to construct a scalable state and action space and design a compound reward function, enhancing interception efficiency and cooperation of AUVs. Finally, a population expansion–curriculum learning approach was incorporated within a centralized training and distributed execution architecture to help AUVs master generalizable cooperation strategies. Training results show rapid convergence and high success rates of the proposed interception strategies. The simulation experiments show that the trained AUVs can use the same set of models in multiple population configurations to effectively intercept multiple intruding targets through cooperation while avoiding obstacles.
-

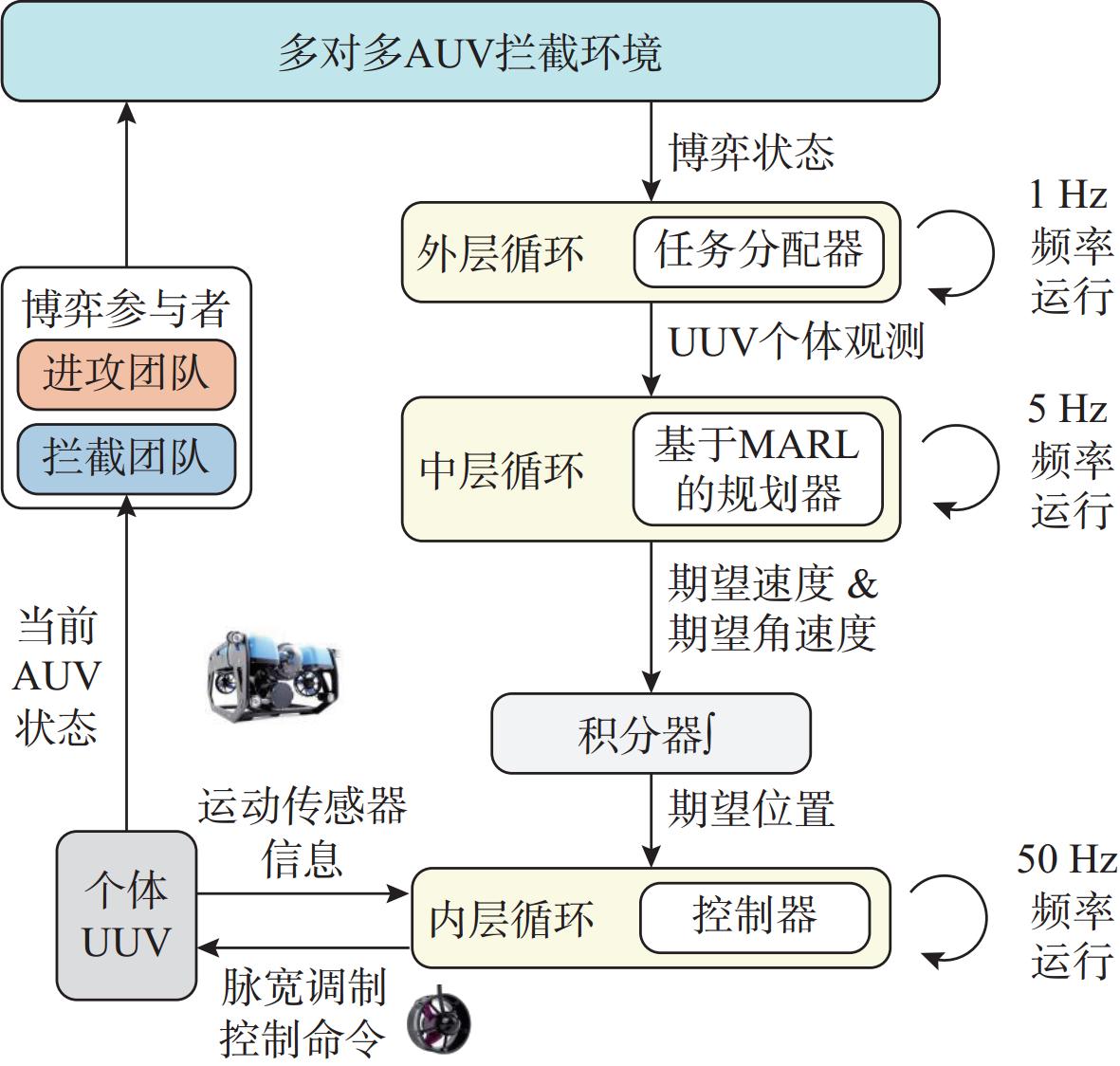
图 2 AUV拦截任务分层决策机动框架
Figure 2. Hierarchical decision-making maneuvering framework for AUV interception tasks

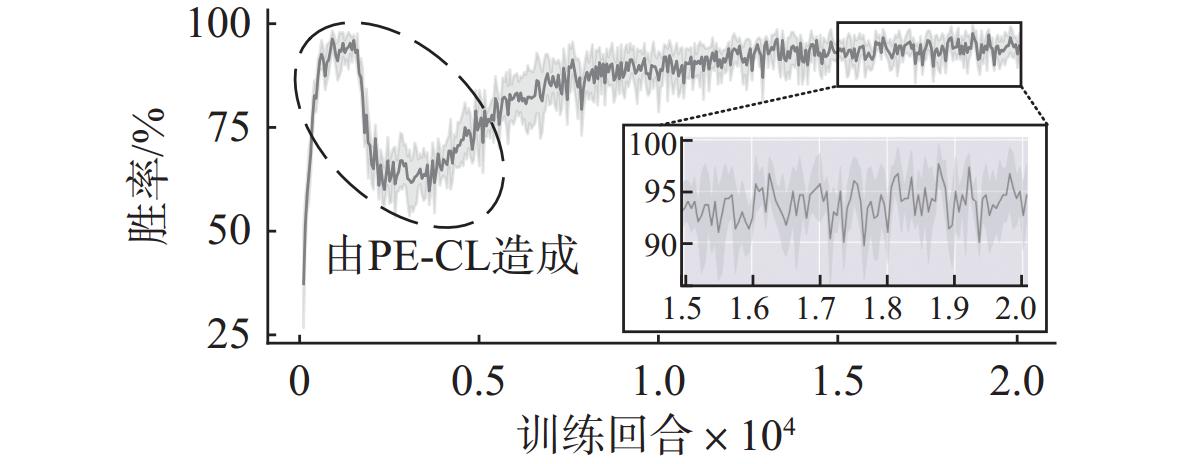
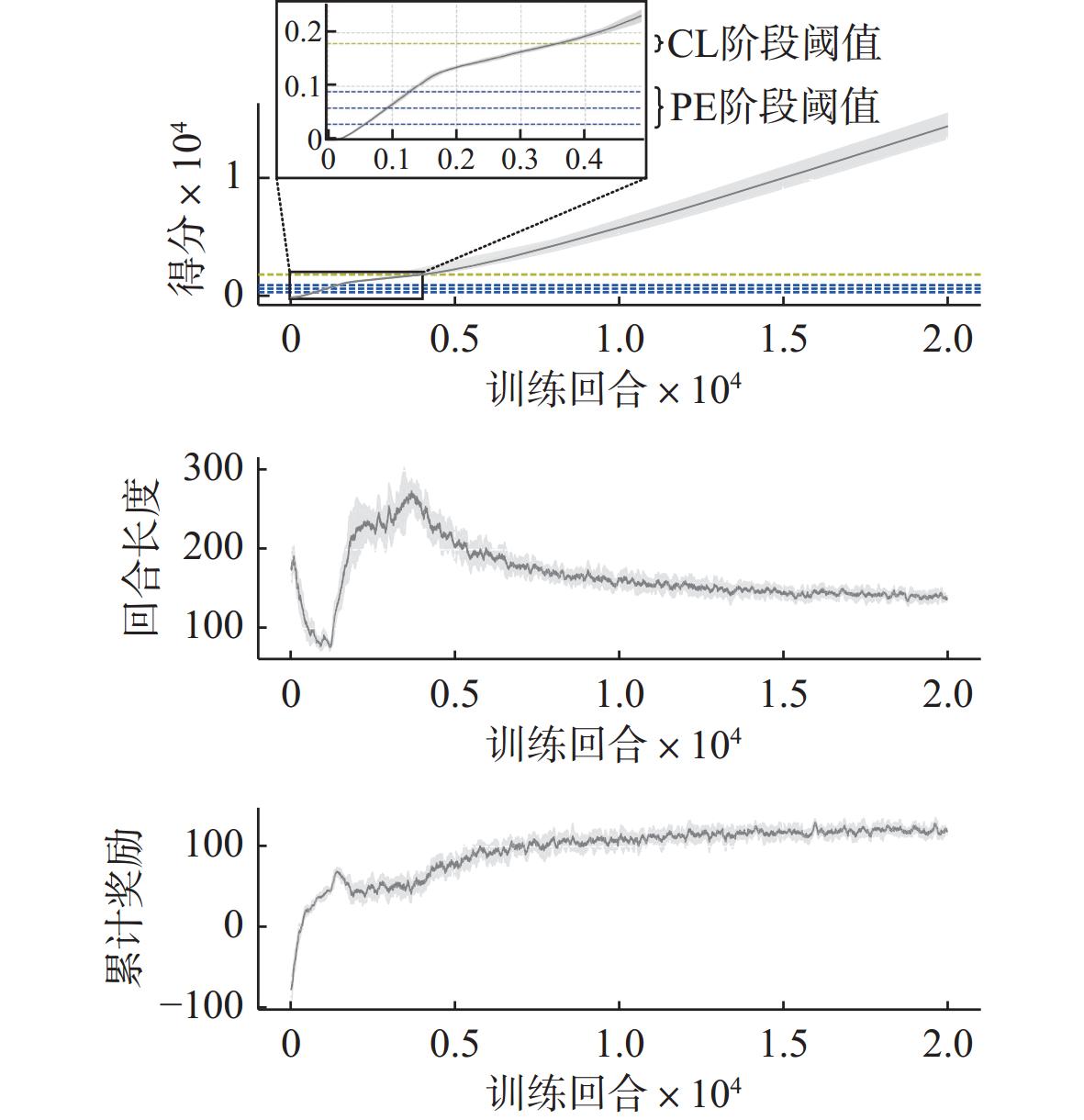
图 5 训练过程中拦截胜率变化情况
Figure 5. Change of interception success rate during training process

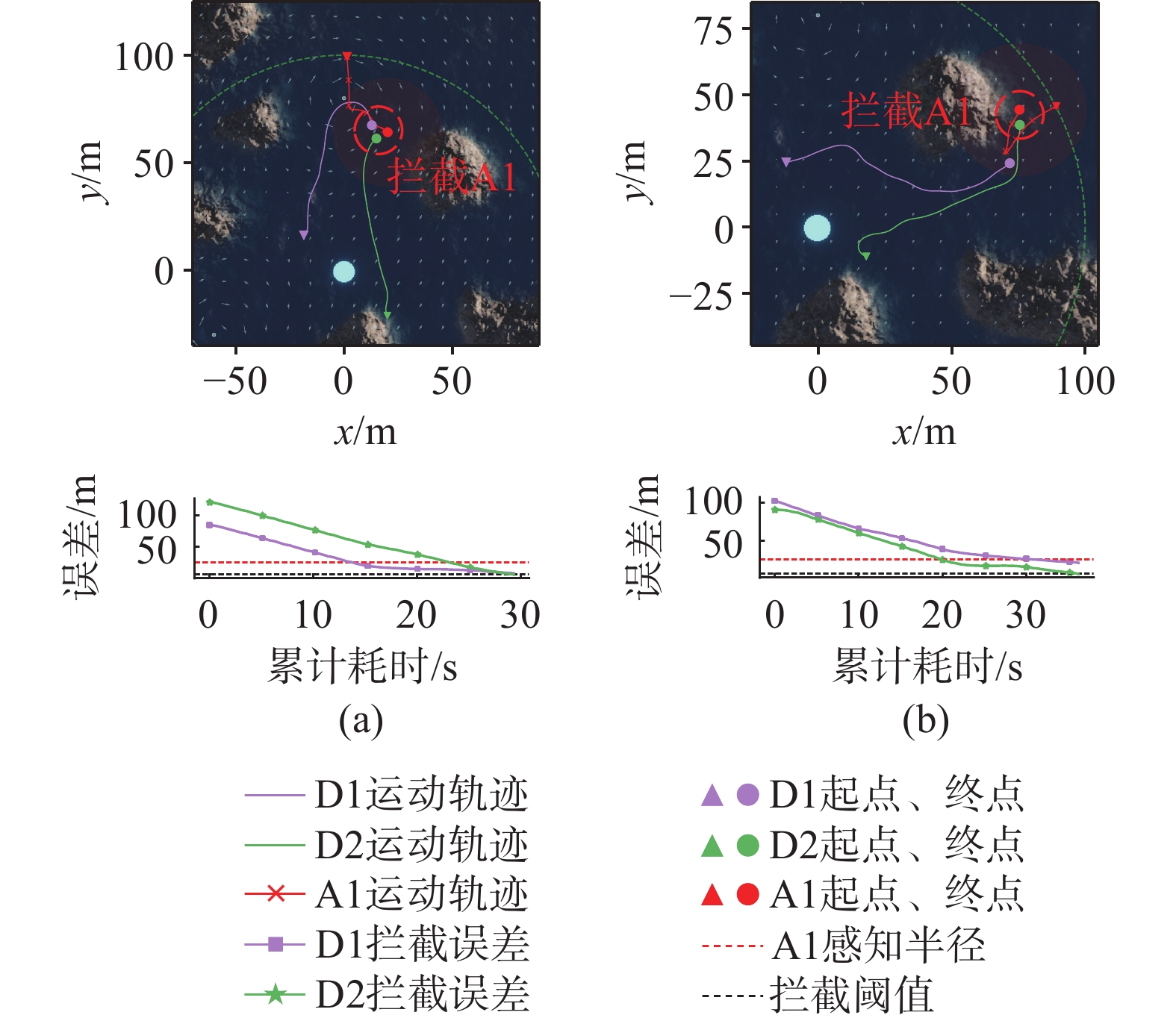
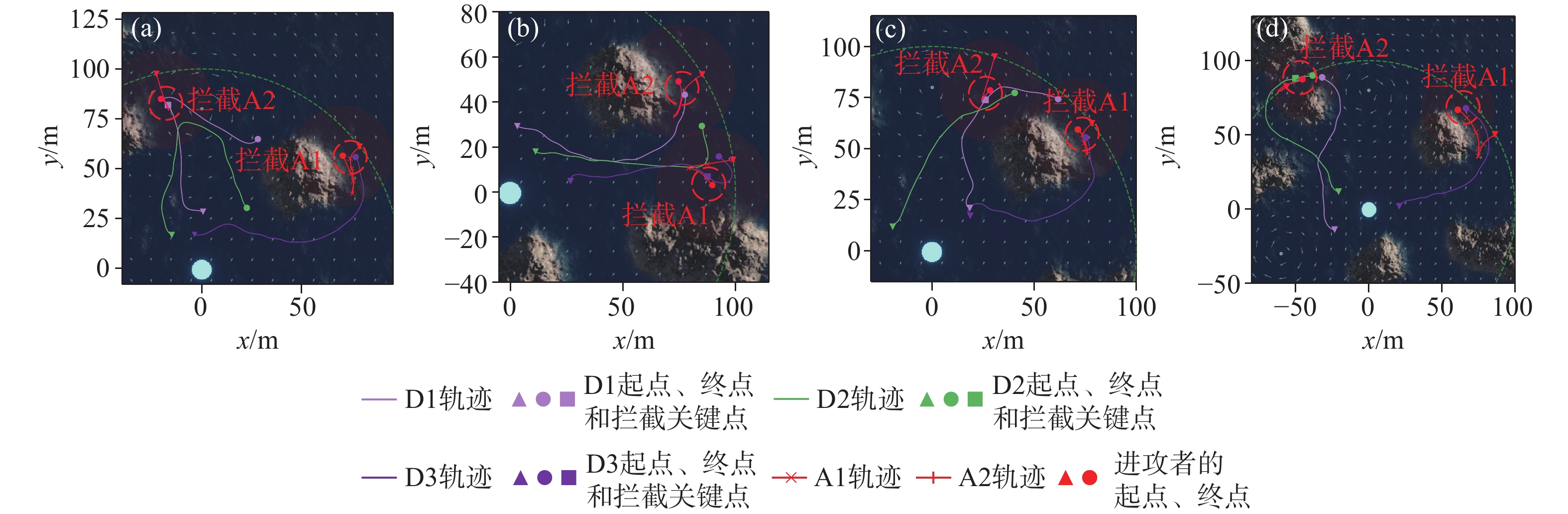
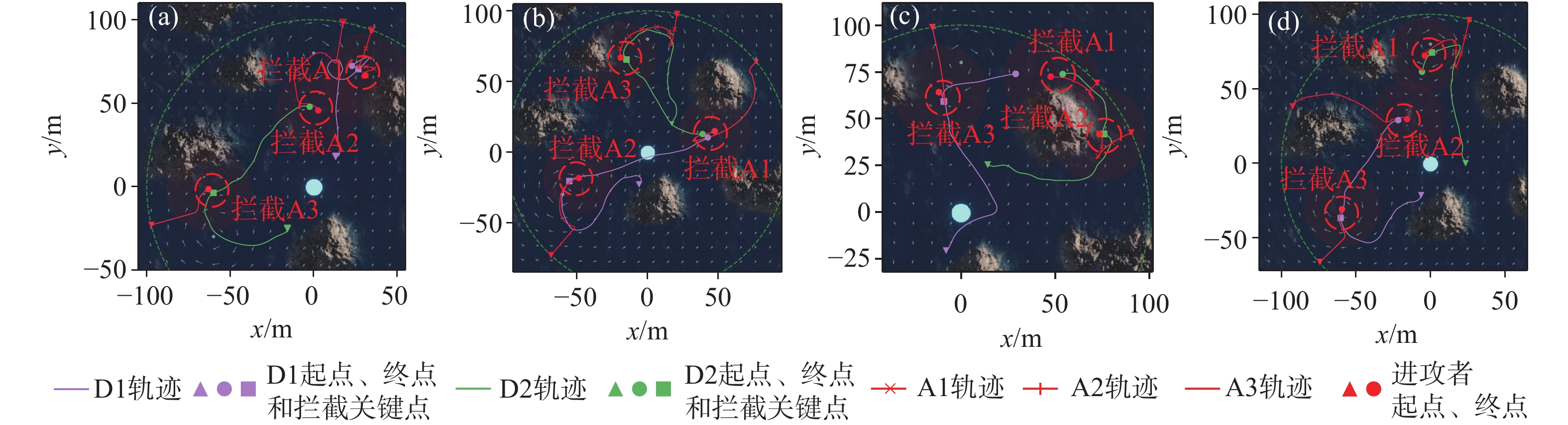
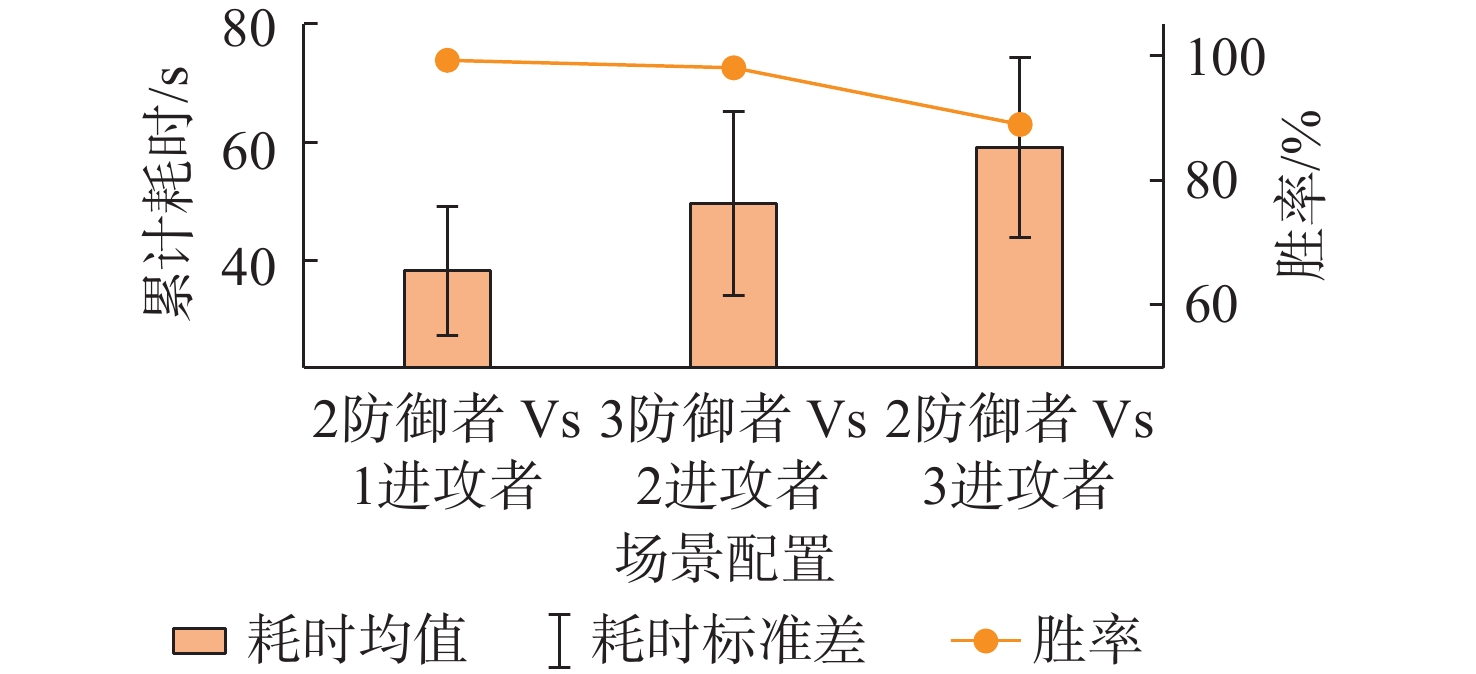
图 10 AUV拦截仿真实验的统计结果
Figure 10. Statistical results of AUV interception simulation experiments
表 1 奖励及环境相关参数
Table 1. Rewards and environmental-related parameters
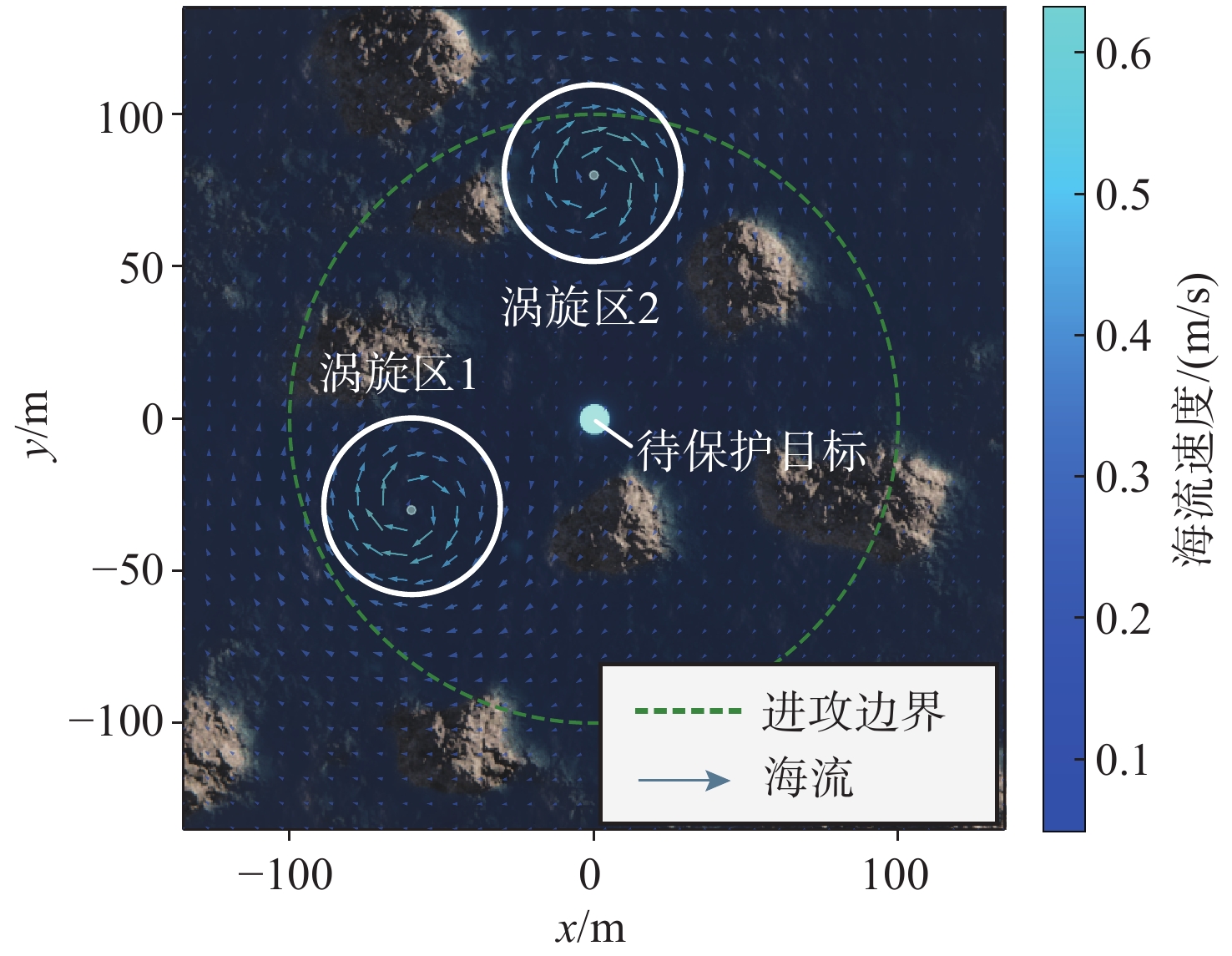
名称 参数值 奖励系数$ ({k_{rp}},{k_s},{k_I}) $ (1.5, 0.4, 50) 防御AUV数量$ {N_D} $ 1~3 进攻AUV数量$ {N_A} $ 1~3 涡心位置/m (−60, −30), (0, 80) 涡旋强度$ \mathit{\Gamma} $ 8 涡旋半径$ \delta $/m 80 安全半径$ R_T^{{\text{safe}}} $/m 5  下载: 导出CSV
下载: 导出CSV
-
[1] 胡桥, 赵振轶, 冯豪博, 等. AUV 智能集群协同任务研究进展[J]. 水下无人系统学报, 2023, 31(2): 189-200. doi: 10.11993/j.issn.2096-3920.2023-0002 [2] 梁晓龙, 杨爱武, 张佳强, 等. 无人集群博弈对抗系统仿真验证及决策关键技术综述[J]. 系统仿真学报, 2024, 36(4): 805-816. [3] SUN S, SONG B, WANG P, et al. Real-time mission-motion planner for multi-UUVs cooperative work using tri-level programing[J]. IEEE Transactions on Intelligent Transportation Systems, 2020, 23(2): 1260-1273. [4] ANTONIONI E, SURIANI V, RICCIO F, et al. Game strategies for physical robot soccer players: A survey[J]. IEEE Transactions on Games, 2021, 13(4): 342-357. doi: 10.1109/TG.2021.3075065 [5] 赵伟, 叶军, 王邠. 基于人工智能的智能化指挥决策和控制[J]. 信息安全与通信保密, 2022(2): 2-8. doi: 10.3969/j.issn.1009-8054.2022.02.001 [6] 秦家虎, 马麒超, 李曼, 等. 多智能体协同研究进展综述: 博弈和控制交叉视角[J]. 自动化学报, 2025, 51(3): 489-509. [7] 罗彪, 胡天萌, 周育豪, 等. 多智能体强化学习控制与决策研究综述[J]. 自动化学报, 2025, 51(3): 510-539. [8] HOU Y, HAN G, ZHANG F, et al. Distributional soft actor-critic-based multi-AUV cooperative pursuit for maritime security protection[J]. IEEE Transactions on Intelligent Transportation Systems, 2024, 25(6): 6049-6060. doi: 10.1109/TITS.2023.3341034 [9] XU J, ZHANG Z, WANG J, et al. Multi-AUV pursuit-evasion game in the internet of underwater things: An efficient training framework via offline reinforcement learning[J]. IEEE Internet of Things Journal, 2024, 11(19): 31273-31286. doi: 10.1109/JIOT.2024.3416616 [10] ZHANG C, CHENG P, LIN B, et al. DRL-based target interception strategy design for an underactuated USV without obstacle collision[J]. Ocean Engineering, 2023, 280: 114443. doi: 10.1016/j.oceaneng.2023.114443 [11] 于长东, 刘新阳, 陈聪, 等. 基于多智能体深度强化学习的无人艇集群博弈对抗研究[J]. 水下无人系统学报, 2024, 32(1): 79-86. doi: 10.11993/j.issn.2096-3920.2023-0159 [12] 夏家伟, 朱旭芳, 张建强, 等. 基于多智能体强化学习的无人艇协同围捕方法[J]. 控制与决策, 2023, 38(5): 1438-1447. [13] 孙兵, 戚国亮, 张威, 等. 基于粒子群优化-人工势场的多AUV拦截技术研究[J]. 控制工程, 2024, 31(5): 769-777. [14] SUN B, MA H, ZHU D. A fusion designed improved elastic potential field method in AUV underwater target interception[J]. IEEE Journal of Oceanic Engineering, 2023, 48(3): 640-648. doi: 10.1109/JOE.2023.3258068 [15] YU C, VELU A, VINITSKY E, et al. The surprising effectiveness of PPO in cooperative multi-agent games[J]. Advances in Neural Information Processing Systems, 2022, 35: 24611-24624. [16] JANOSOV M, VIRÁGH C, VÁSÁRHELYI G, et al. Group chasing tactics: How to catch a faster prey[J]. New Journal of Physics, 2017, 19(5): 053003. doi: 10.1088/1367-2630/aa69e7 [17] SCHULMAN J, MORITZ P, LEVINE S, et al. High-dimensional continuous control using generalized advantage estimation[EB/OL]. (2018-10-20)[2025-2-20]. https://arxiv.org/abs/1506.02438. [18] BAO H, ZHU H. Modeling and trajectory tracking model predictive control novel method of AUV based on CFD data[J]. Sensors, 2022, 22(11): 4234. doi: 10.3390/s22114234 [19] QIAO L. 基于深度强化学习的多水下目标拦截策略研究[EB/OL]. [2024-12-23]. https://sjtu-mirus.github.io/MIRUS.github.io/research/MMI. -

 下载:
下载:

 点击查看大图
点击查看大图
计量
- 文章访问数: 779
- HTML全文浏览量: 229
- PDF下载量: 115
- 被引次数: 0





