

Unmanned Surface Vessel Cluster Path Planning Based on Deep Reinforcement Learning
-
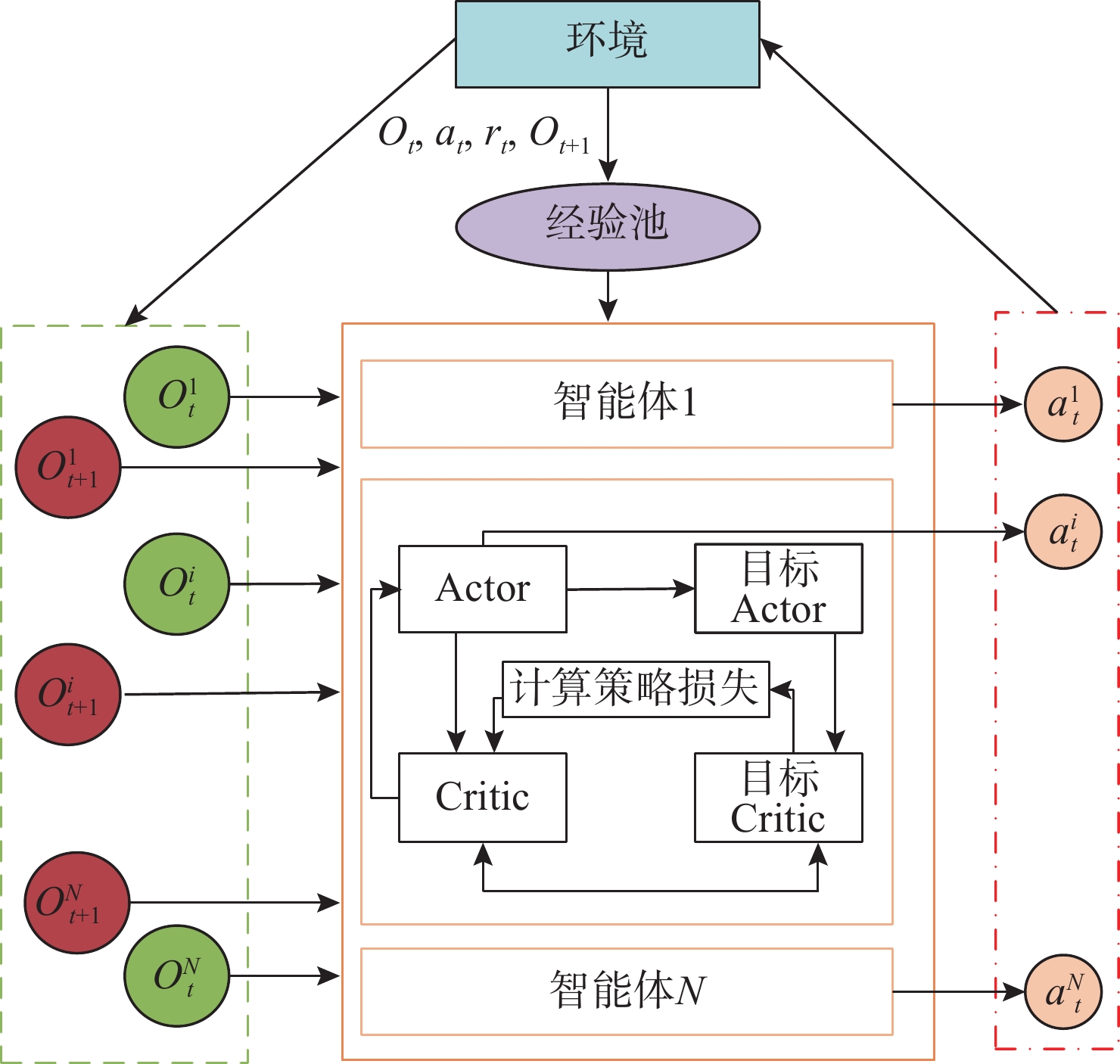
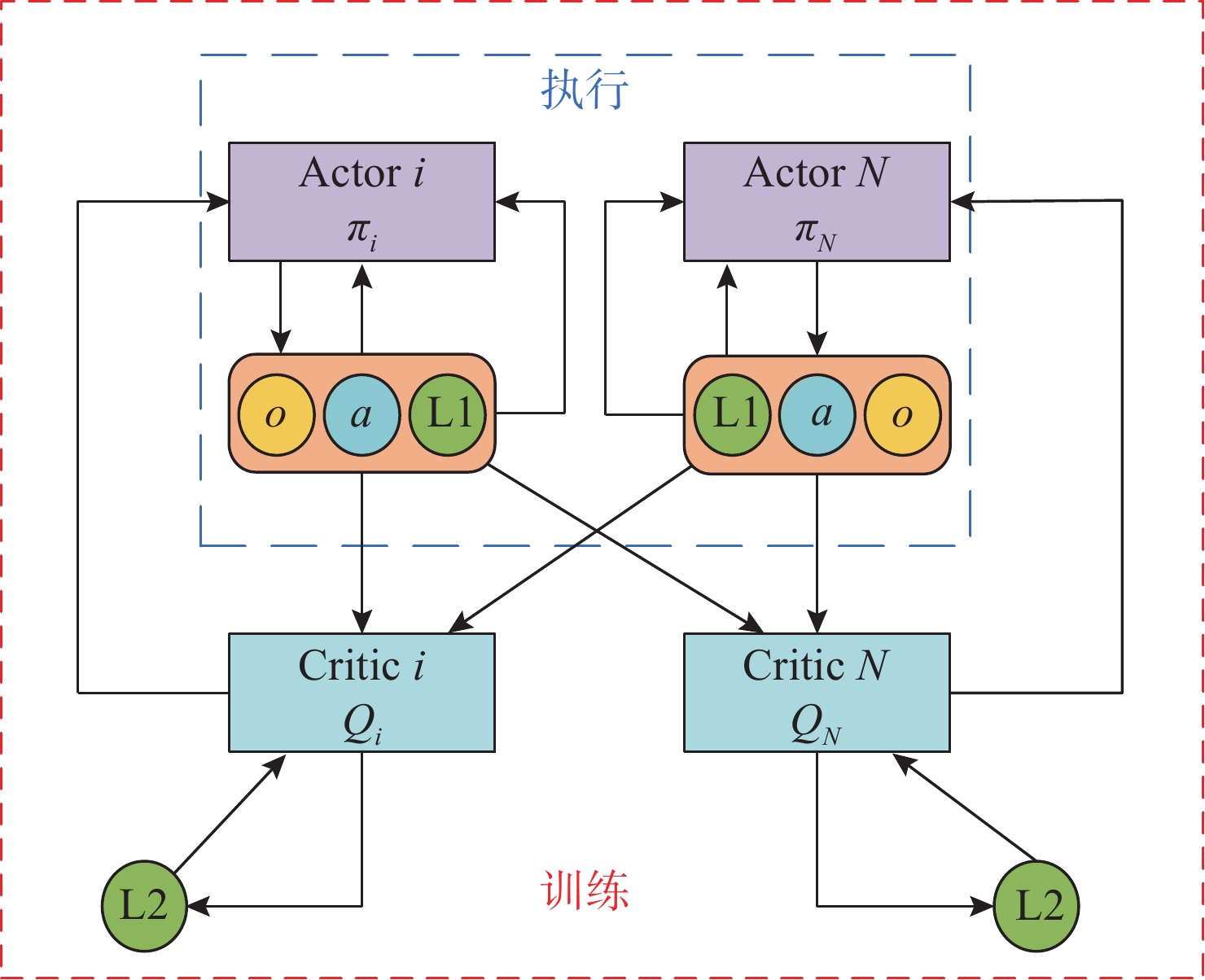
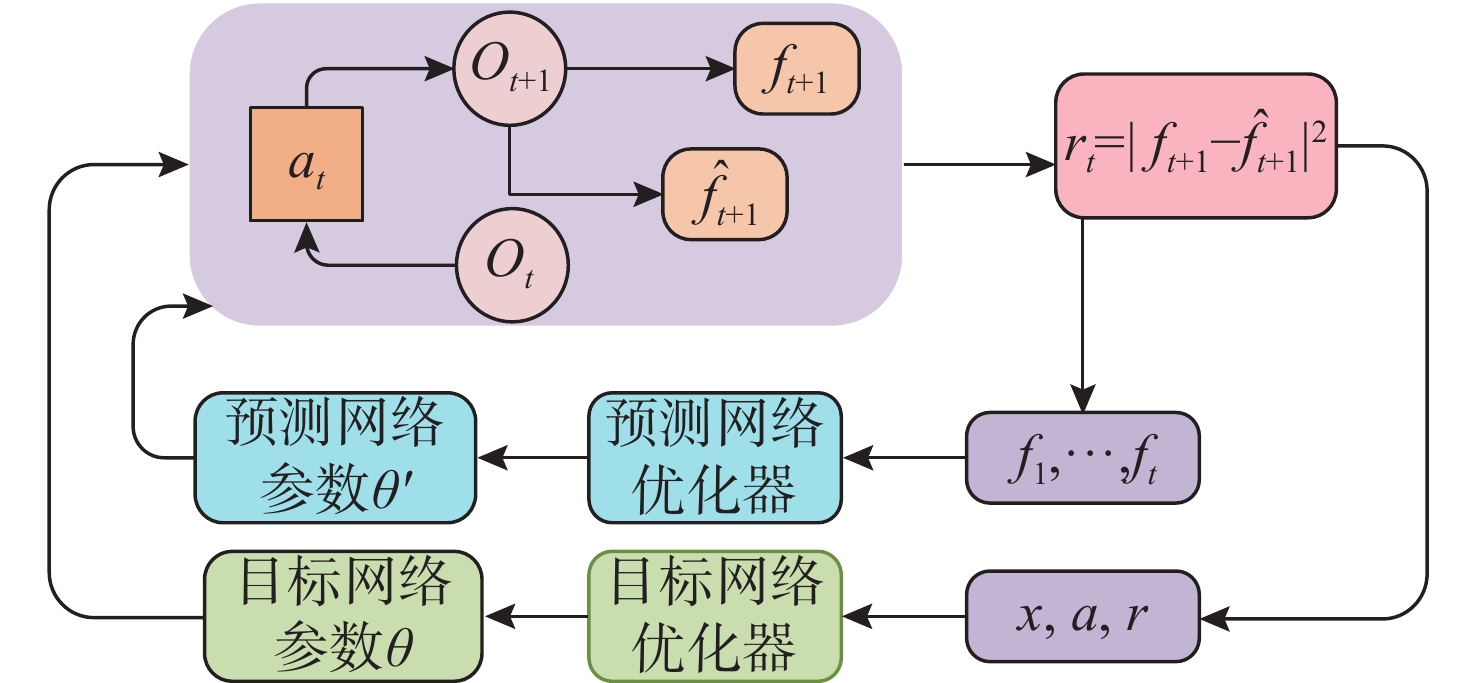
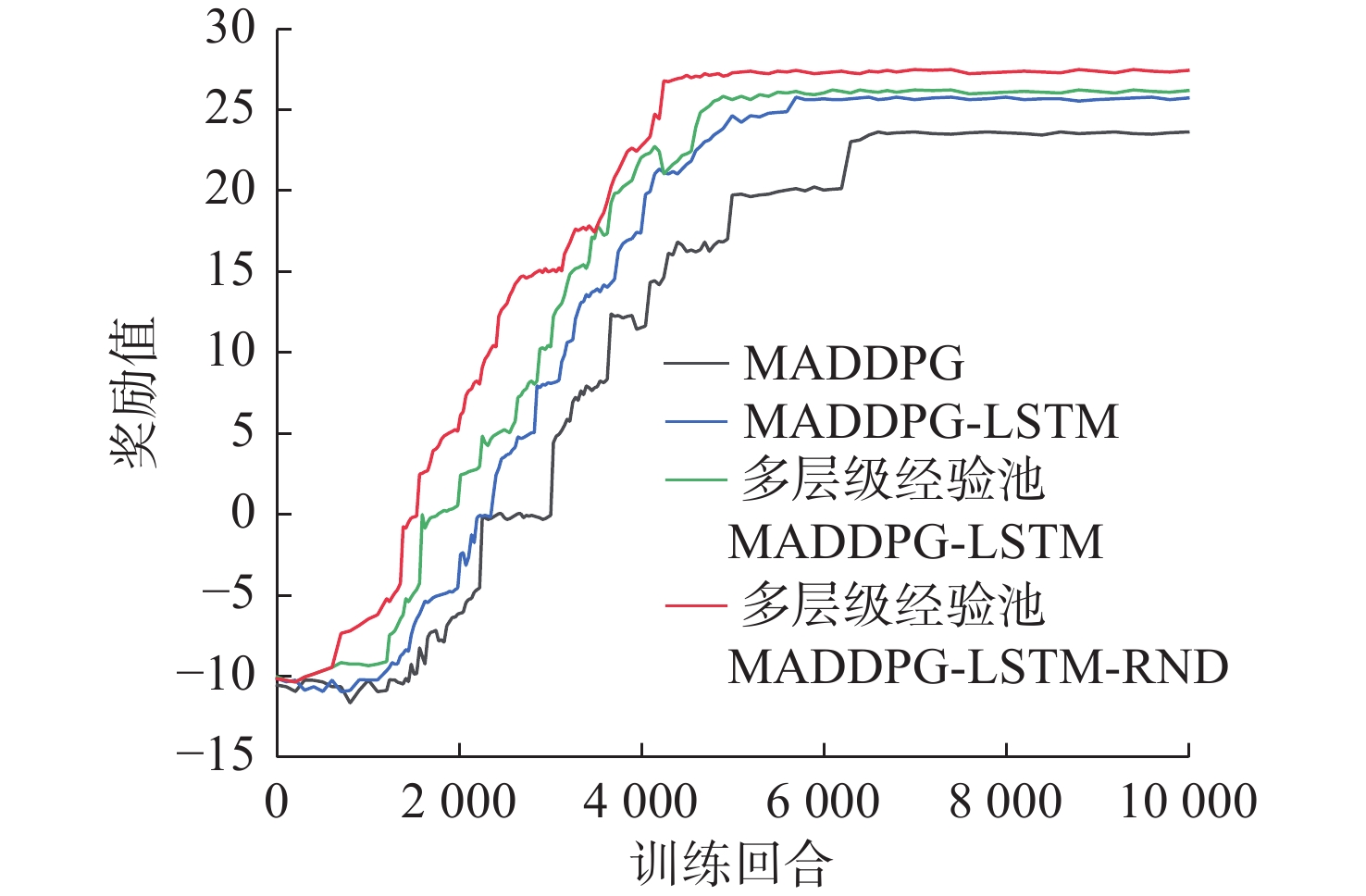
摘要: 随着无人艇(USV)在海上搜索领域的广泛应用, 传统的路径规划算法不能满足复杂的救援场景, 会导致局部最优、任务完成率低以及收敛速度慢等情况。为此, 提出了一种USV集群协同搜救的路径规划方法。首先, 基于多智能体深度确定性策略梯度算法引入长短期记忆模块, 增强USV对路径规划中时序信息的利用能力; 其次, 设计了多层级表征经验池, 提高训练效率和数据利用率, 减少不同经验间的干扰; 最后, 采用随机网络蒸馏作为好奇心机制, 为USV探索新区域提供内在奖励, 解决奖励稀疏导致的收敛问题。仿真实验结果表明, 改进后的算法与原始算法相比, 收敛速度提升了约38.46%, 路径长度也缩短了27.02%, 且避障能力上有显著提升。Abstract: With the wide application of unmanned surface vessels(USVs) in the field of maritime search, the traditional path planning algorithms fail to meet the complex rescue scenarios, which can lead to local optimum, low task completion rate, and slow convergence speed. For this reason, a path planning method for USV cluster cooperative search and rescue was proposed. Firstly, a long and short-term memory module was introduced based on the multi-agent deep deterministic policy gradient algorithm to enhance the ability of the USVs to utilize the temporal information in path planning; secondly, a multi-level representational experience pool was designed to improve the training efficiency and data utilization and reduce the interference between different experiences; finally, stochastic network distillation was used as a curiosity mechanism to provide intrinsic rewards for the USVs to explore new regions and solve the convergence due to the sparse rewards. The simulation experiment results show that the improved algorithm improves the convergence speed by about 38.46% compared with the original algorithm, and the path length has been shortened by 27.02%. In addition, the obstacle avoidance ability has been significantly improved.
-

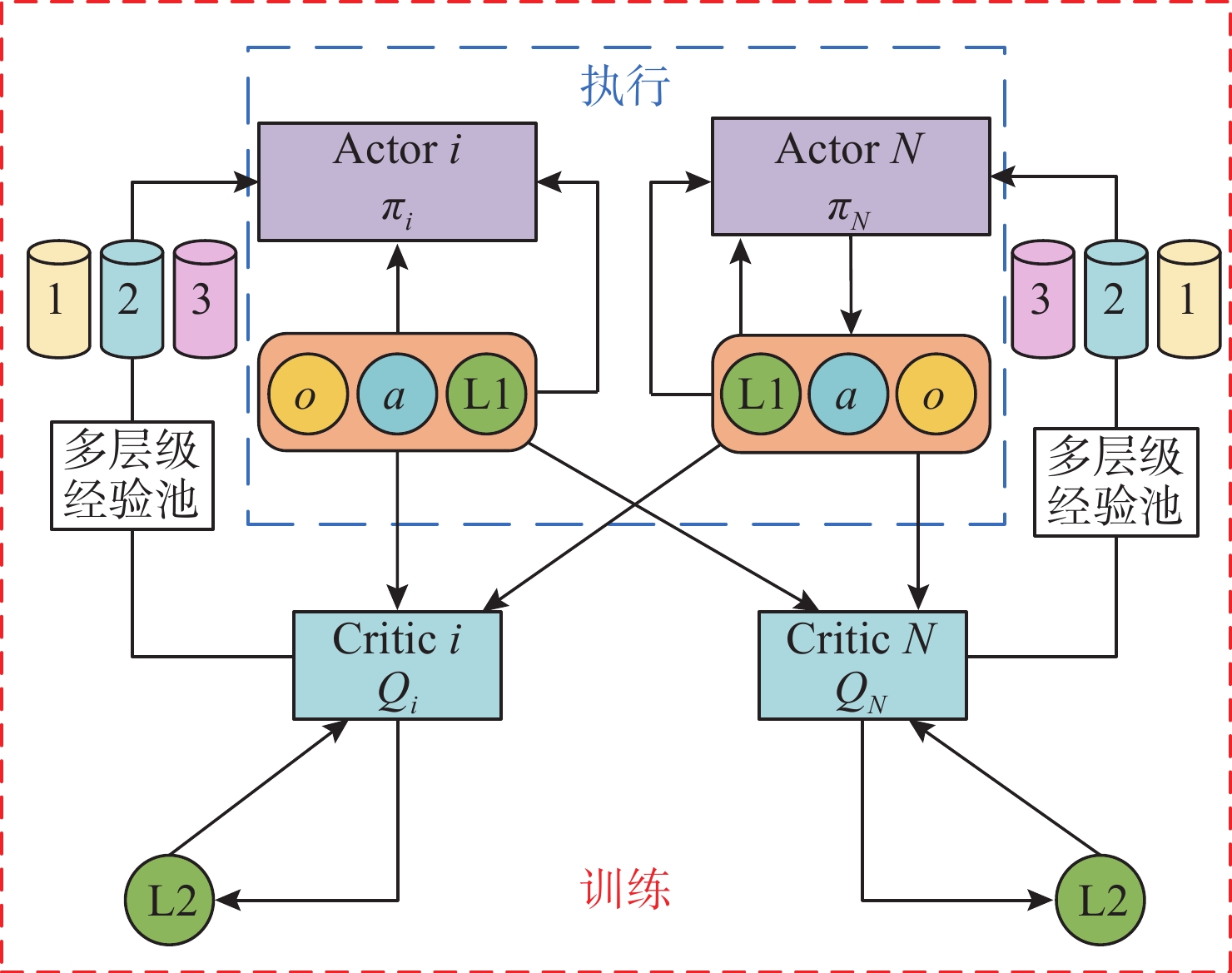
图 4 基于多层级经验池的MADDPG-LSTM算法框架
Figure 4. Framework of MADDPG-LSTM algorithm based on multi-level buffer pool

图 8 MADDPG-LSTM算法最大奖励时的路径
Figure 8. Path at maximum reward by the MADDPG-LSTM algorithm

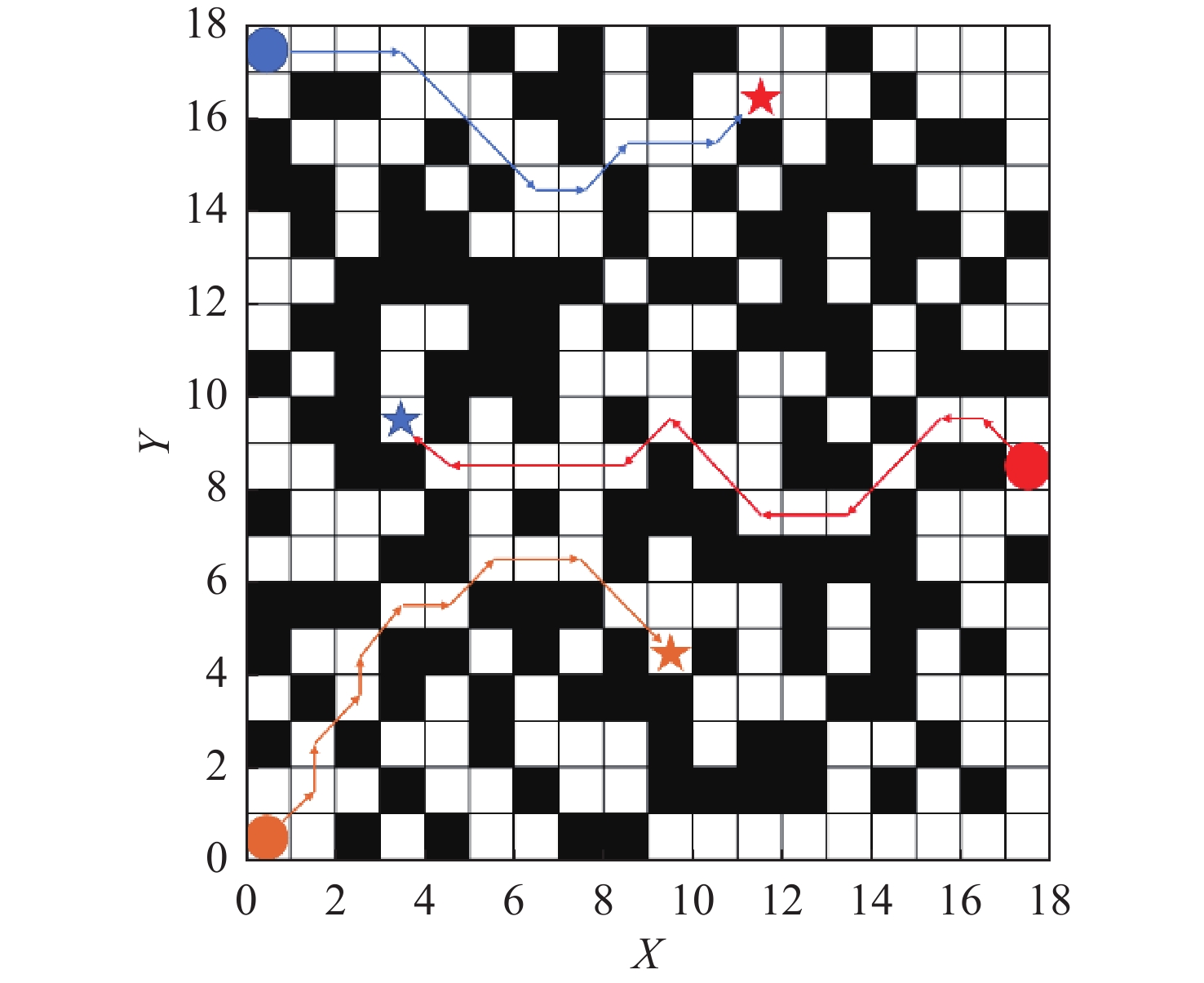
图 9 多层级经验池MADDPG-LSTM算法最大奖励时的路径
Figure 9. Path at maximum reward based on multi-level experience pool MADDPG-LSTM algorithm

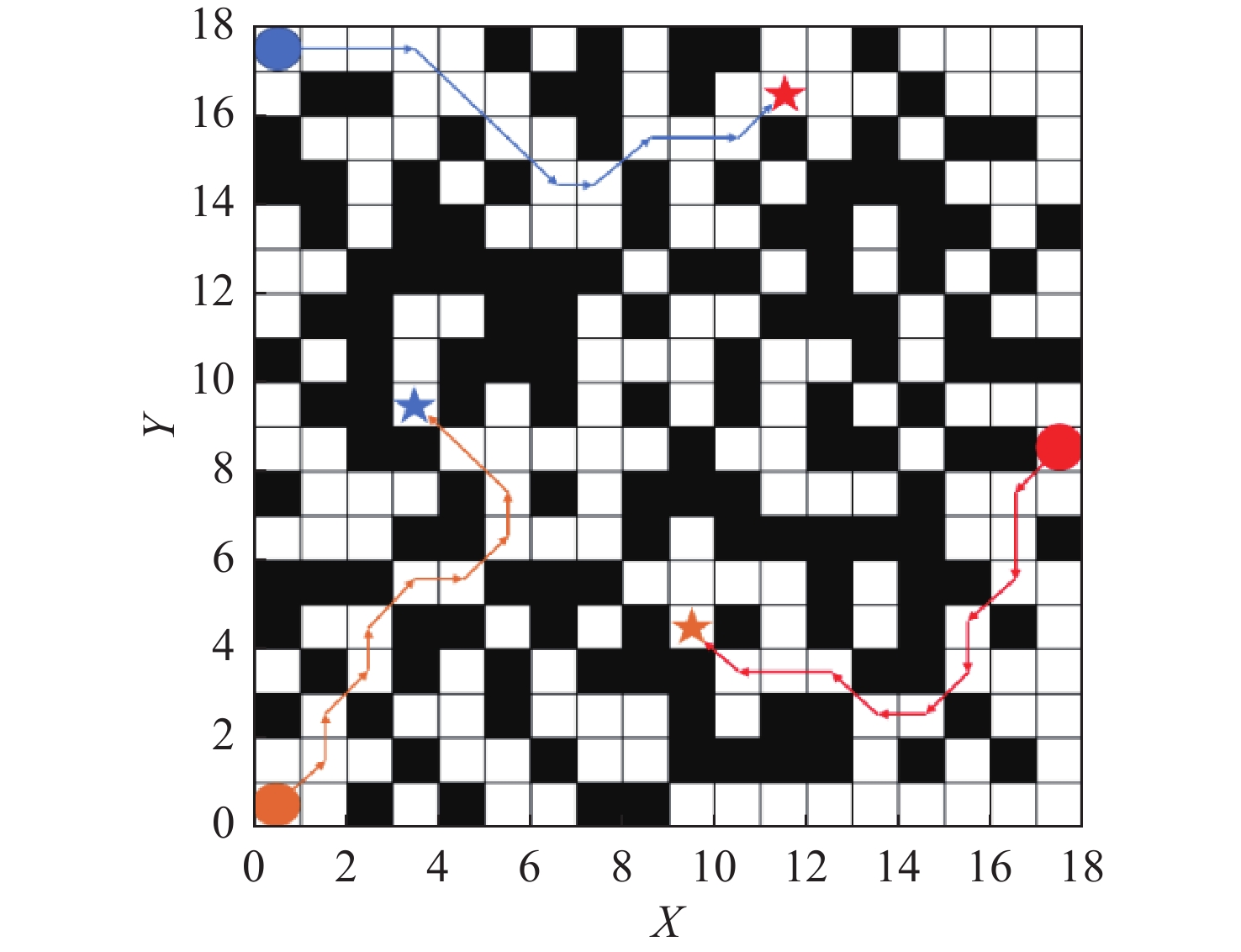
图 10 多层级经验池MADDPG-LSTM-RND算法最大奖励时的路径
Figure 10. Path at maximum reward based on multi-level experience pool MADDPG-LSTM-RND algorithm
表 1 实验超参数
Table 1. Experimental hyperparameters
参数名称 数值 经验池大小 10 000 Actor网络学习率 0.001 Critic网络学习率 0.001 训练回合数 10 000 批尺寸 1 024 折损因子γ 0.99 软更新系数$ \tau $ 0.01 每回合最大步数 100  下载: 导出CSV
下载: 导出CSV
表 2 不同算法规划最优路径性能表现
Table 2. Performance of different algorithms for planning out the optimal paths
算法 最大奖励值 到达所有目
标点收敛回合规划路径与障
碍物相邻次数转弯次数 到达所有目
标点总步数MADDPG 23.25 6 500 82 25 18.5 MADDPG-LSTM 25.85 5 500 73 20 21.0 多层级经验池
MADDPG-LSTM26.25 4 500 65 20 17.5 多层级经验池
MADDPG-LSTM-RND27.45 4 000 53 21 13.5
下载: 导出CSV
-
[1] 肖乾治, 陈大力, 殷昭鲁. 新时代发展海洋经济建设海洋强国思考[J]. 商业经济, 2023(8): 5-7. doi: 10.3969/j.issn.1009-6043.2023.08.003 [2] 费陈, 贺拥亮, 赵亮, 等. 面向海上复杂环境的无人艇集群航迹规划发展综述[J]. 电讯技术, 2024, 11(3): 1-11. [3] 陈羽, 褚天仁. 水面无人艇路径规划研究现状[J]. 科技创新与应用, 2024, 14(6): 84-87. [4] 唐杭斌. 水面无人艇研究现状与发展趋势[J]. 船舶物资与市场, 2020(3): 13-14. [5] CHU Y J, GAO Q Z, YUE Y, et al. Evolution of unmanned surface vehicle path planning: A comprehensive review of basic, responsive, and advanced strategic pathfinders[J]. Drones, 2024, 8(10): 540. doi: 10.3390/drones8100540 [6] 王秀玲, 尹勇, 赵延杰, 等. 无人艇海上搜救路径规划技术综述[J]. 船舶工程, 2023, 45(4): 50-57.WANG X L, YIN Y, ZHAO Y J, et al. Overview of USV maritime search and rescue path planning technology[J]. Ship Engineering, 2023, 45(4): 50-57. [7] DIJKSTRA E W. A note on two problems in connexion with graphs[J]. Numerische Mathematik, 1959, 1(1): 269-271. doi: 10.1007/BF01386390 [8] HART P E, NILSSON N J, RAPHAEL B. A formal basis for the heuristic determination of minimum cost paths[J]. IEEE transactions on Systems Science and Cybernetics, 1968, 4(2): 100-107. doi: 10.1109/TSSC.1968.300136 [9] HOLLAND J H. Adaptation in natural and artificial systems: An introductory analysis with applications to biology, control, and artificial intelligence[M]. Cambridge, USA: MIT Press, 1992. [10] DORIGO M, DI CARO G, GAMBARDELLA L M. Ant algorithms for discrete optimization[J]. Artificial Life, 1999, 5(2): 137-172. doi: 10.1162/106454699568728 [11] RAIBAIL M, RAHMAN A H, AL-ANIZY G J, et al. Decentralized multi-robot collision avoidance: A systematic review from 2015 to 2021[J]. Symmetr, 2022, 14(3): 610. doi: 10.3390/sym14030610 [12] LI Y, LI X W, WEI X W, et al. Sim-real joint experimental verification for an unmanned surface vehicle formation strategy based on multi-agent deterministic policy gradient and line of sight guidance[J]. Ocean Engineering, 2023, 270: 113661. doi: 10.1016/j.oceaneng.2023.113661 [13] LOWEN R, WU Y, TAMAR A, et al. Multi-agent actor-critic for mixed cooperative-competitive environments [C]//Proc of the 31st Int Conf on Neural Information Processing Systems. Cambridge, USA: MIT, 2017: 6382-6393. [14] 王思琪, 关巍, 佟敏, 等. 基于ATMADDPG算法的多水面无人航行器编队导航[J]. 吉林大学学报(信息科学版), 2024, 42(4): 588-599.WANG S Q, GUAN W, TONG M, et al. Formation navigation of multi-unmanned surface vehicles based on ATMADDPG algorithm[J]. Journal of Jilin University (Information Science Edition), 2024, 42(4): 588-599. [15] 刘鹏, 赵建新, 张宏映, 等. 基于改进型MADDPG的多智能体对抗策略算法[J]. 火力与指挥, 2023, 48(3): 132-138.LIU P, ZHAO J X, ZHANG H Y, et al. Multi-agent confrontation strategy algorithm based on improved MADDPG[J]. Fire Control & Command Control, 2023, 48(3): 132-138. [16] LU R Z, HONG S. Incentive-based demand response for smart grid with reinforcement learning and deep neural network[J]. Applied Energy, 2019, 236: 937-949. doi: 10.1016/j.apenergy.2018.12.061 -

 下载:
下载:




 点击查看大图
点击查看大图
计量
- 文章访问数: 1008
- HTML全文浏览量: 418
- PDF下载量: 150
- 被引次数: 0





