

A Sonar Image Target Detection Method with Low False Alarm Rate Based on Self-Trained YOLO11 Model
-
摘要: 声呐图像目标自主检测作为水下无人系统的关键技术, 在实际应用中面临着虚警率高的挑战, 制约了其在水下无人系统中执行任务的质量和效率。为解决这一问题, 文中设计了一种基于YOLO11模型的水下目标检测方法, 为降低其虚警率, 提出采用通过在声呐图像上自训练深度学习检测器的虚警率检测方法。该方法依据声呐图像目标检测数据集自动生成代理分类任务, 通过预训练提高深度学习检测器对目标和背景特征的学习效果, 从而提升检测器对目标和背景的分辨能力,有效降低虚警率。实测结果表明, 在检测器置信各自取F1-score最大值对应的数值时, 文中方法训练得到的YOLO11检测器相较于传统的迁移学习方法,虚警率降低了11.60%, 且具有更高的召回率。该方法在不使用外部数据集的条件下,显著提升了深度学习检测器的泛化性, 为水下小样本目标检测场景提供了一种高效的自训练方式。Abstract: Autonomous detection of sonar image targets is a key technology for unmanned undersea systems, but it faces the challenge of high false alarm rates in practical applications, which limits the quality and efficiency of mission execution by unmanned underwater systems. In this paper, an underwater target detection method based on the YOLO11 model was designed, and a false alarm rate detection method by self-training a deep learning detector on sonar images was proposed to reduce the false alarm rate. This method automatically generated proxy classification tasks based on the sonar image target detection dataset and improved the deep learning detector’s learning of target and background features through pre-training, enhancing the detector’s ability to distinguish between targets and backgrounds and thereby reducing the false alarm rate. Experimental results demonstrate that when the detector’s confidence is set to the value corresponding to the maximum F1-score, the YOLO11 detector trained using the proposed method can reduce the false alarm rate by 11.60% compared to traditional transfer learning methods while achieving a higher recall rate. This method improves the generalization of the deep learning detector without using external datasets, providing an efficient self-training approach for underwater target detection scenarios with small sample sizes.
-
Key words:
- underwater target detection /
- false alarm rate /
- sonar image processing /
- deep learning
-
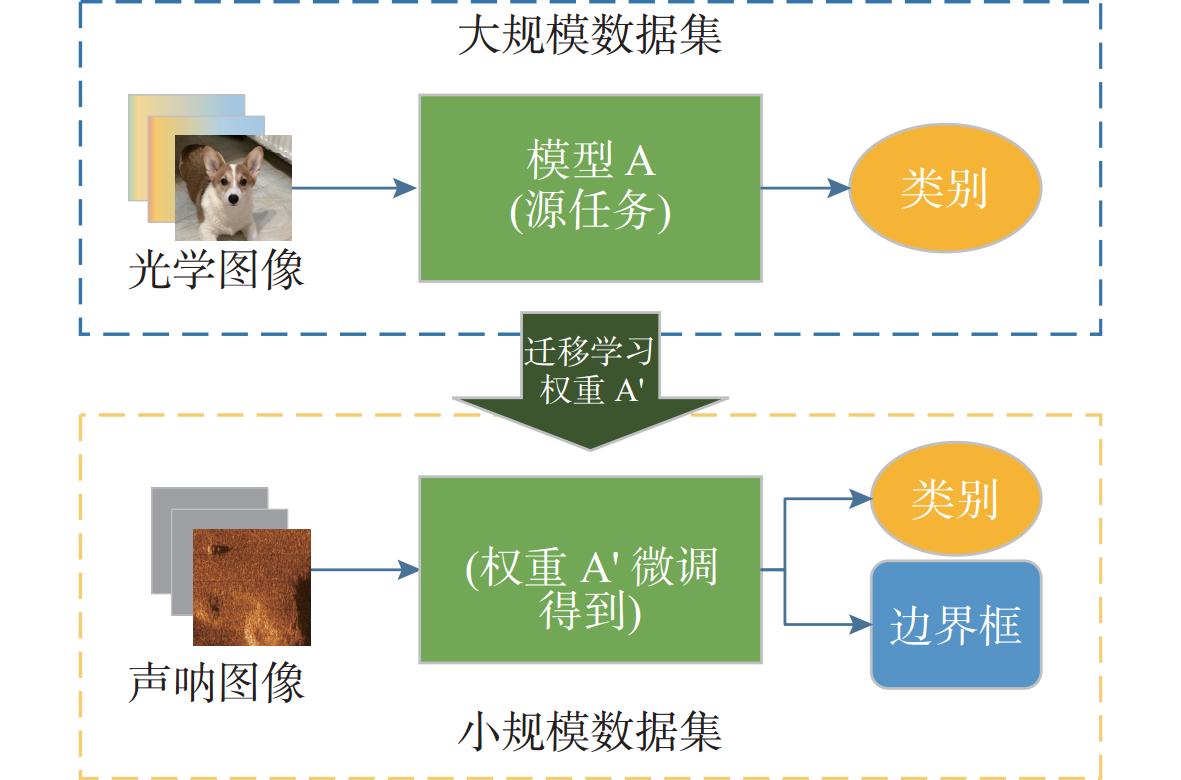
图 1 声呐图像目标检测中基于大规模光学图像数据集的预训练检测范式
Figure 1. Pre-trained detection paradigm for sonar image target detection based on large-scale optical image datasets
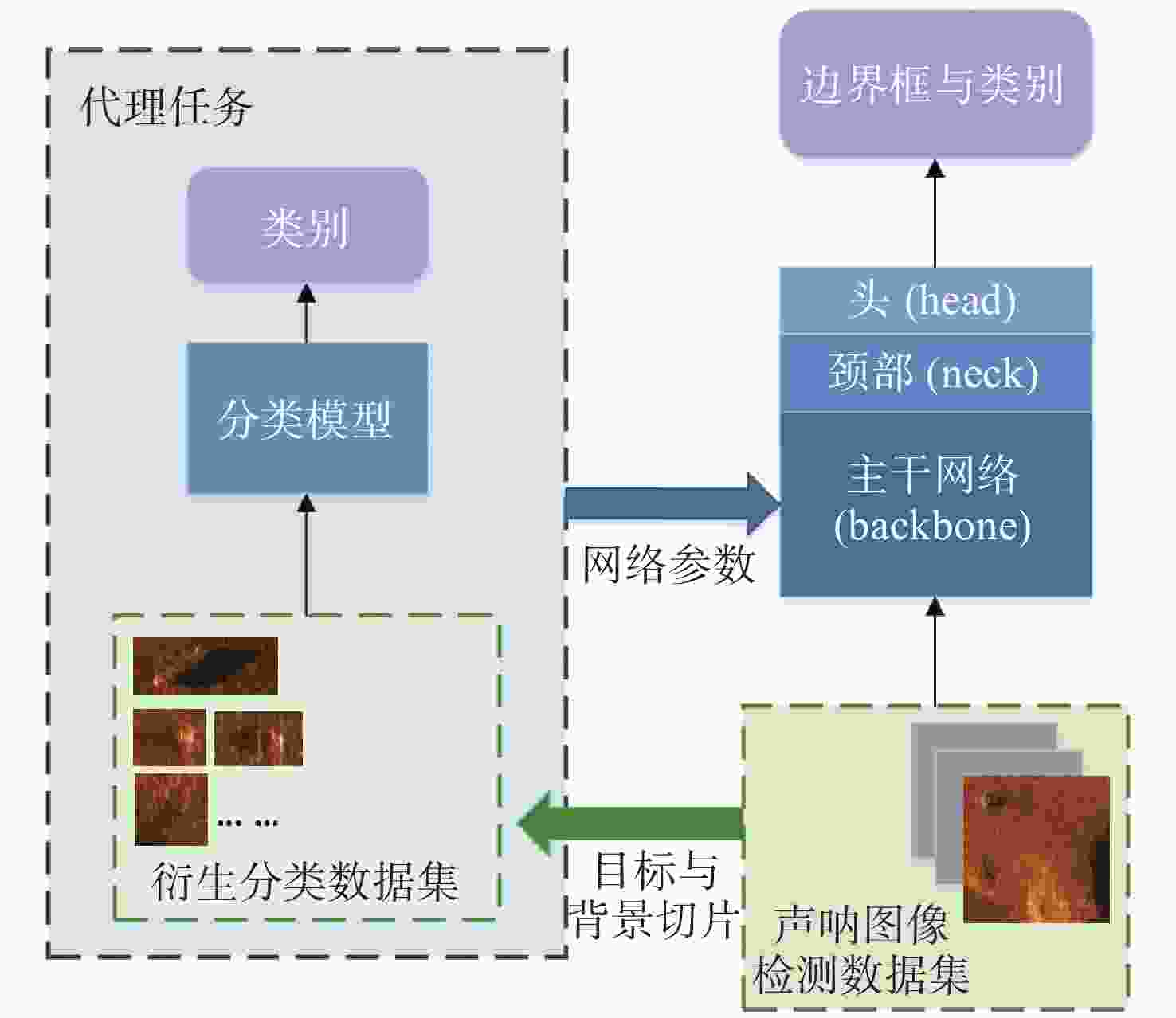
图 3 基于代理分类任务的深度学习目标检测器整体结构
Figure 3. Structure of a deep learning object detector based on proxy classification tasks
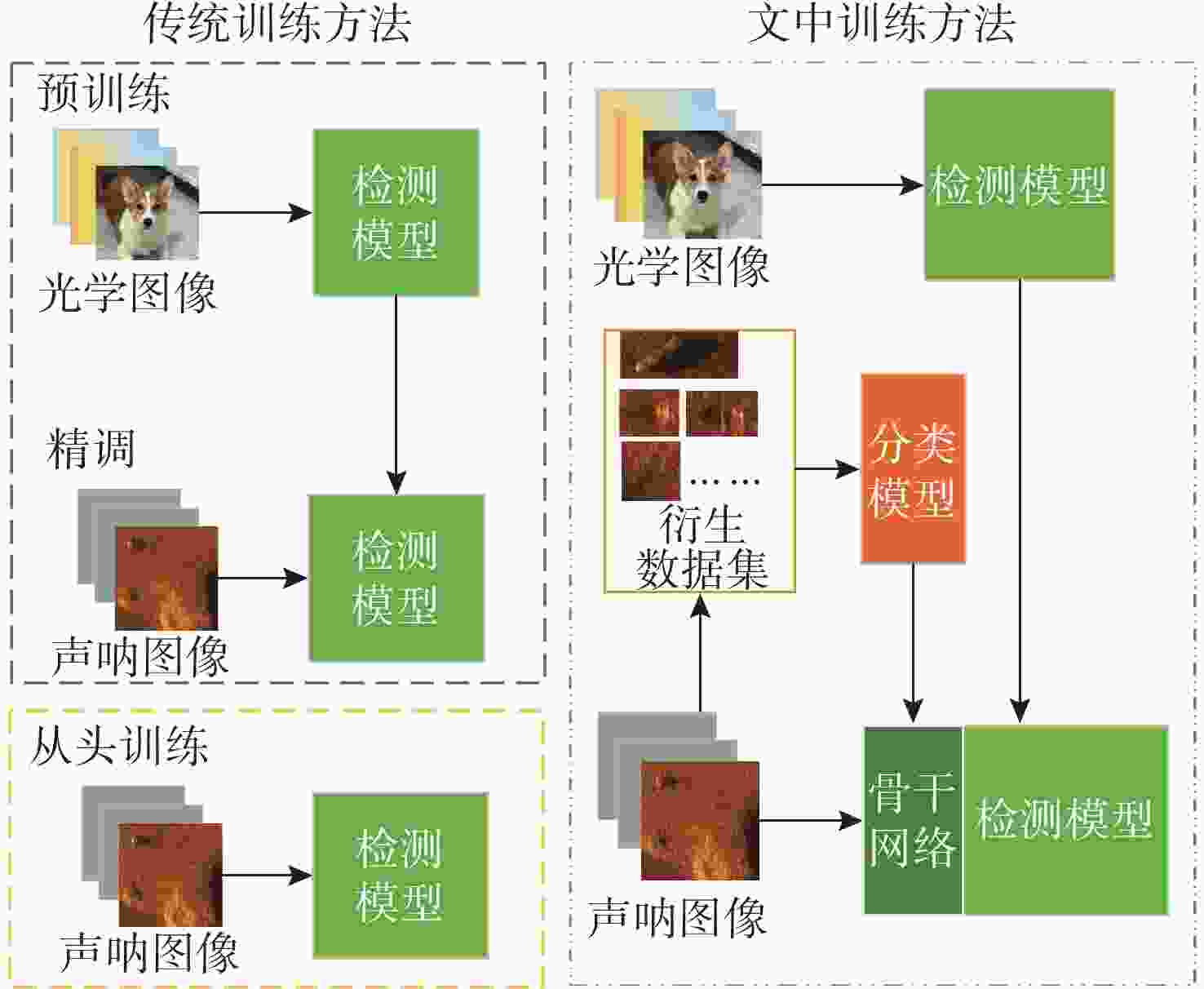
图 7 文中训练方法与传统训练方法对比
Figure 7. Comparison diagram of the training method in this article and the traditional training method
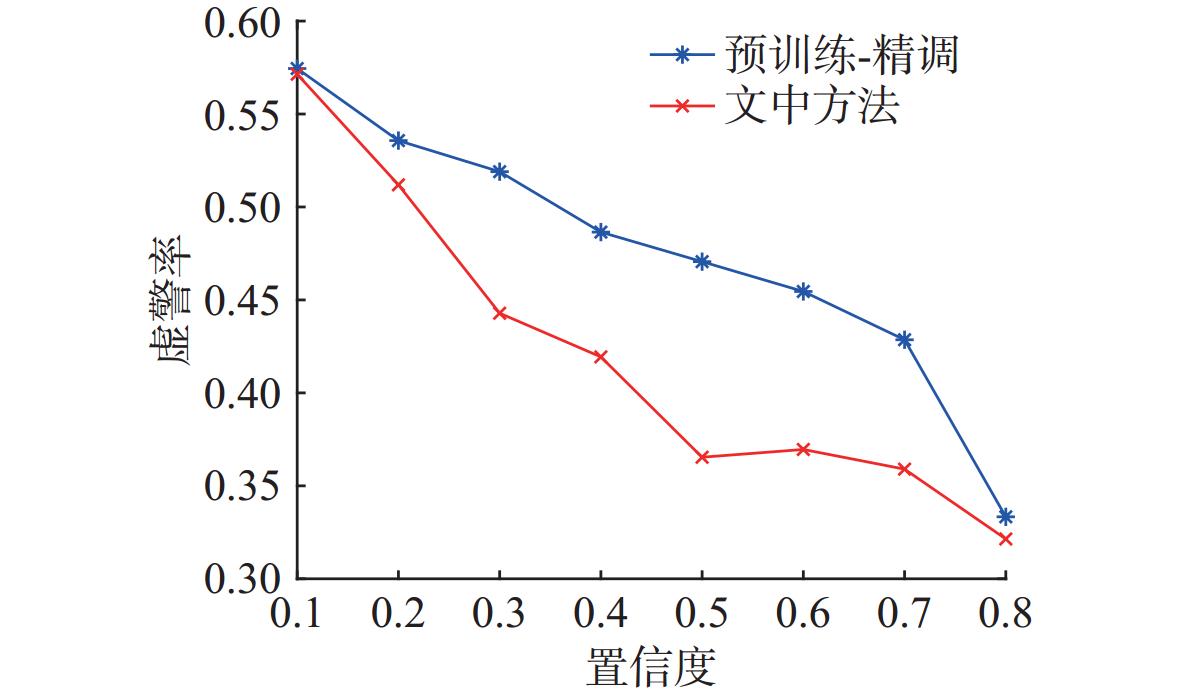
图 11 不同训练方法下YOLO11模型虚警率对比
Figure 11. Comparison of false alarm rates under different training methods for the YOLO11 model
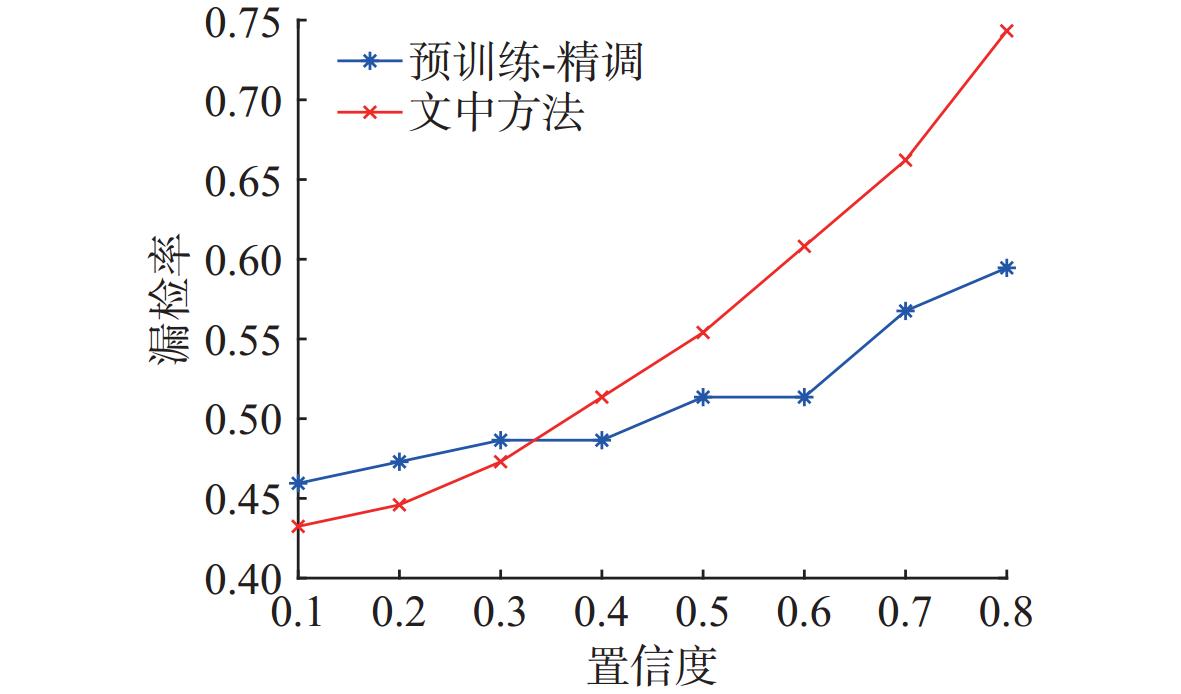
图 12 不同训练方法下YOLO11模型漏检率对比
Figure 12. Comparison of miss rate under different training methods for the YOLO11 model
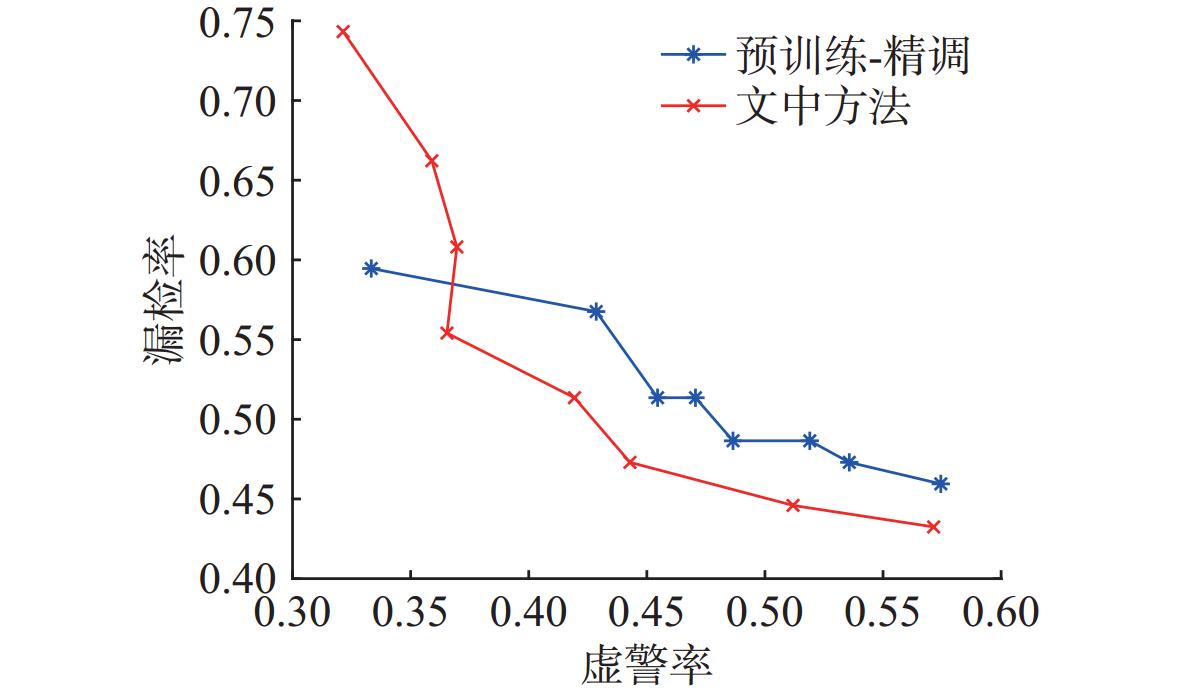
图 13 不同训练方法下YOLO11模型漏检率-虚警率曲线
Figure 13. Miss rate versus false alarm rate curves for the YOLO11 model under different training methods
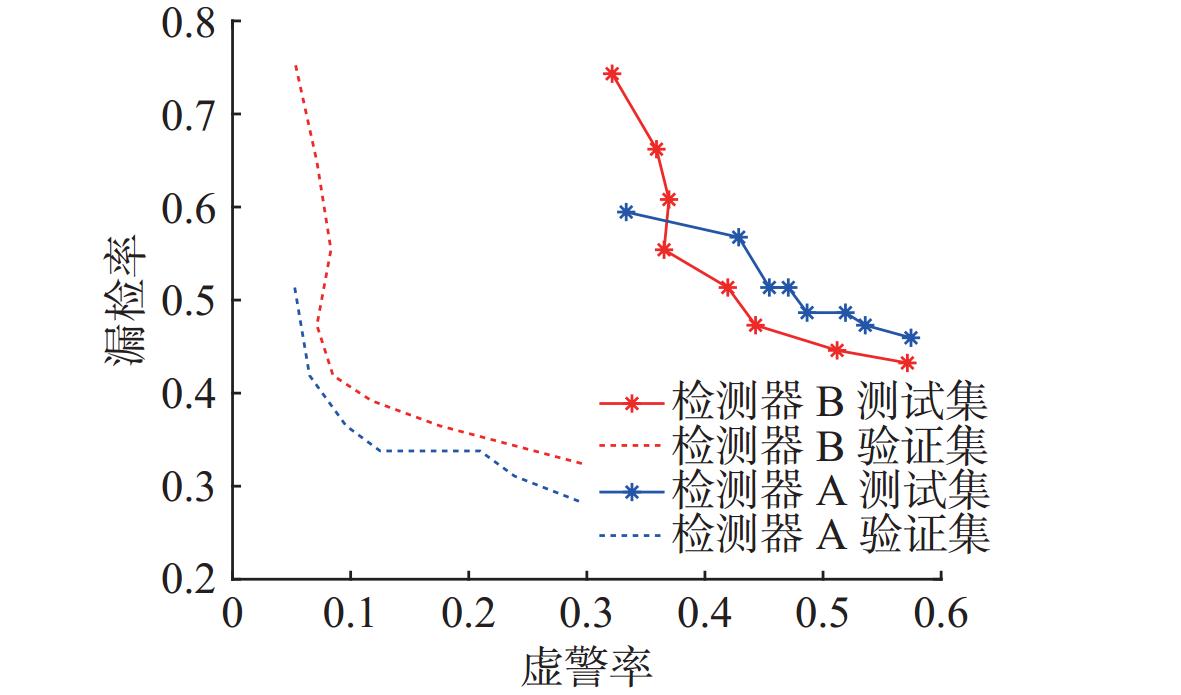
图 14 不同训练方法下YOLO11模型检测器在测试集和验证集上的检测表现对比
Figure 14. Comparison of detection performance of YOLO11 model's detectors on the test set and validation set under different training methods
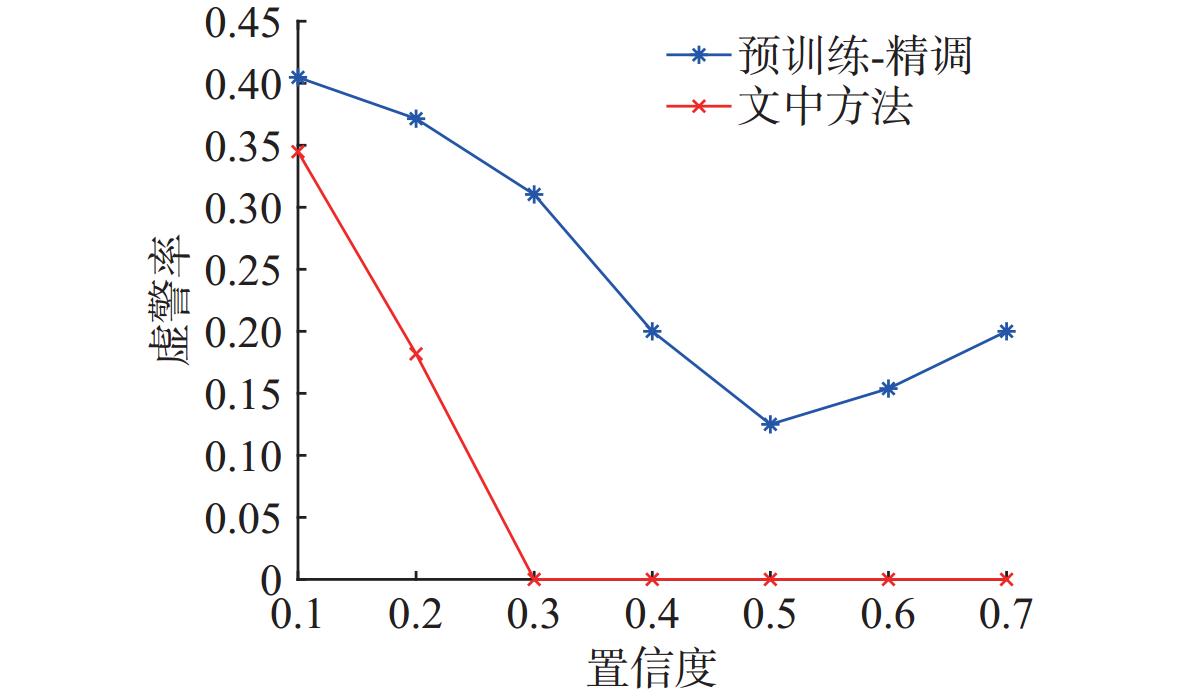
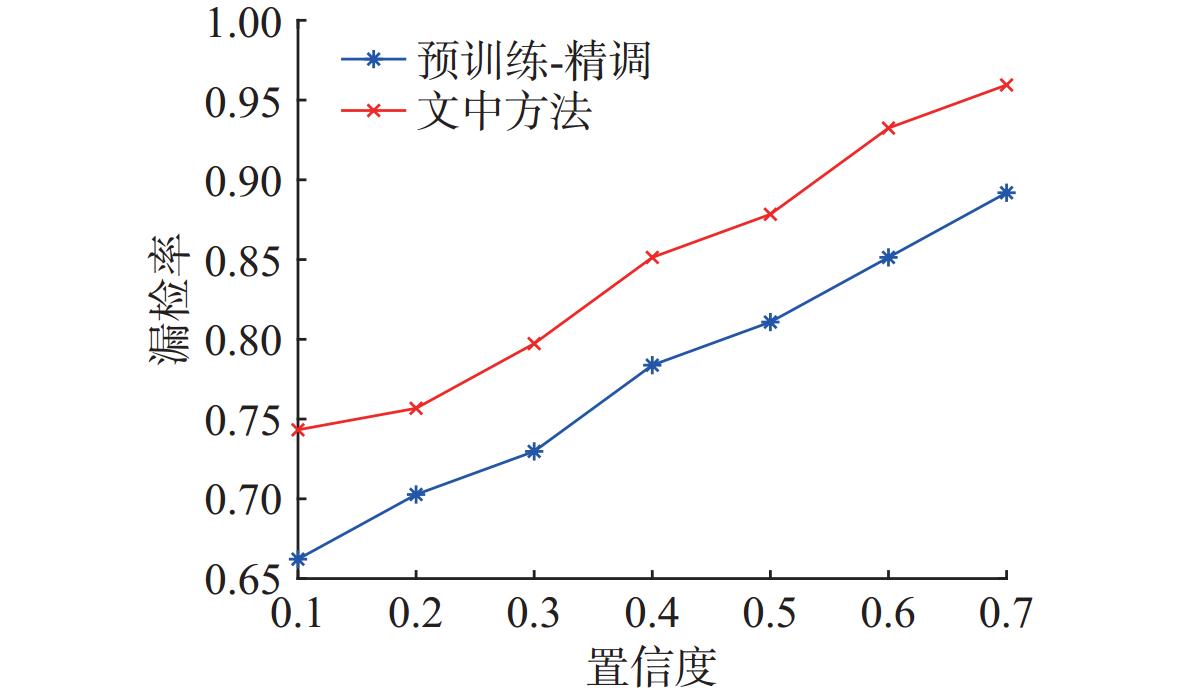
图 15 不同训练方法下YOLO11模型检测器在加噪测试集上的虚警率对比
Figure 15. Comparison of false alarm rates for detectors trained under different methods for the YOLO11 model on a noisy test set
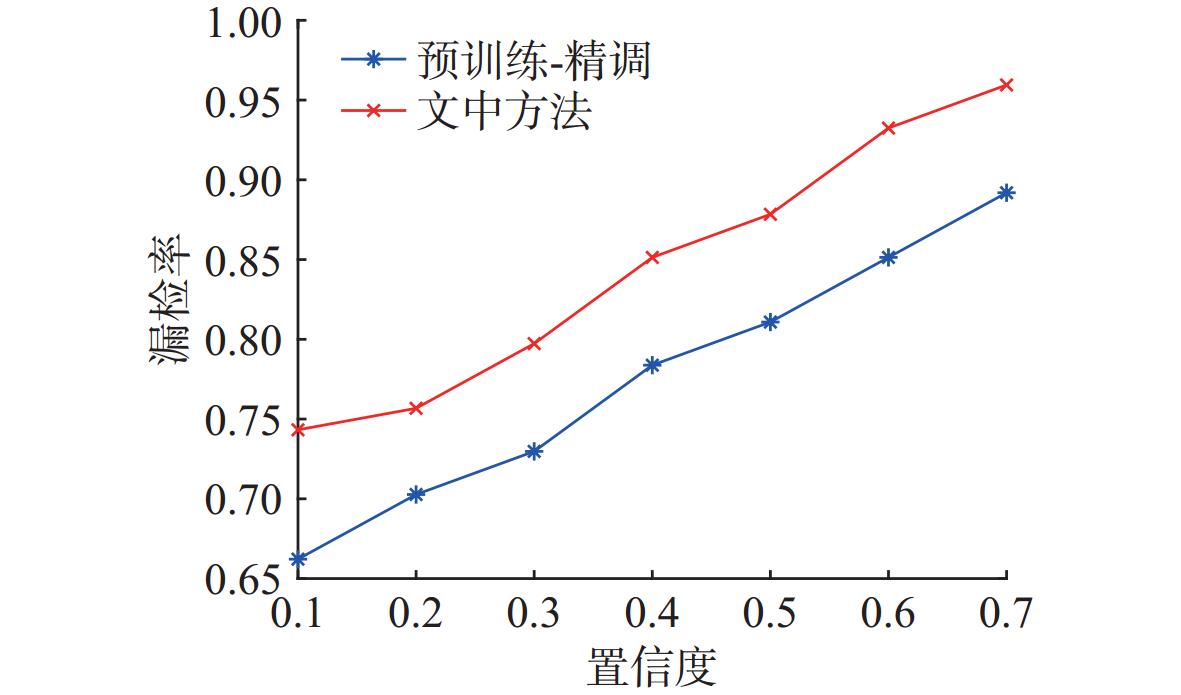
图 16 不同训练方法下YOLO11模型检测器在加噪测试集上的漏检率对比
Figure 16. Comparison of miss rates for detectors trained under different methods for the YOLO11 model on a noisy test set
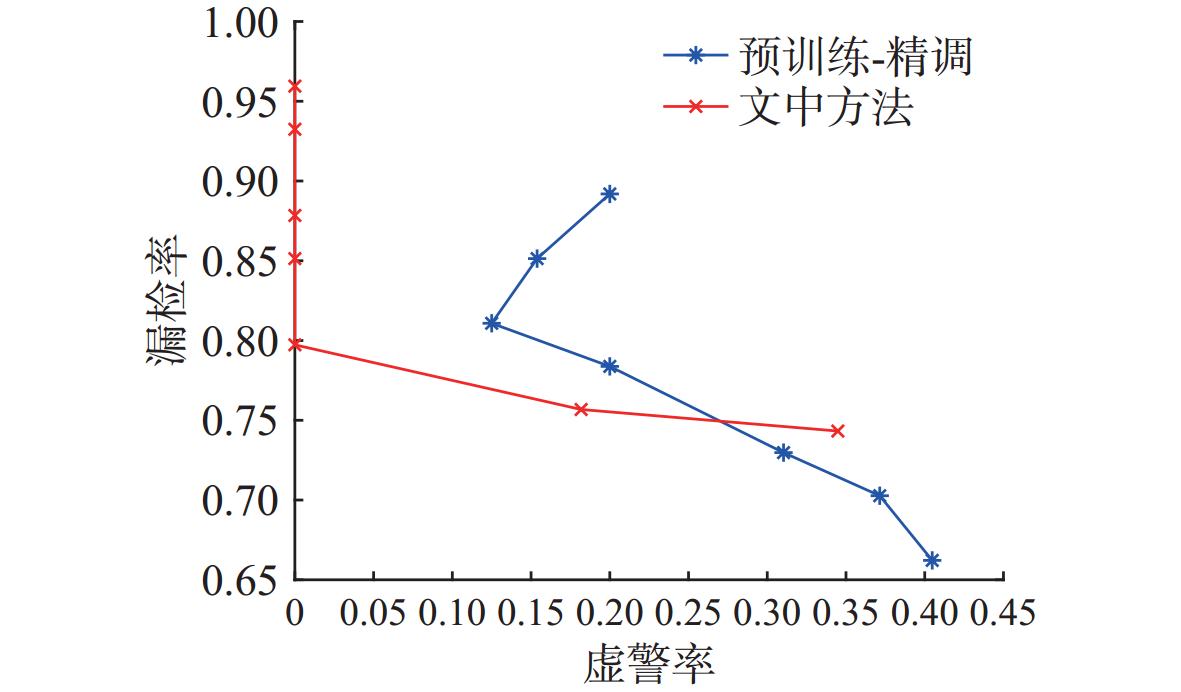
图 17 不同训练方法下YOLO11模型检测器在加噪测试集上的漏检率-虚警率曲线
Figure 17. Miss rate-false alarm rate curves of detectors under different training methods for the YOLO11 model on a noisy test set
表 1 检测器mAP对比
Table 1. mAP Comparison for Detectors
训练方法 mAP@0.5 mAP@0.5∶0.95 “预训练-精调” 0.799 0.441 文中方法 0.747 0.401  下载: 导出CSV
下载: 导出CSV
表 2 检测器F1-score与虚警率对比
Table 2. F1 score and false alarm rates comparison for detectors
训练方法 F1-score $ {P_{f{a_\_T}}} $ $ \overline {{P_{fa}}} $ T “预训练-精调” 0.78 0.5366 0.4753 0.231 文中方法 0.67 0.4744 0.4201 0.237
下载: 导出CSV
-
[1] LAW H, DENG J. CornerNet: Detecting objects as paired keypoints[J]. International Journal of Computer Vision. 2020, 128(3): 642-656. [2] BARHOUMI C, BENAYED Y. Real-time speech emotion recognition using deep learning and data augmentation[J]. Artificial Intelligence Review. 2025, 58: 49. [3] SHAO Y, ZHANG D, CHU H, et al. A review of YOLO object detection based on deep learning[J]. Journal of Electronics and Information Technology, 2022, 44(10): 3697-3708. [4] ZHANG P, TANG J, ZHONG H, et al. Self-trained target detection of radar and sonar images using automatic deep learning[J]. IEEE Transactions on Geoscience and Remote Sensing, 2022, 60(1): 1-14. [5] HUO G, WU Z, LI J. Underwater object classification in sidescan sonar images using deep transfer learning and semisynthetic training data[J]. IEEE Access, 2020, 8: 47407-47418. doi: 10.1109/ACCESS.2020.2978880 [6] WILLIAMS D. P. Underwater target classification in synthetic aperture sonar imagery using deep convolutional neural networks[C]//2016 23rd International Conference on Pattern Recognition(ICPR). Cancun, Mexico: ICPR, 2016: 2497-2502. [7] WANG X, JIAO J, YIN J, et al. Underwater sonar image classification using adaptive weights convolutional neural network[J]. Applied Acoustics, 2019, 146: 145-154. doi: 10.1016/j.apacoust.2018.11.003 [8] JOCHER G, QIU J. Ultralytics YOLO11[CP/OL]. (2024) [2025-01-30]. https://github.com/ultralytics/ultralytics . [9] LI Z, CHEN D, YIP T, et al. Sparsity regularization-based real-time target recognition for side scan sonar with embedded GPU[J]. Journal of Marine Science and Engineering, 2023, 11(3): 487. [10] CHEN Z, XIE G, DENG X, et al. DA-YOLOv7: A deep learning-driven high-performance underwater sonar image target recognition model[J]. Journal of Marine Science and Engineering, 2024, 12(9): 1606. doi: 10.3390/jmse12091606 [11] ZHENG K, LIANG H, ZHAO H, et al. Application and analysis of the MFF-YOLOv7 model in underwater sonar image target detection[J]. Journal of Marine Science and Engineering, 2024, 12(12): 2326. [12] KARIMANZIRA D, RENKEWITZ H, SHEA D, et al. Object detection in sonar images[J]. Electronics, 2020, 9(7): 1180. [13] 王闰成. 侧扫声呐图像变形现象与实例分析[J]. 海洋测绘, 2002(5): 42-45. doi: 10.3969/j.issn.1671-3044.2002.05.011WANG R C. Analysis of distortion phenomena and case studies in side-scan sonar images[J]. Hydrographic Surveying and Charting, 2002(5): 42-45. doi: 10.3969/j.issn.1671-3044.2002.05.011 [14] HOŻYŃ S. A review of underwater mine detection and classification in sonar imagery[J]. Electronics, 2021, 10(23): 2943. [15] PALOMERAS N, FURFARO T, WILLIAMS D P, et al. Automatic target recognition for mine countermeasure missions using forward-looking sonar data[J]. IEEE Journal of Oceanic Engineering, 2022, 47(1):141-161. [16] SONG Y, HE B, LIU P. Real-time object detection for AUVs using self-cascaded convolutional neural networks[J]. IEEE Journal of Oceanic Engineering, 2021, 46(1): 56-67. doi: 10.1109/JOE.2019.2950974 [17] MA Q, JIANG L, YU W, et al. Training with noise adversarial network: A generalization method for object detection on sonar image[C]//IEEE Winter Conference on Applications of Computer Vision. Snowmass Village, CO, USA, 2020: 718-727. [18] HUANG C, ZHAO J, ZHANG H, et al. Seg2Sonar: A full-class sample synthesis method applied to underwater sonar image target detection, recognition, and segmentation tasks[J]. IEEE Transactions on Geoscience and Remote Sensing, 2024, 62: 1-19. [19] YU Y, ZHAO J, GONG Q, et al. Real-time underwater maritime object detection in side-scan sonar images based on transformer-YOLOv5[J]. Remote Sensing, 2021, 13(18): 3555. [20] DENG J, DONG W, SOCHER R, et al. ImageNet: A large-scale hierarchical image database[C]//2009 IEEE Conference on Computer Vision and Pattern Recognition. Miami, FL, USA: IEEE, 2009: 248-255. [21] FERREIRA F, MACHADO D, FERRI G, et al. Underwater optical and acoustic imaging: A time for fusion? A brief overview of the state-of-the-art[C]//OCEANS 2016 MTS/IEEE Monterey. Monterey, California, USA: IEEE, 2016:1-6. [22] REED S, PETILLOT Y, BELL J. Automated approach to classification of mine-like objects in sidescan sonar using highlight and shadow information[J]. Radar, Sonar and Navigation, 2004, 151: 48-56. [23] JOCHER G, CHAURASIA A, QIU J. Ultralytics YOLOv8[CP/OL]. [2025-01-30]. https://github.com/ultralytics/ultralytics. [24] JOCHER G. Ultralytics YOLOv5[CP/OL]. [2025-01-30]. https://github.com/ultralytics/yolov5. [25] WANG A, CHEN H, LIU L, et al. YOLOv10: real-time end-to-end object detection[EB/OL]. (2024-10-30)[2025-01-30]. https://arxiv.org/abs/2405.14458. [26] REN S, HE K, GIRSHICK R, et al. Faster R-CNN: Towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2017, 39(6): 1137-1149. -

 下载:
下载:
















 点击查看大图
点击查看大图
计量
- 文章访问数: 1538
- HTML全文浏览量: 365
- PDF下载量: 127
- 被引次数: 0





