

Research on Game Confrontation of Unmanned Surface Vehicles Swarm Based on Multi-Agent Deep Reinforcement Learning
-
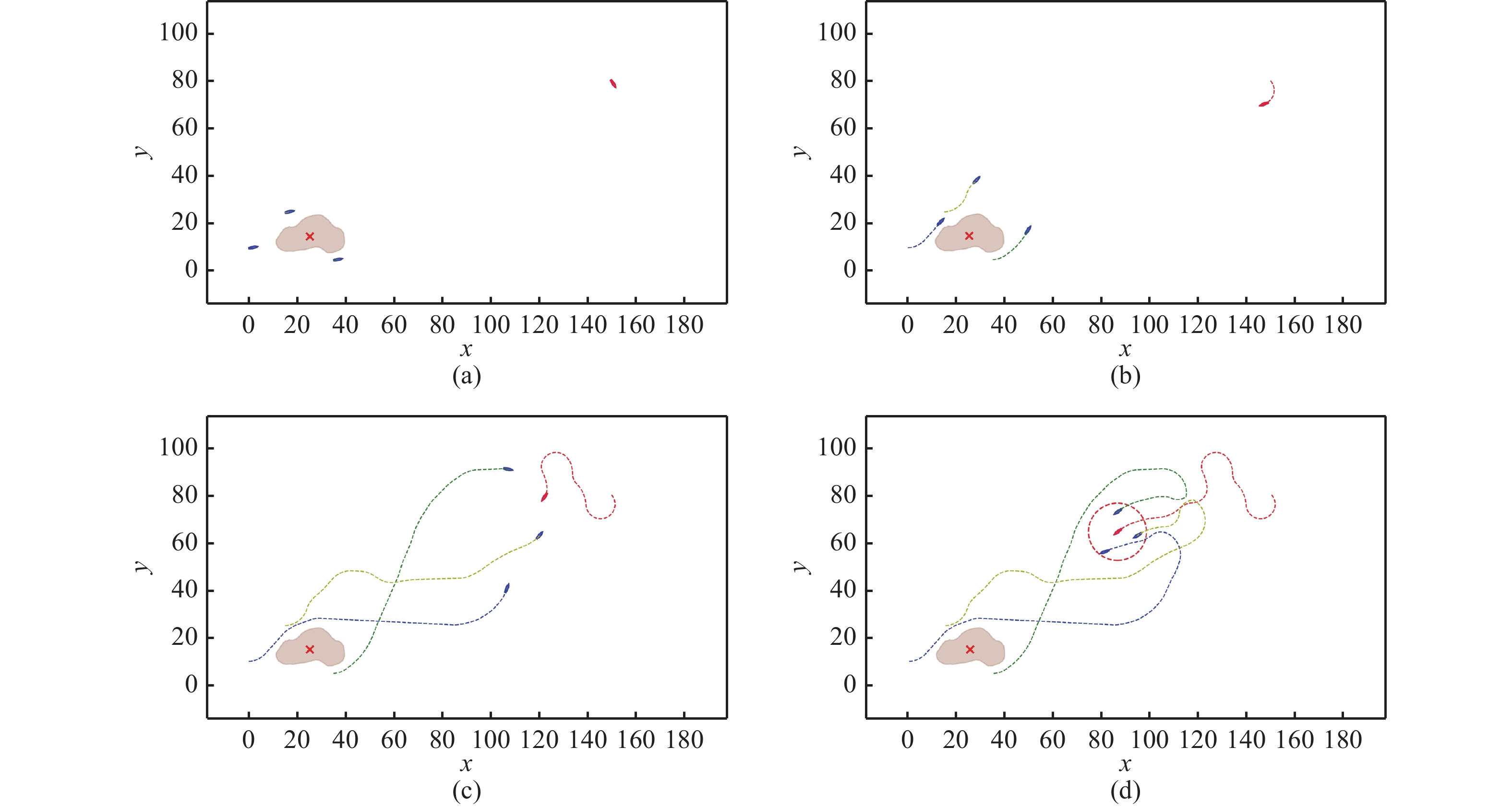
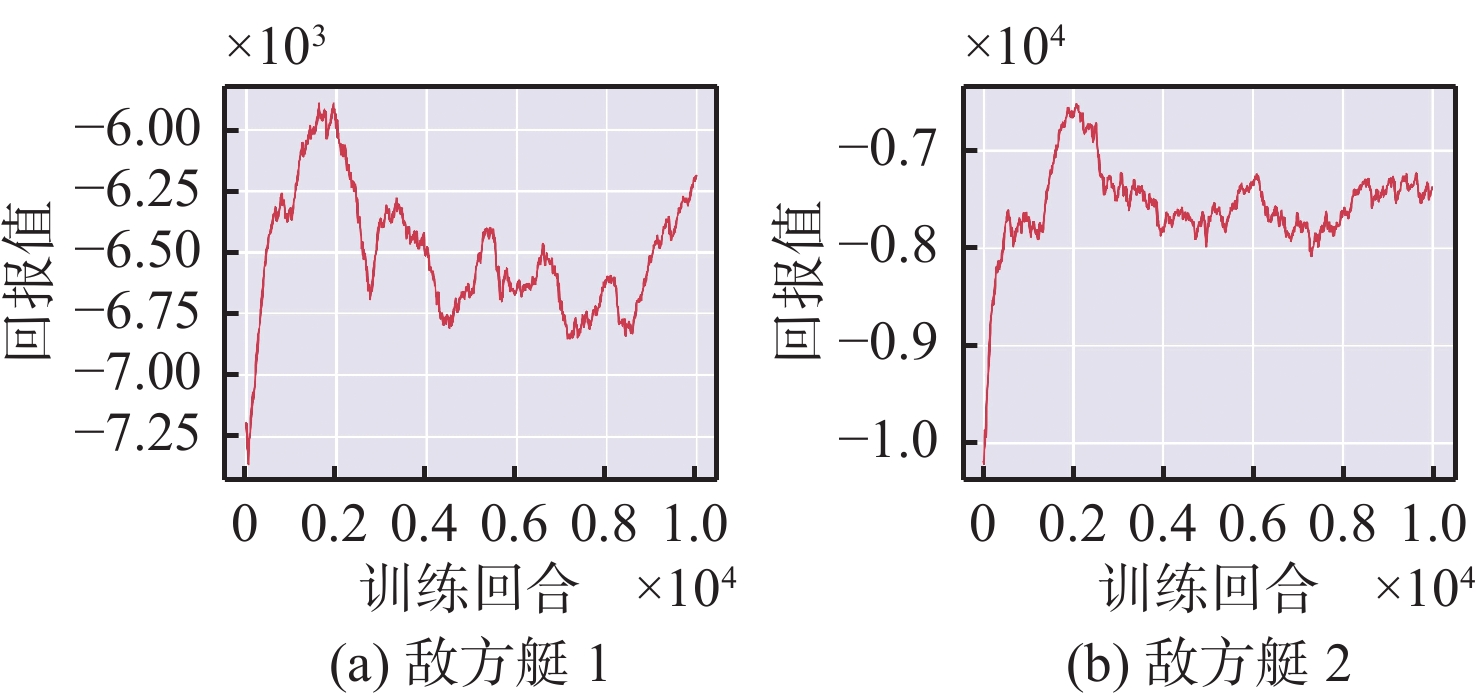
摘要: 基于未来现代化海上作战背景, 提出了利用多智能体深度强化学习方案来完成无人艇群博弈对抗中的协同围捕任务。首先, 根据不同的作战模式和应用场景, 提出基于分布式执行的多智能体深度确定性策略梯度算法, 并对其原理进行了介绍; 其次, 模拟具体作战场景平台, 设计多智能体网络模型、奖励函数机制以及训练策略。实验结果表明, 文中方法可以有效应对敌方无人艇的协同围捕决策问题, 在不同作战场景下具有较高的效率, 为未来复杂作战场景下无人艇智能决策研究提供理论参考价值。
-
关键词:
- 无人艇集群 /
- 多智能体深度确定性策略梯度算法 /
- 深度强化学习 /
- 智能决策 /
- 博弈对抗
Abstract: Based on the background of future modern maritime combats, a multi-agent deep reinforcement learning scheme was proposed to complete the cooperative round-up task in the swarm game confrontation of unmanned surface vehicles (USVs). First, based on different combat modes and application scenarios, a multi-agent deep deterministic policy gradient algorithm based on distributed execution was determined, and its principle was introduced. Second, specific combat scenario platforms were simulated, and multi-agent network models, reward function mechanisms, and training strategies were designed. The experimental results show that the method proposed in this article can effectively solve the problem of cooperative round-up decision-making facing USVs from the enemy, and it has high efficiency in different combat scenarios. This work provides theoretical and reference value for the research on intelligent decision-making of USVs in complicated combat scenarios in the future. -

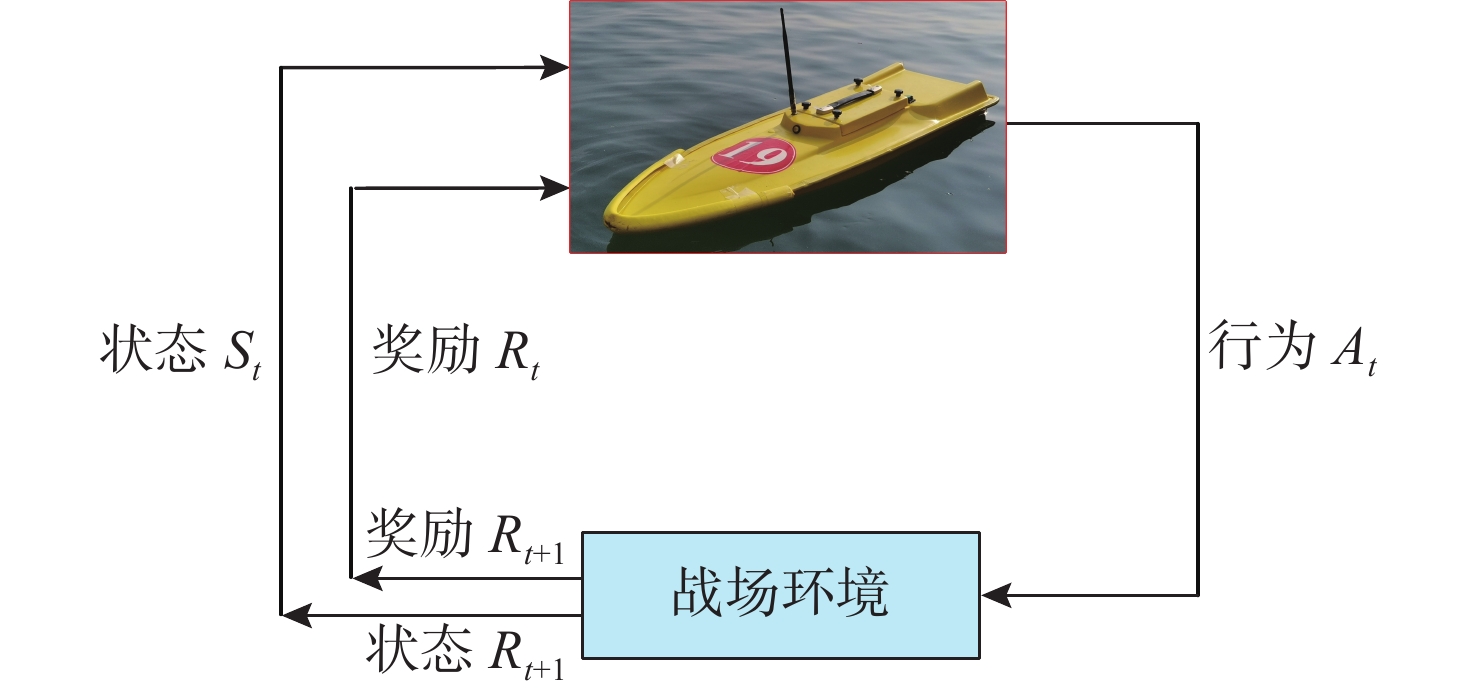
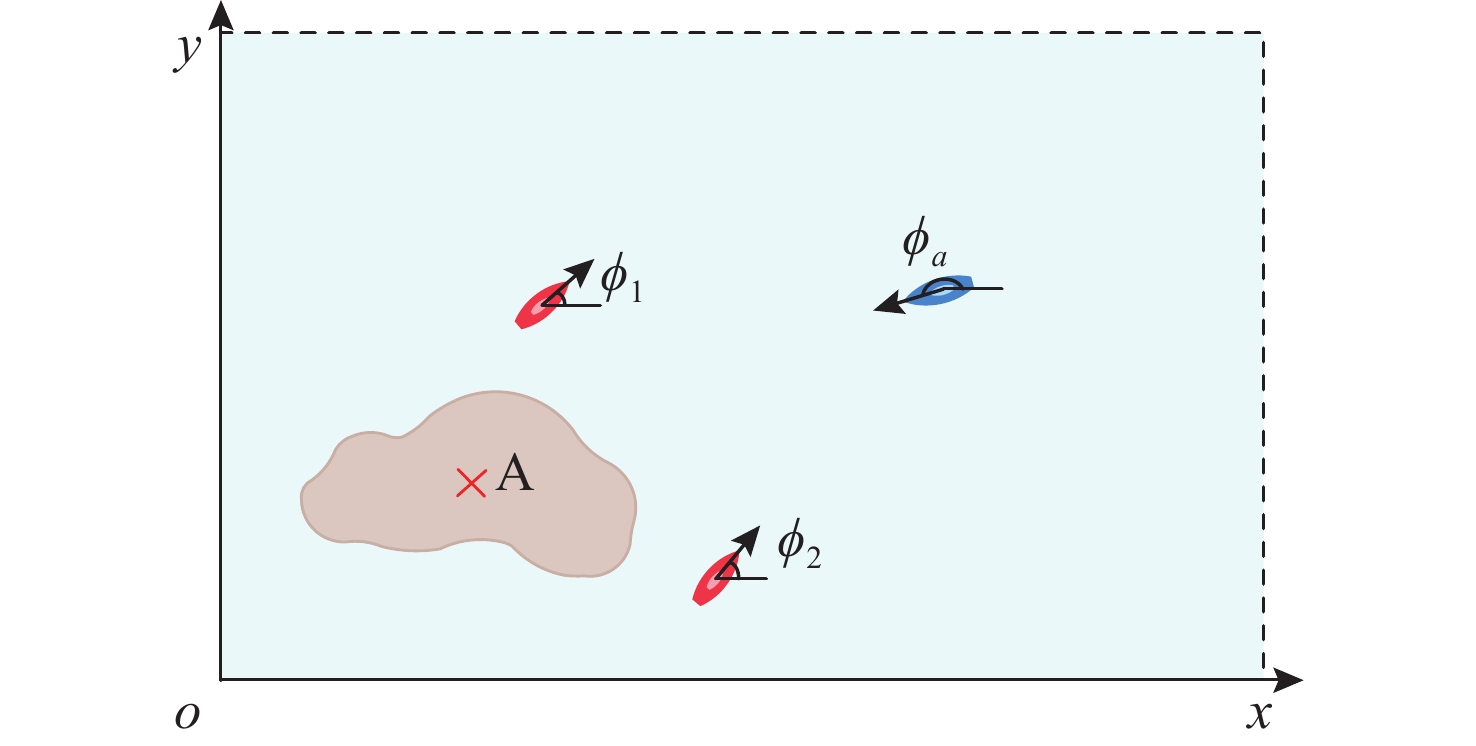
图 2 无人艇与环境交互过程示意图
Figure 2. Schematic diagram of the interaction process bet- ween the USV and environment
-
[1] 林龙信, 张比升. 水面无人作战系统技术发展与作战应用[J]. 水下无人系统学报, 2018, 26(2): 107-114.Lin Longxin, Zhang Bisheng. Technical development and operational application of unmanned surface combat system[J]. Journal of Unmanned Undersea Systems, 2018, 26(2): 107-114. [2] 胡桥, 赵振轶, 冯豪博, 等. AUV智能集群协同任务研究进展[J]. 水下无人系统学报, 2023, 31(2): 189-200. doi: 10.11993/j.issn.2096-3920.2023-0002Hu Qiao, Zhao Zhenyi, Feng Haobo, et al. Progress of AUV intelligent swarm collaborative task[J]. Journal of Unmanned Undersea Systems, 2023, 31(2): 189-200. doi: 10.11993/j.issn.2096-3920.2023-0002 [3] Hu D, Yang R, Zuo J, et al. Application of deep reinforcement learning in maneuver planning of beyond-visual-range air combat[J]. IEEE Access, 2021, 9: 32282-32297. doi: 10.1109/ACCESS.2021.3060426 [4] 高霄鹏, 刘冬雨, 霍聪. 水面无人艇运动规划研究综述[J]. 舰船科学技术, 2023, 45(16): 1-6. doi: 10.3404/j.issn.1672-7649.2023.16.001Gao Xiaopeng, Liu Dongyu, Huo Cong. A review of research on motion planning of unmanned surface vehicles[J]. Ship Science and Technology, 2023, 45(16): 1-6. doi: 10.3404/j.issn.1672-7649.2023.16.001 [5] 刘鹏, 赵建新, 张宏映, 等. 基于改进型MADDPG的多智能体对抗策略算法[J]. 火力与指挥控制, 2023, 48(3): 132-138, 145. doi: 10.3969/j.issn.1002-0640.2023.03.020Liu Peng, Zhao Jianxin, Zhang Hongying, et al. Multi-agent confrontation strategy algorithm based on improved MADDPG[J]. Fire Control & Command Control, 2023, 48(3): 132-138, 145. doi: 10.3969/j.issn.1002-0640.2023.03.020 [6] Wang N, Xu H. Dynamics-constrained global-local hybrid path planning of an autonomous surface vehicle[J]. IEEE Transactions on Vehicular Technology, 2020, 69(7): 6928-6942. doi: 10.1109/TVT.2020.2991220 [7] Hua X, Liu J, Zhang J, et al. An apollonius circle based game theory and Q-learning for cooperative hunting in unmanned aerial vehicle cluster[J]. Computers and Electrical Engineering, 2023, 110: 108876. doi: 10.1016/j.compeleceng.2023.108876 [8] 李波, 越凯强, 甘志刚, 等. 基于MADDPG的多无人机协同任务决策[J]. 宇航学报, 2021, 42(6): 757-765.Li Bo, Yue Kaiqiang, Gan Zhigang, et al. Multi-UAV cooperative autonomous navigation based on multi-agent deep deterministic policy gradient[J]. Journal of Astronautics, 2021, 42(6): 757-765. [9] 刘菁, 华翔, 张金金. 一种改进博弈学习的无人机集群协同围捕方法[J]. 西安工业大学学报, 2023, 43(3): 277-286.Liu Jing, Hua Xiang, Zhang Jinjin. Improved game learning method for UAV swarm cooperative hunting[J]. Journal of Xi’an Technological University, 2023, 43(3): 277-286. [10] Zhan G, Zhang X, Li Z, et al. Multiple-UAV reinforcement learning algorithm based on improved PPO in ray framework[J]. Drones, 2022, 6(7): 166. doi: 10.3390/drones6070166 [11] 赵伟, 叶军, 王邠. 基于人工智能的智能化指挥决策和控制[J]. 信息安全与通信保密, 2022(2): 2-8. doi: 10.3969/j.issn.1009-8054.2022.02.001Zhao Wei, Ye Jun, Wang Bin. Intelligentized command and control based on artificial intelligence[J]. Information Security and Communications Privacy, 2022(2): 2-8. doi: 10.3969/j.issn.1009-8054.2022.02.001 [12] 苏震, 张钊, 陈聪, 等. 基于深度强化学习的无人艇集群博弈对抗[J]. 兵器装备工程学报, 2022, 43(9): 9-14. doi: 10.11809/bqzbgcxb2022.09.002Su Zhen, Zhang Zhao, Chen Cong, et al. Deep reinforcement learning based swarm game confrontation of unmanned surface vehicles[J]. Journal of Ordnance Equipment Engineering, 2022, 43(9): 9-14. doi: 10.11809/bqzbgcxb2022.09.002 [13] 夏家伟, 朱旭芳, 张建强, 等. 基于多智能体强化学习的无人艇协同围捕方法[J]. 控制与决策, 2023, 38(5): 1438-1447.Xia Jiawei, Zhu Xufang, Zhang Jianqiang, et al. Research on cooperative hunting method of unmanned surface vehicle based on multi-agent reinforcement learning[J]. Control and Decision, 2023, 38(5): 1438-1447. [14] Lowe R, Wu Y I, Tamar A, et al. Multi-agent actor-critic for mixed cooperative-competitive environments[C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Long Beach California, USA: NIPS, 2017. [15] Wu C H, Sofge D A, Lofaro D M. Crafting a robotic swarm pursuit-evasion capture strategy using deep reinforcement learning[J]. Artificial Life and Robotics, 2022, 27(2): 355-364. doi: 10.1007/s10015-022-00761-y [16] 蔺向阳, 邢清华, 邢怀玺. 基于MADDPG的无人机群空中拦截作战决策研究[J]. 计算机科学, 2023, 50(S1): 98-104.Lin Xiangyang, Xing Qinghua, Xing Huaixi. Study on intelligent decision making of aerial interception combat of UAV group based on MADDPG[J]. Computer Science, 2023, 50(S1): 98-104. -

 下载:
下载:




 点击查看大图
点击查看大图
计量
- 文章访问数: 3066
- HTML全文浏览量: 588
- PDF下载量: 538
- 被引次数: 0
图(10)




