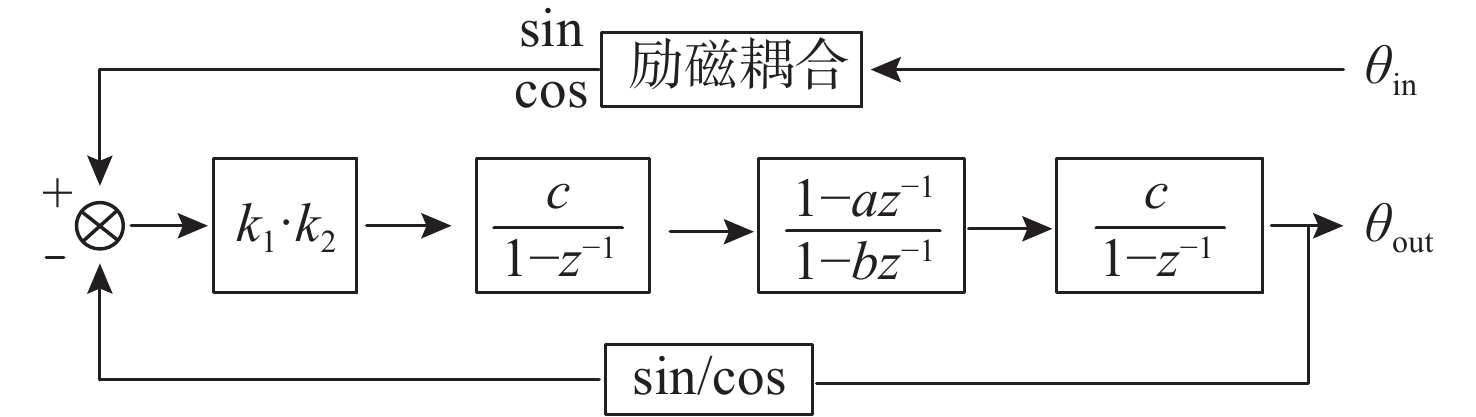
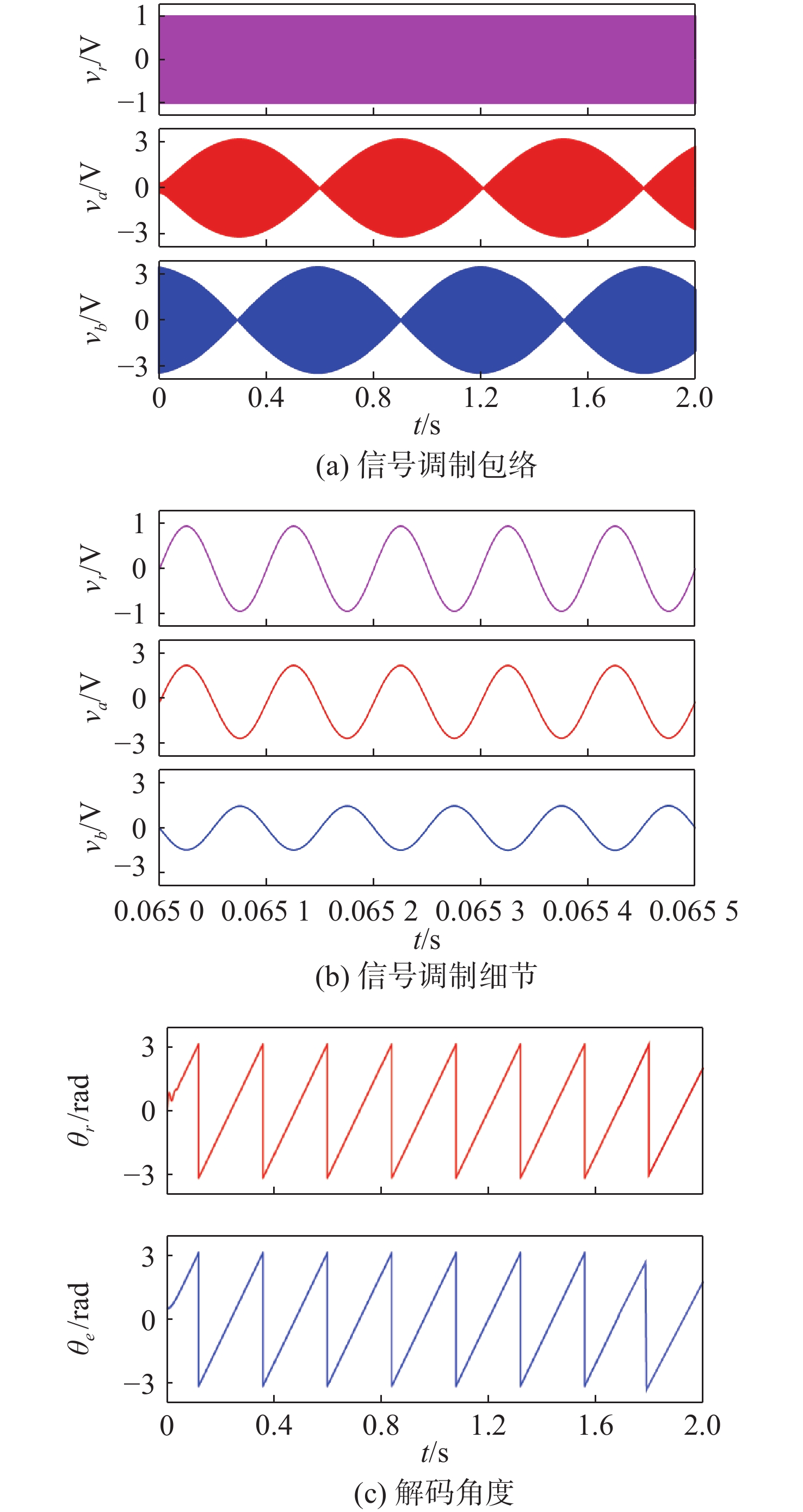
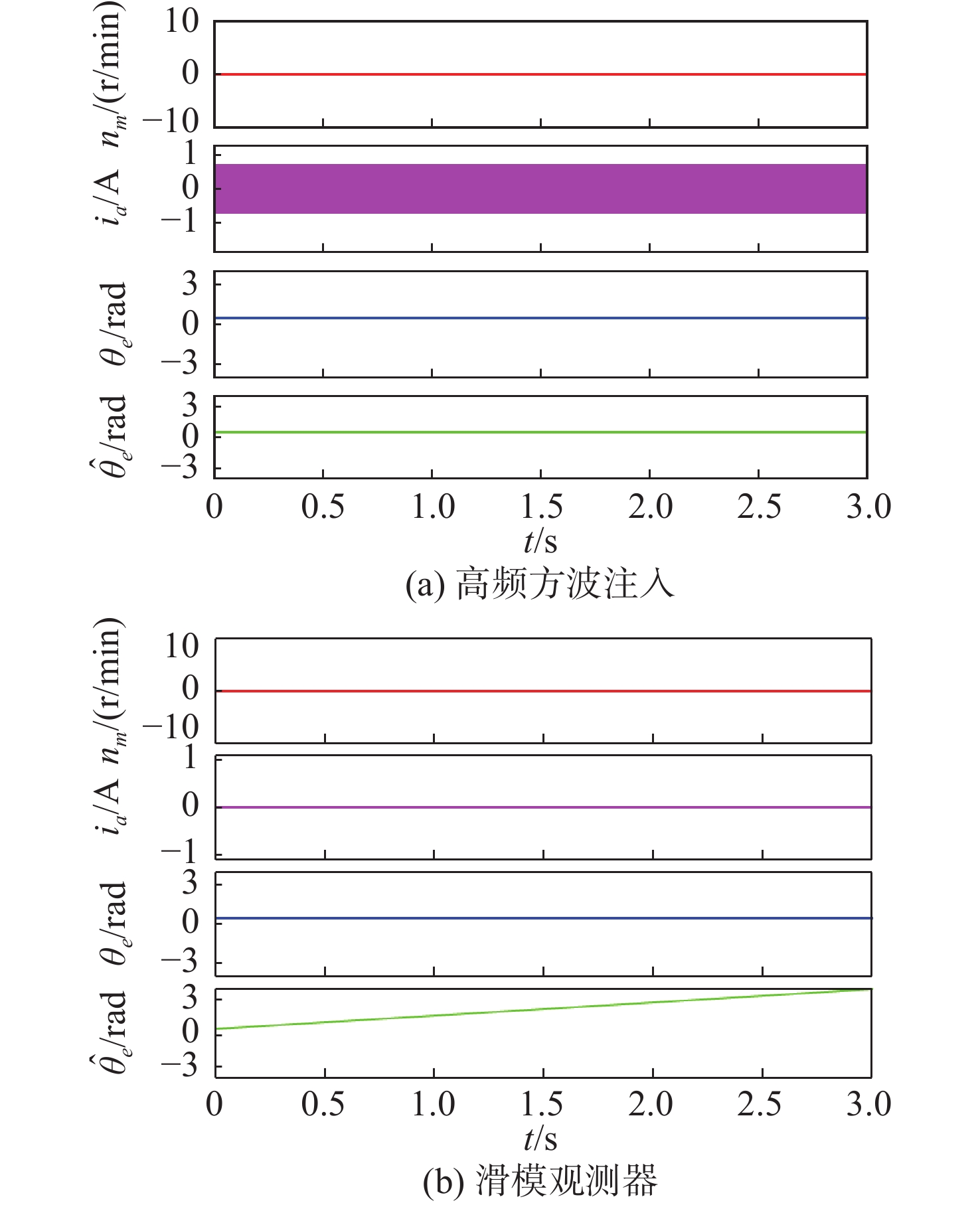
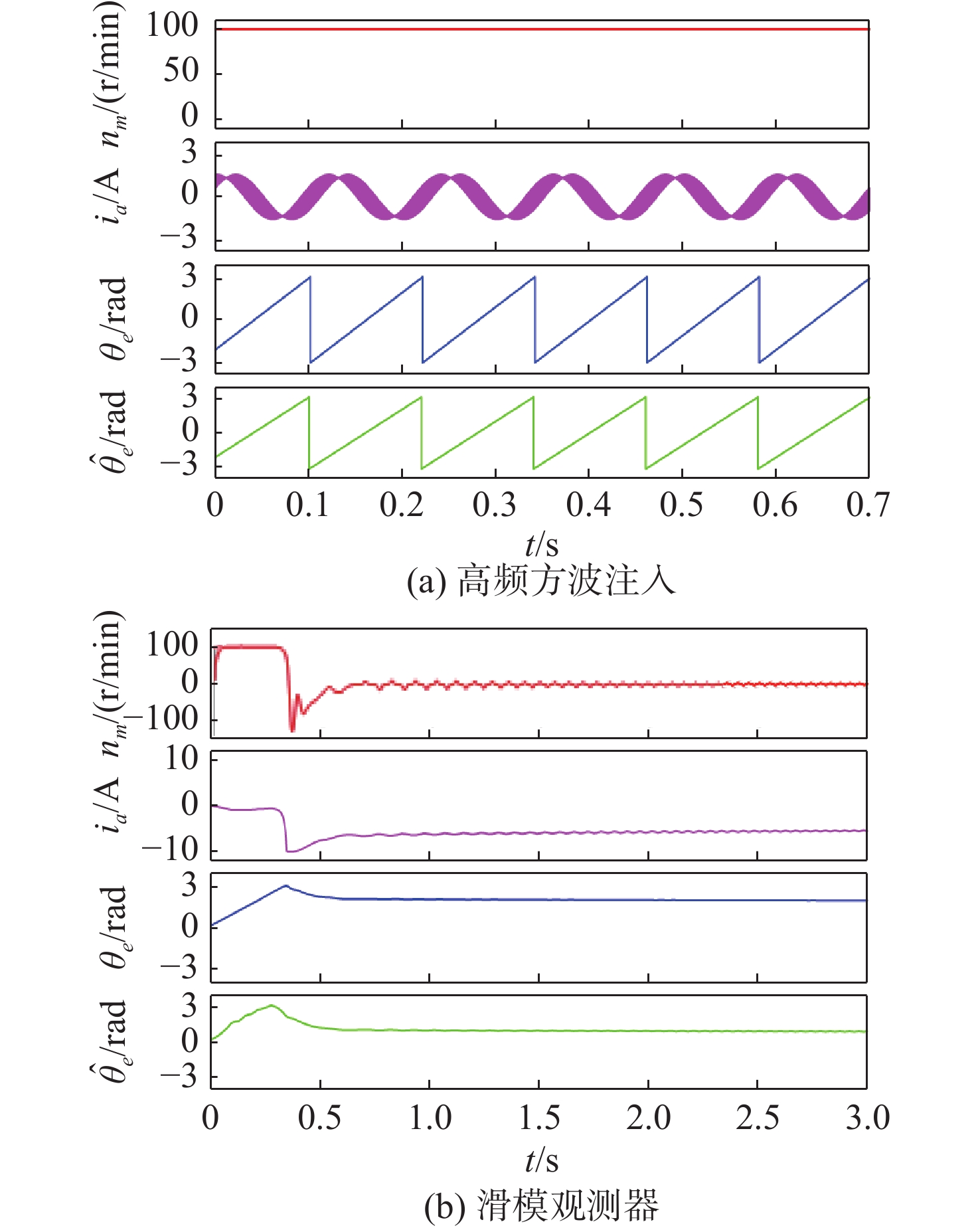
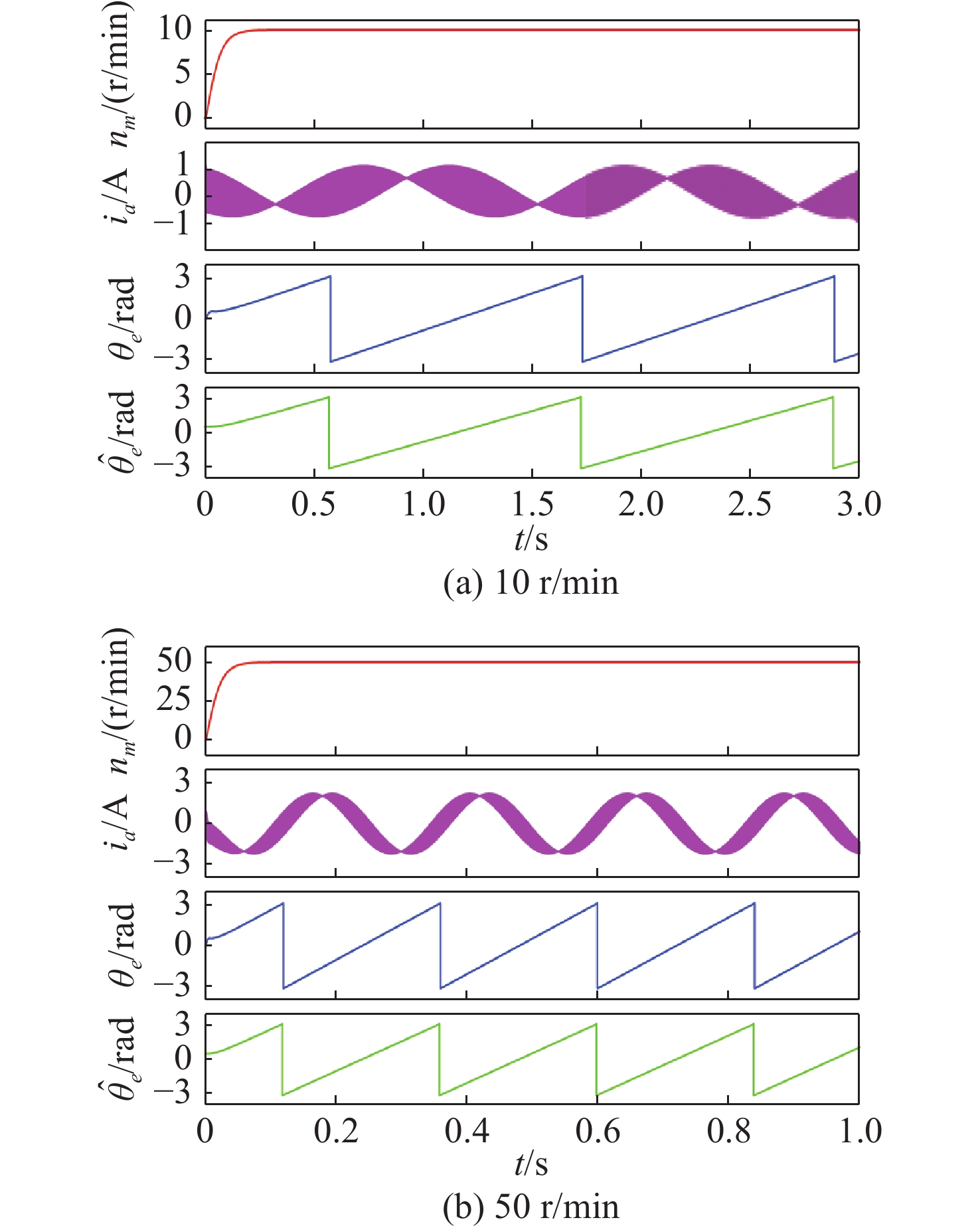
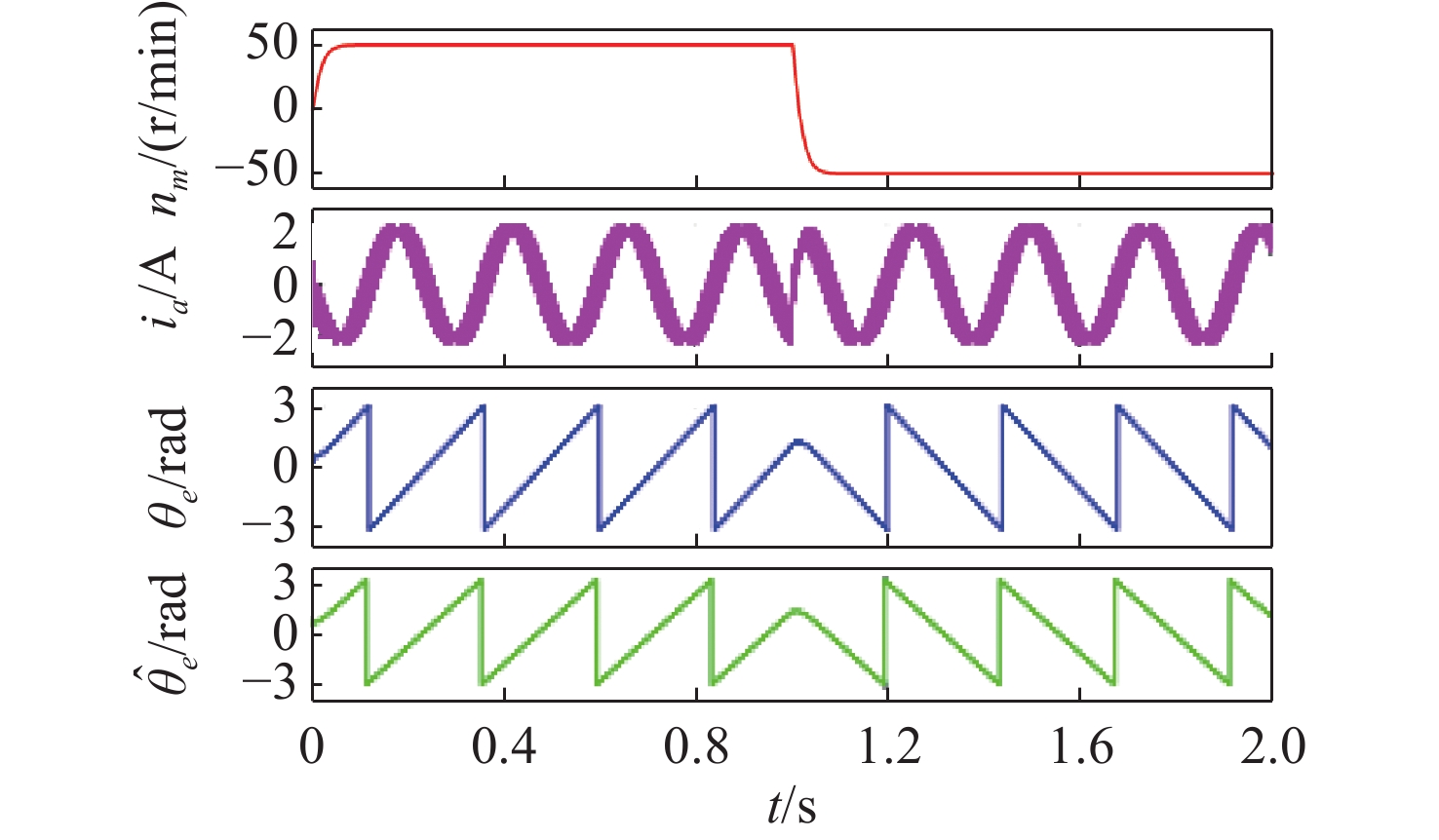
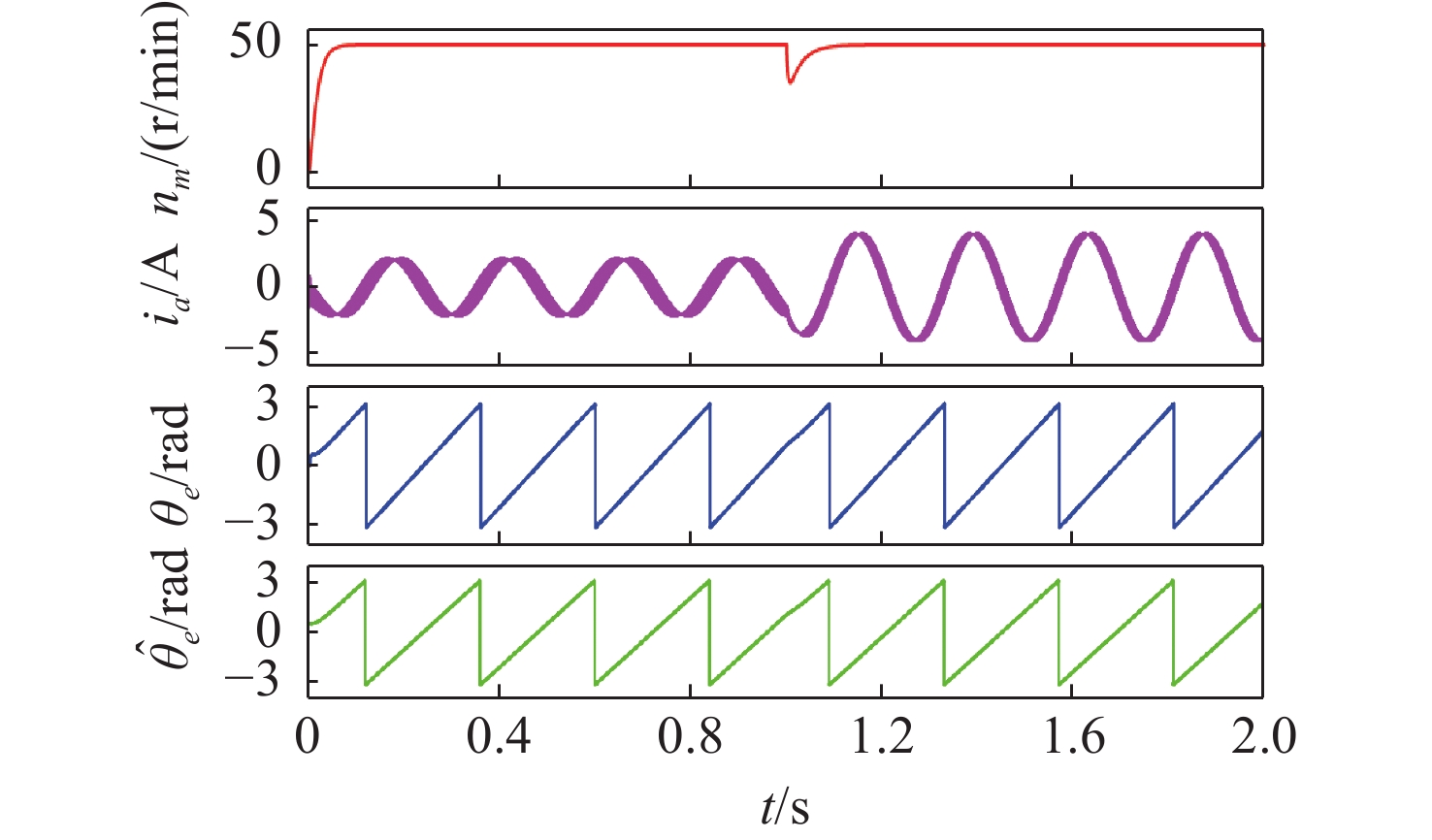
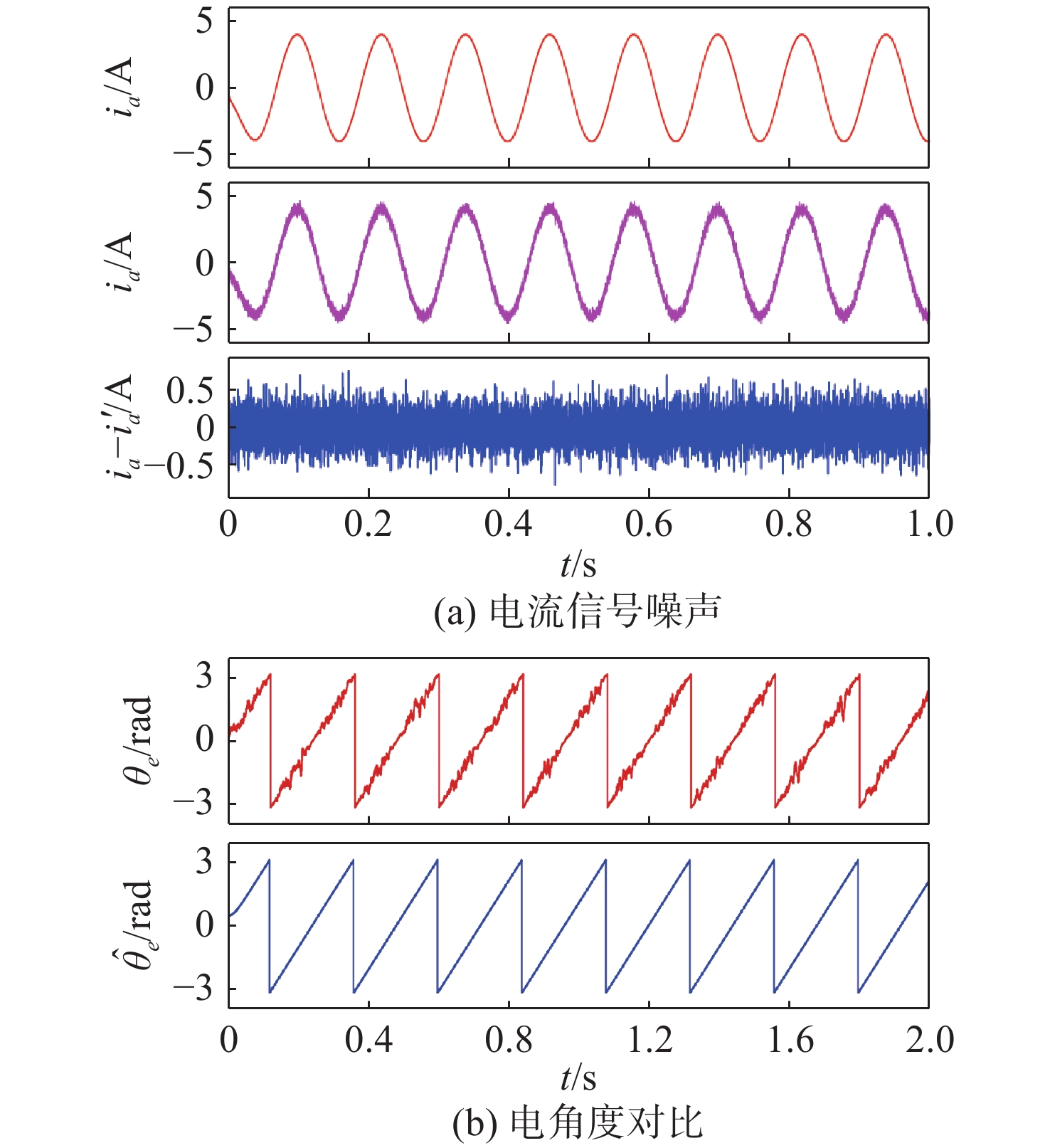
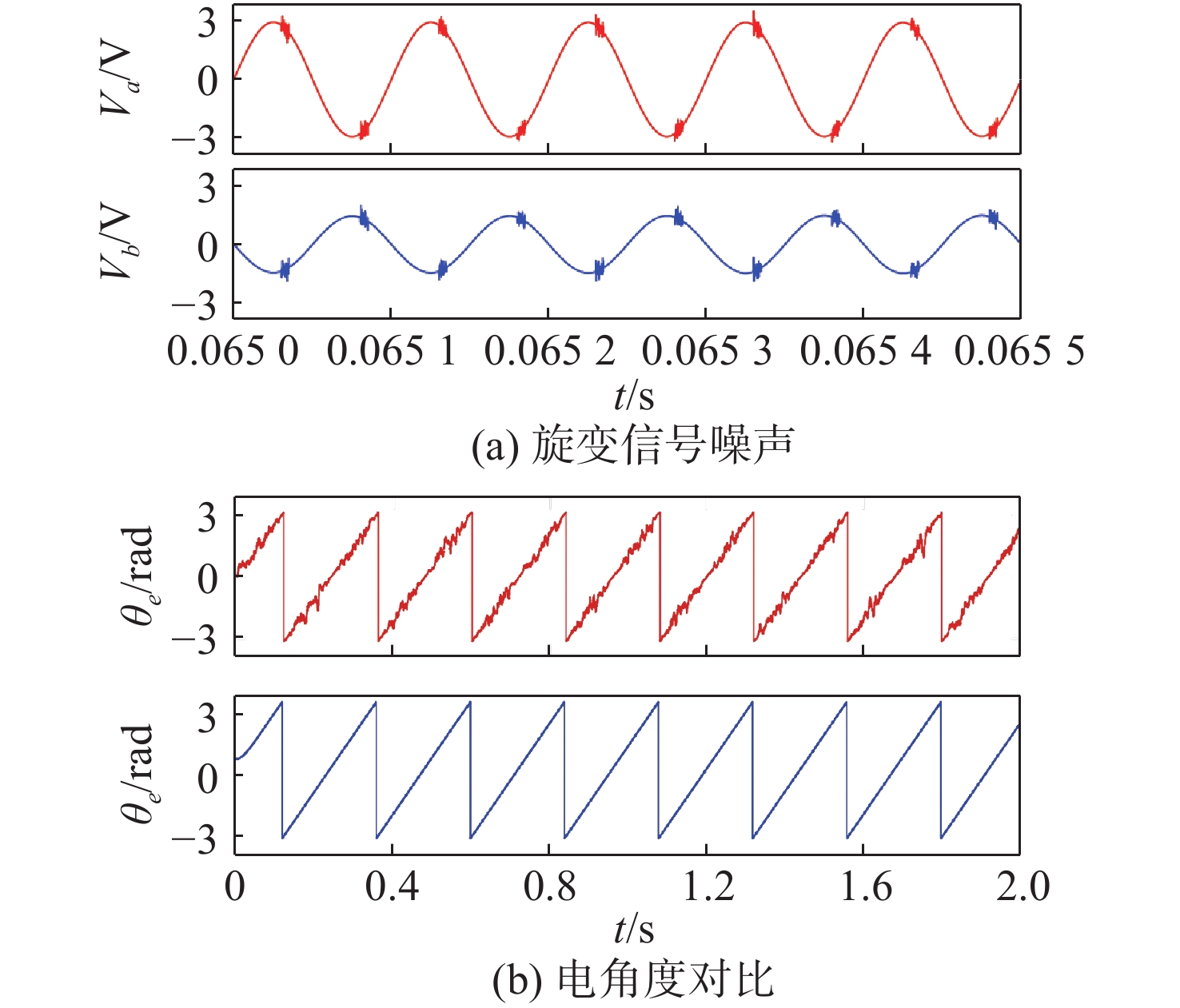
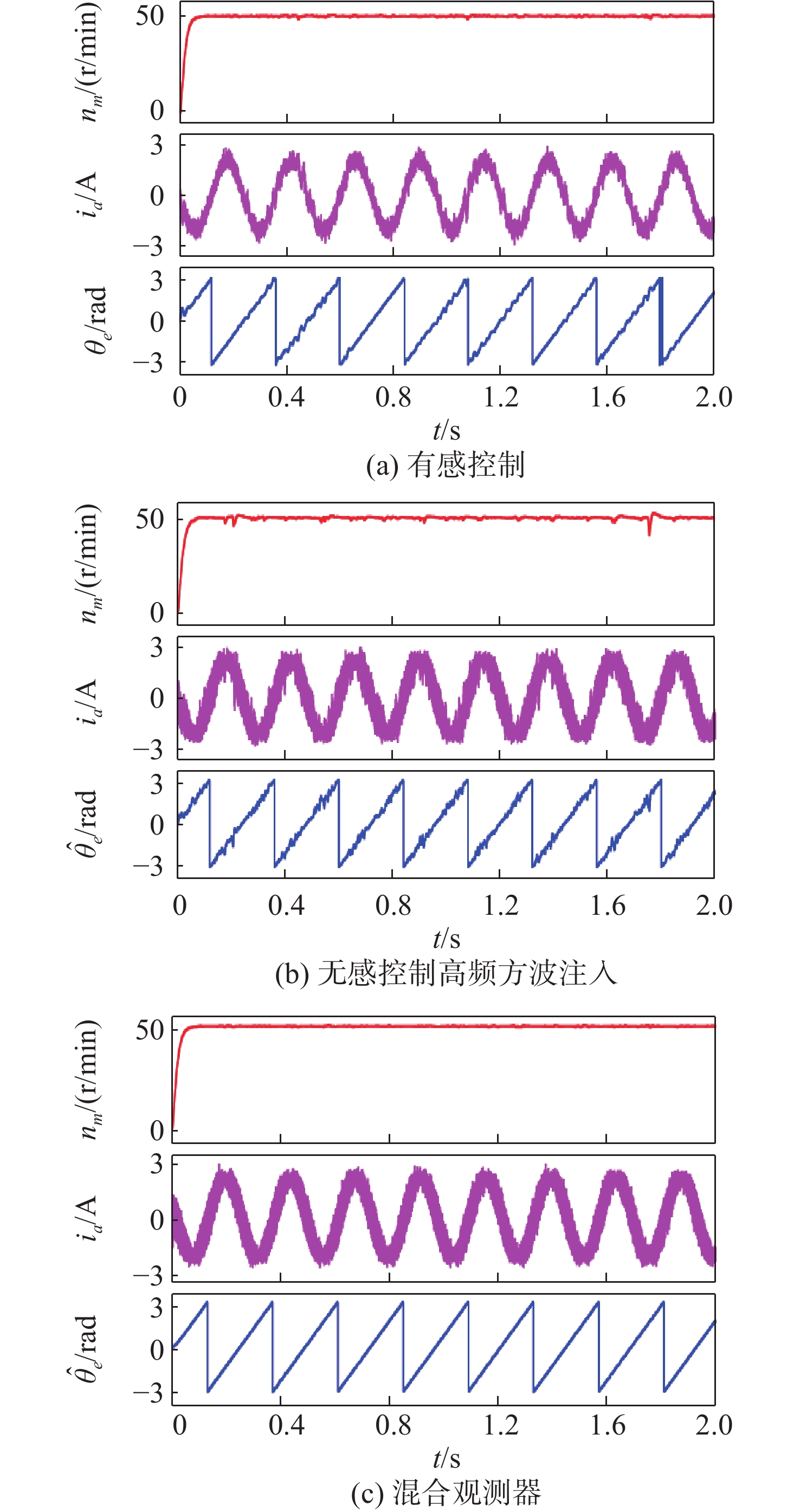
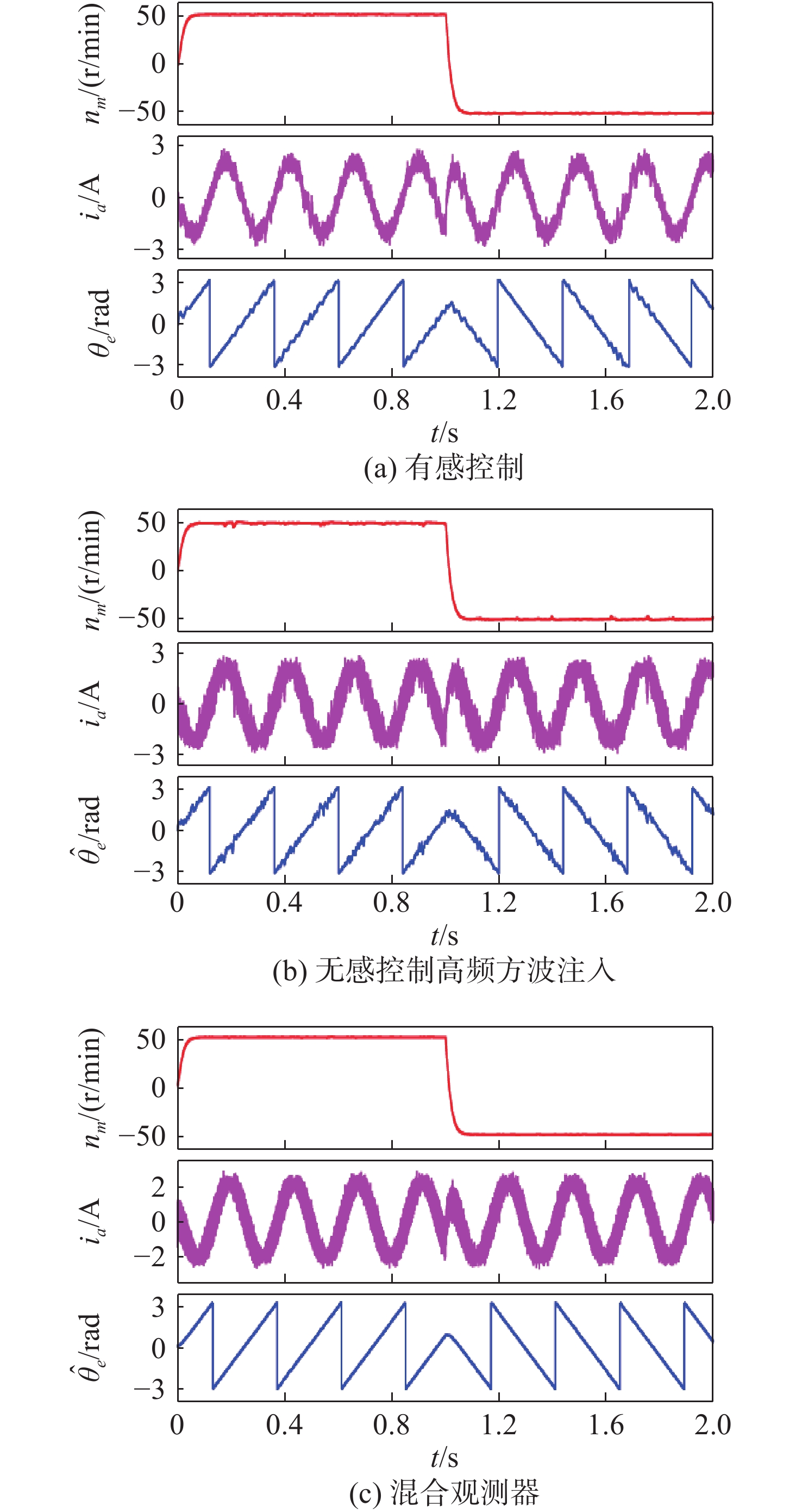
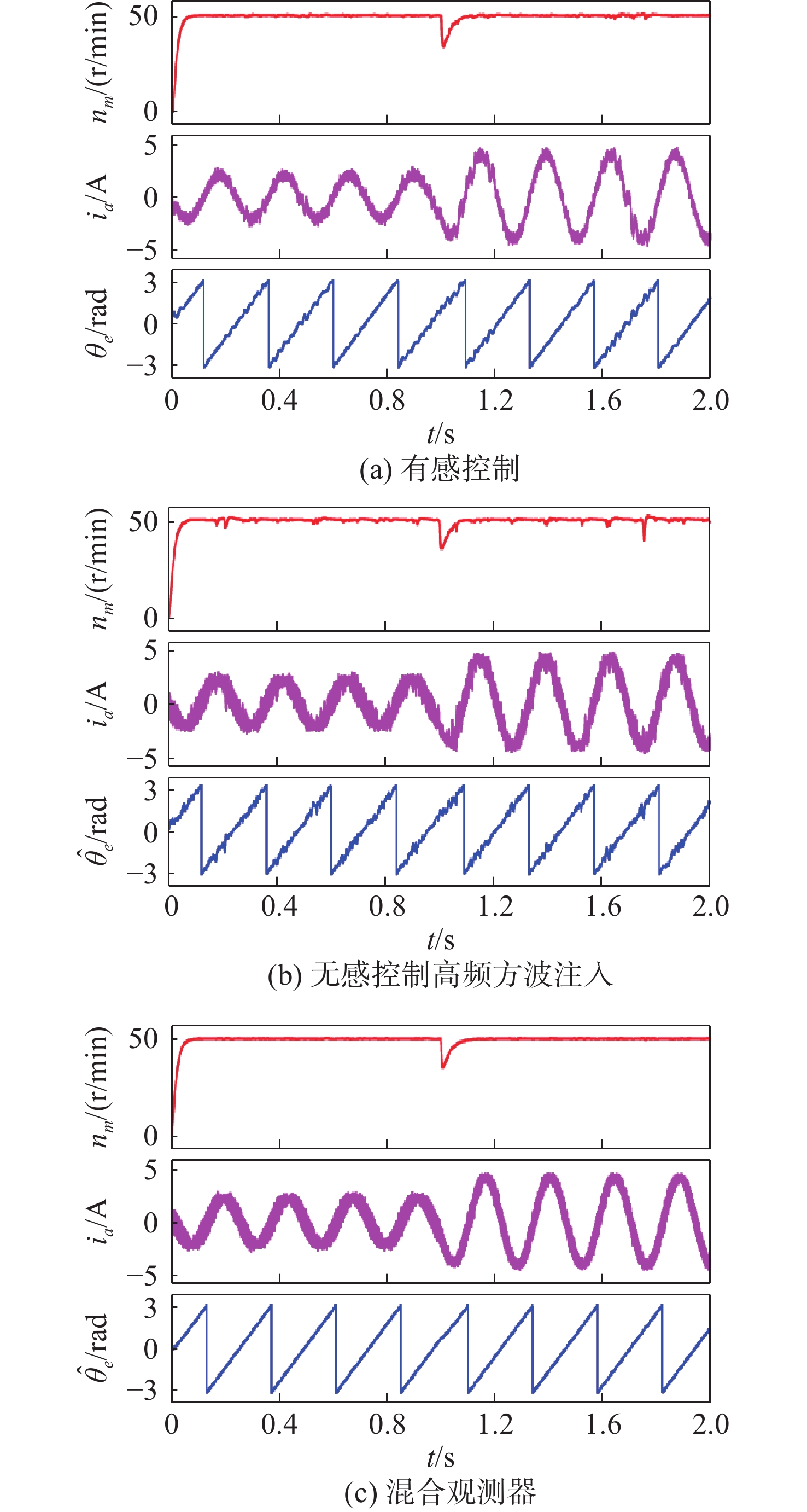
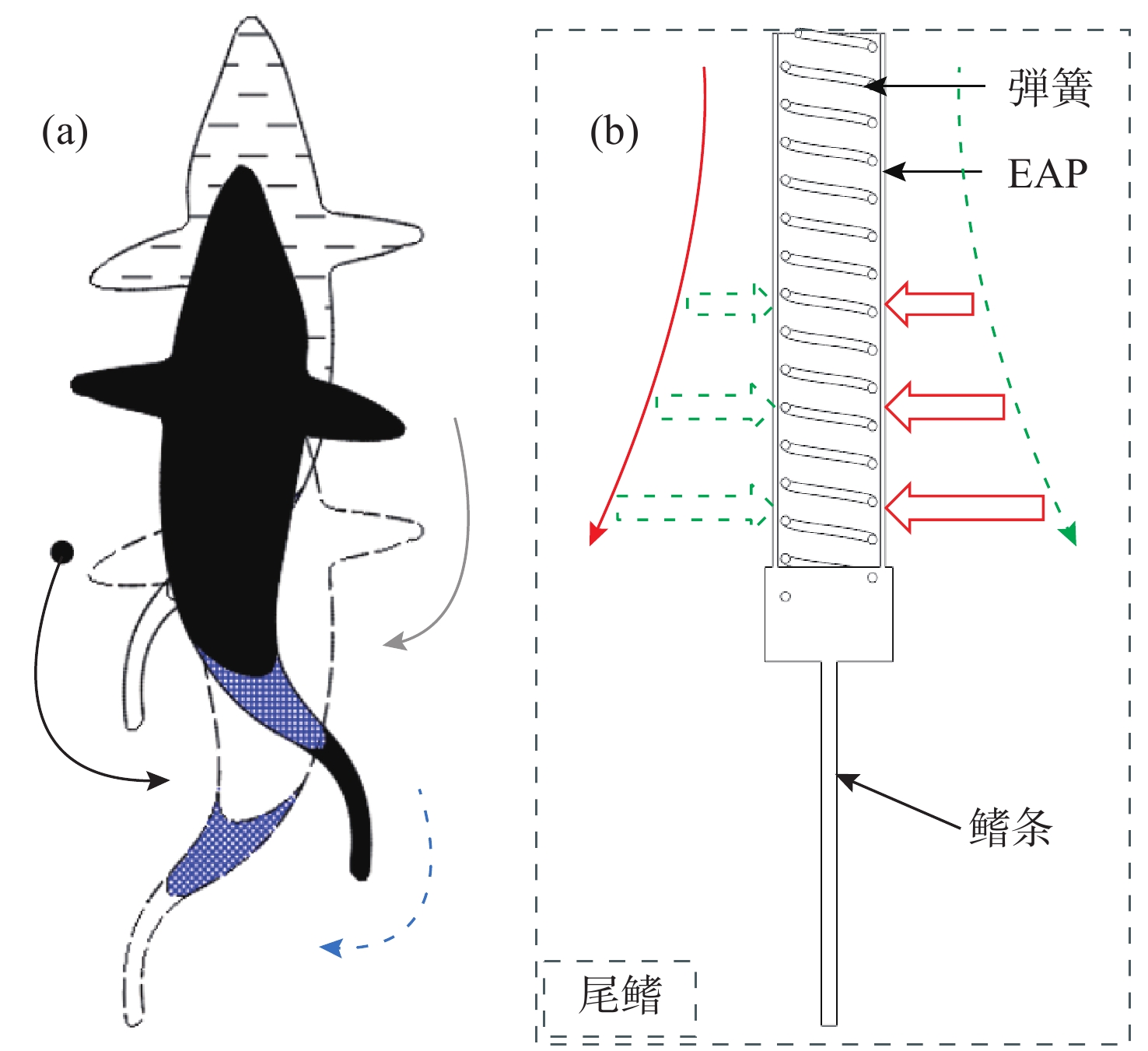
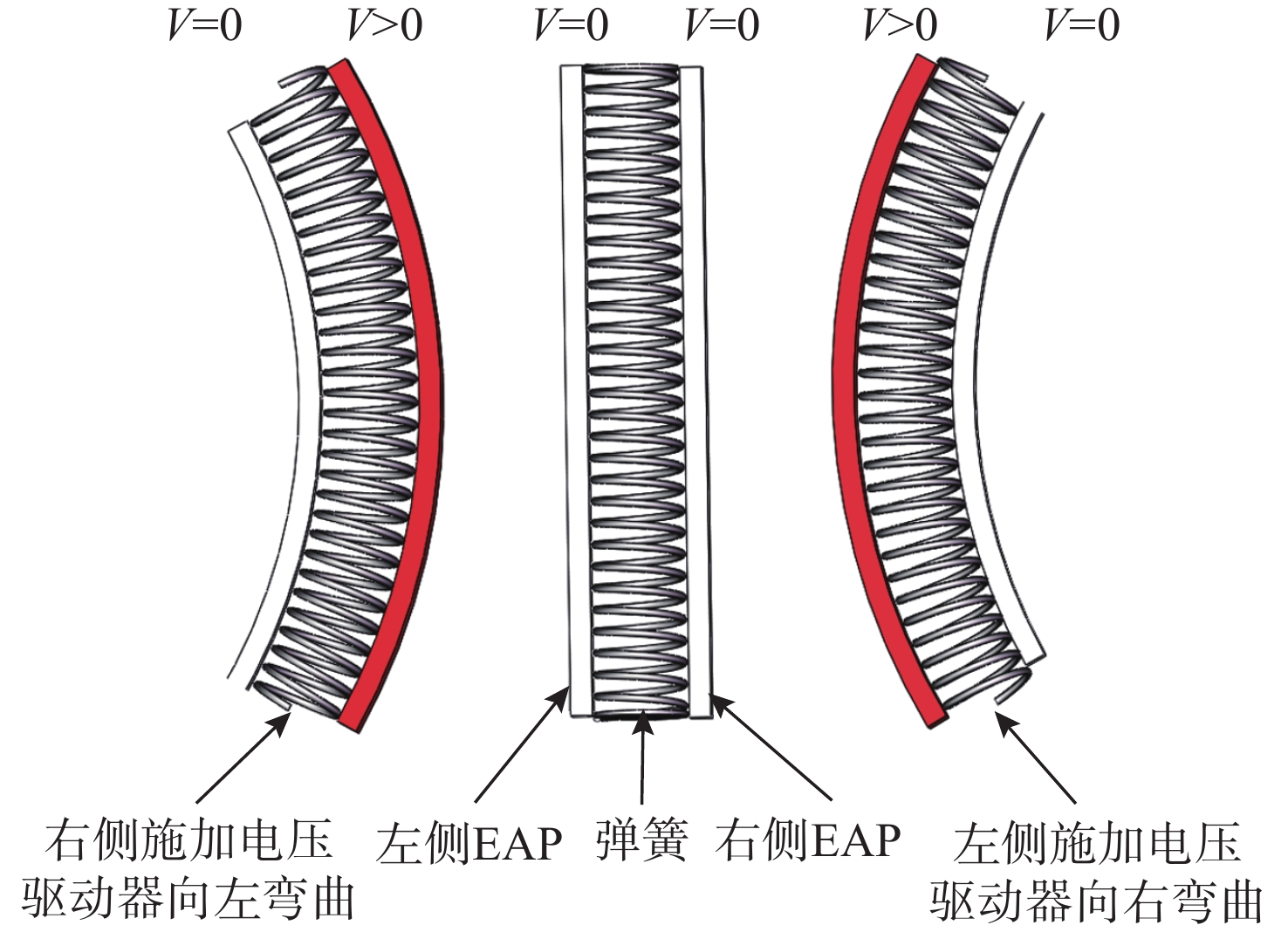
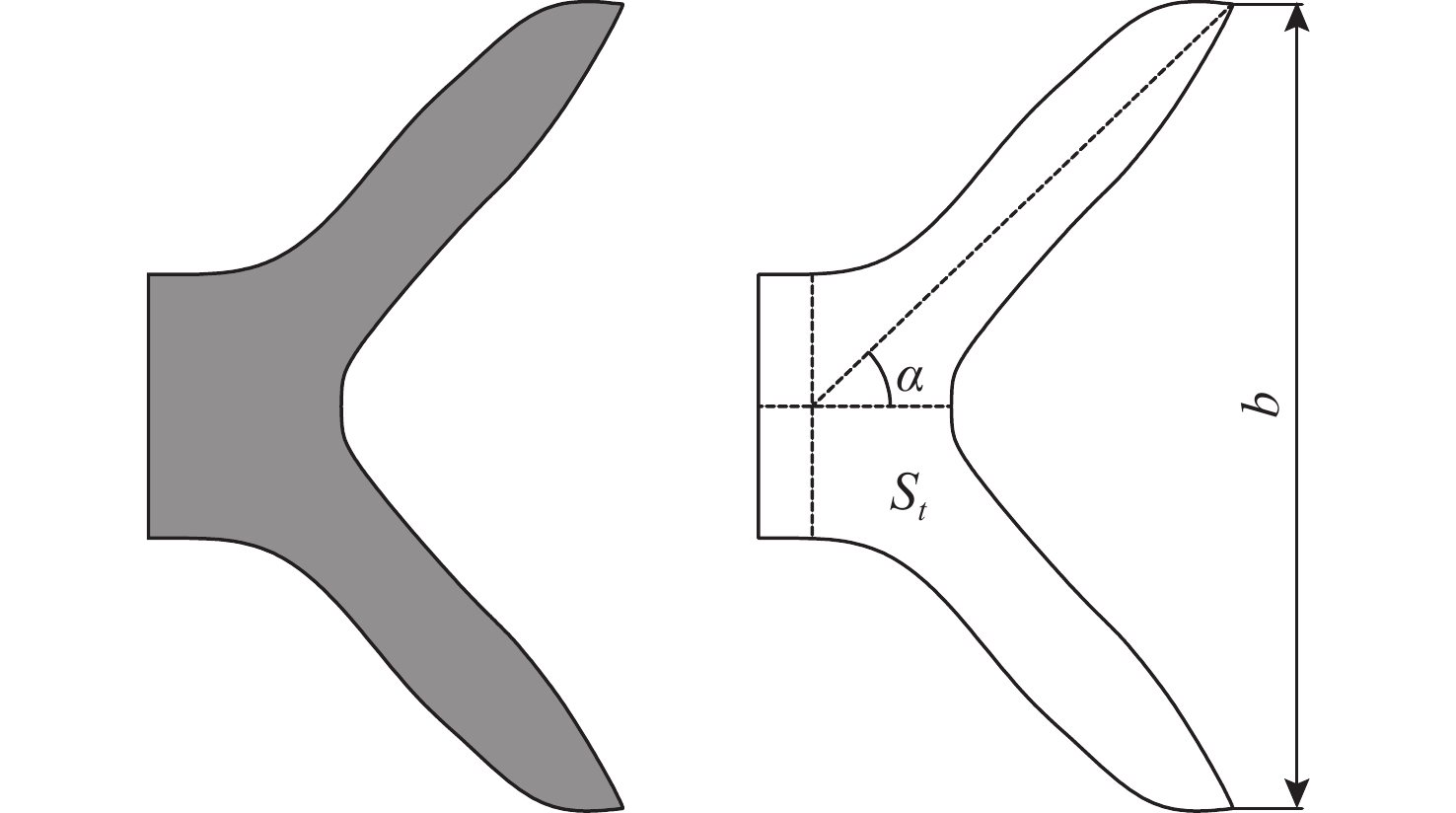
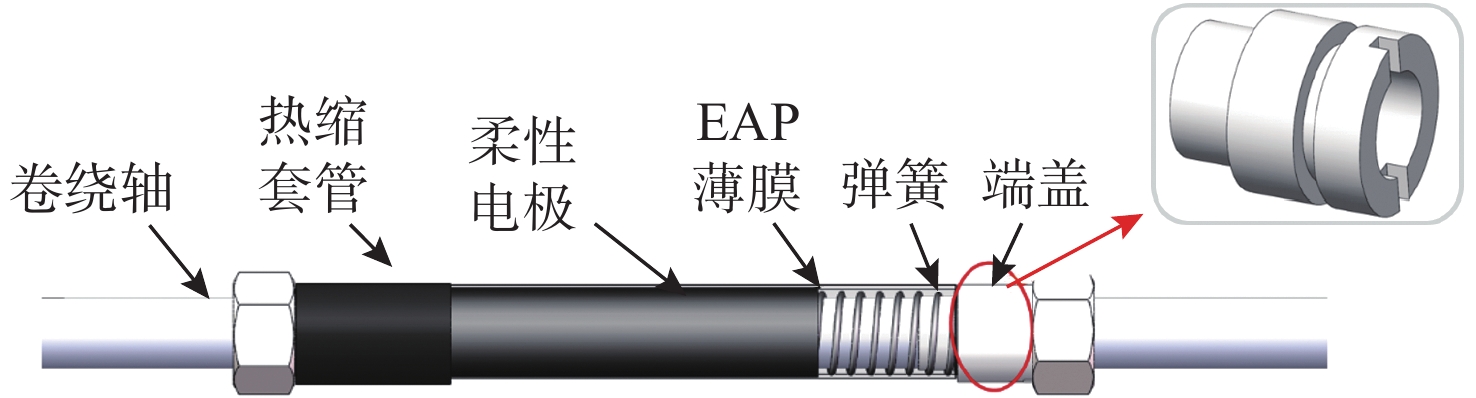
Latest Articles
Articles in press have been peer-reviewed and accepted, which are not yet assigned to volumes/issues, but are citable by Digital Object Identifier (DOI).
Display Method:

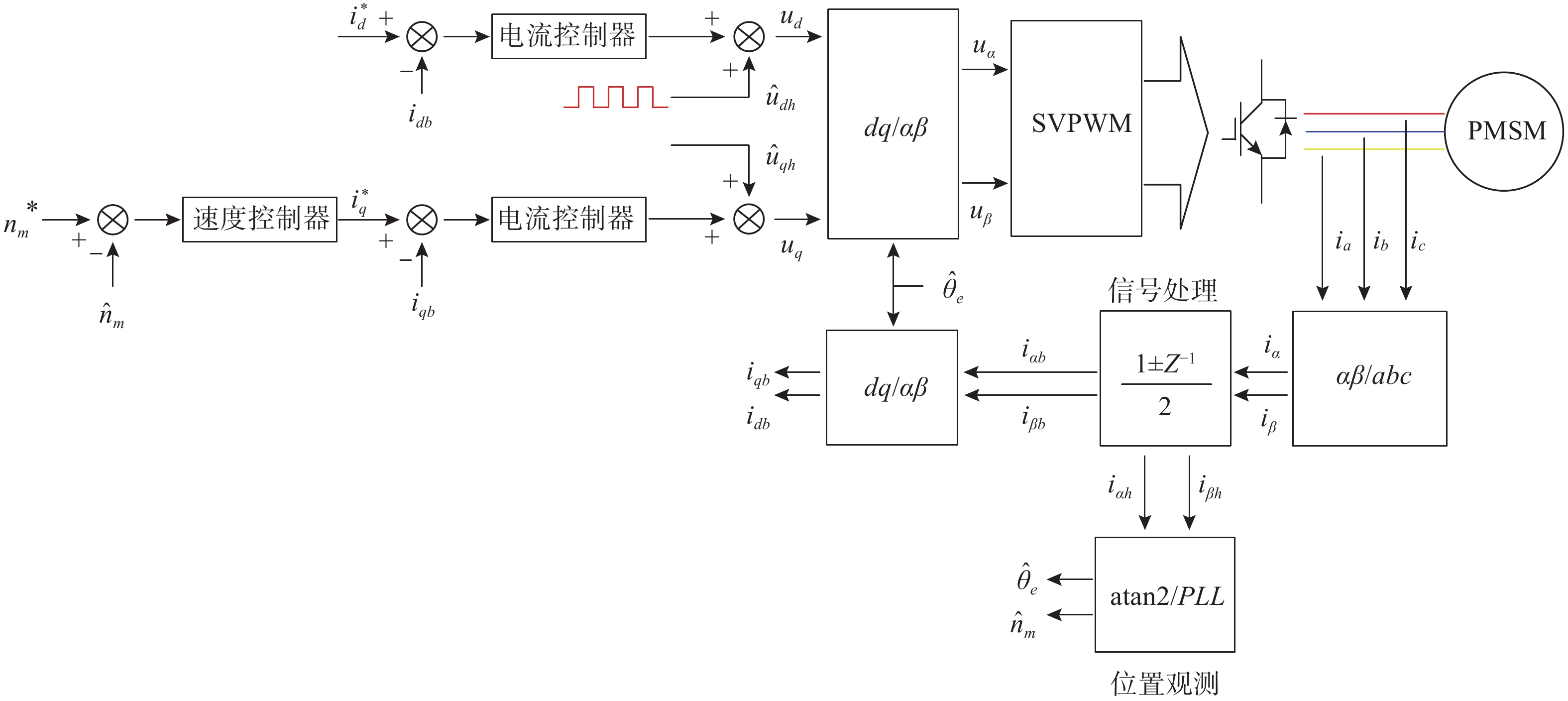
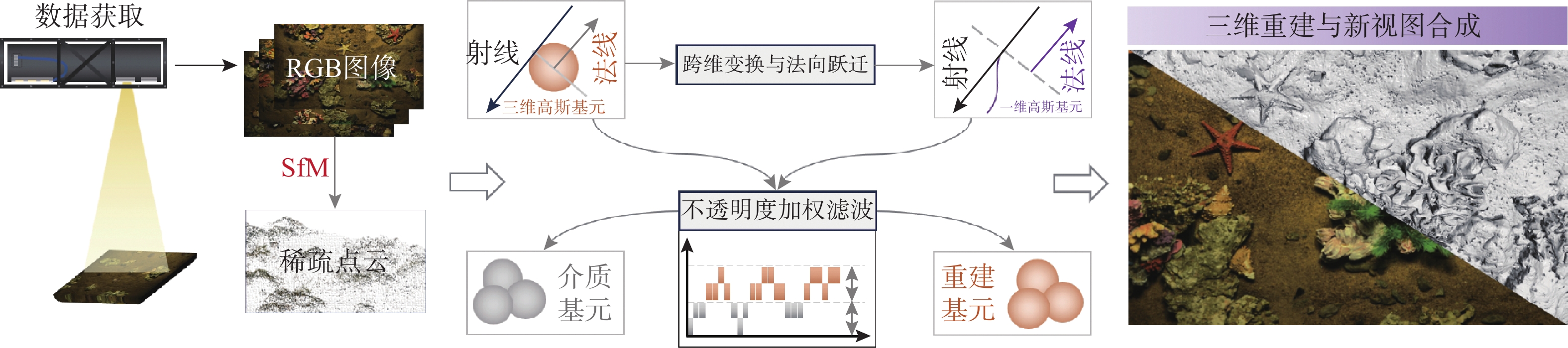
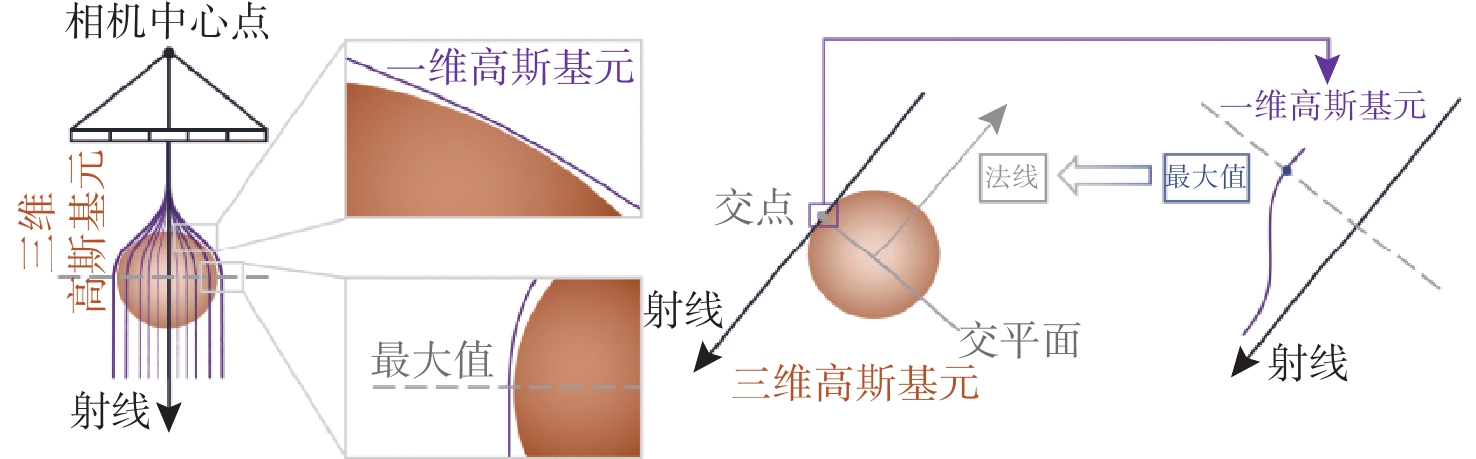
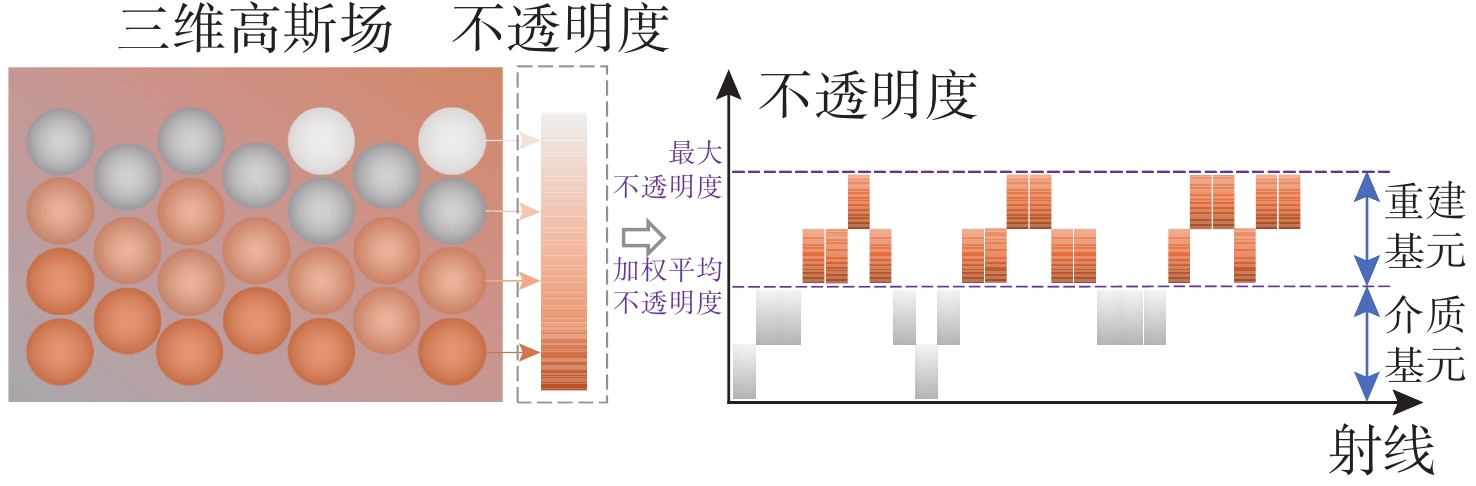
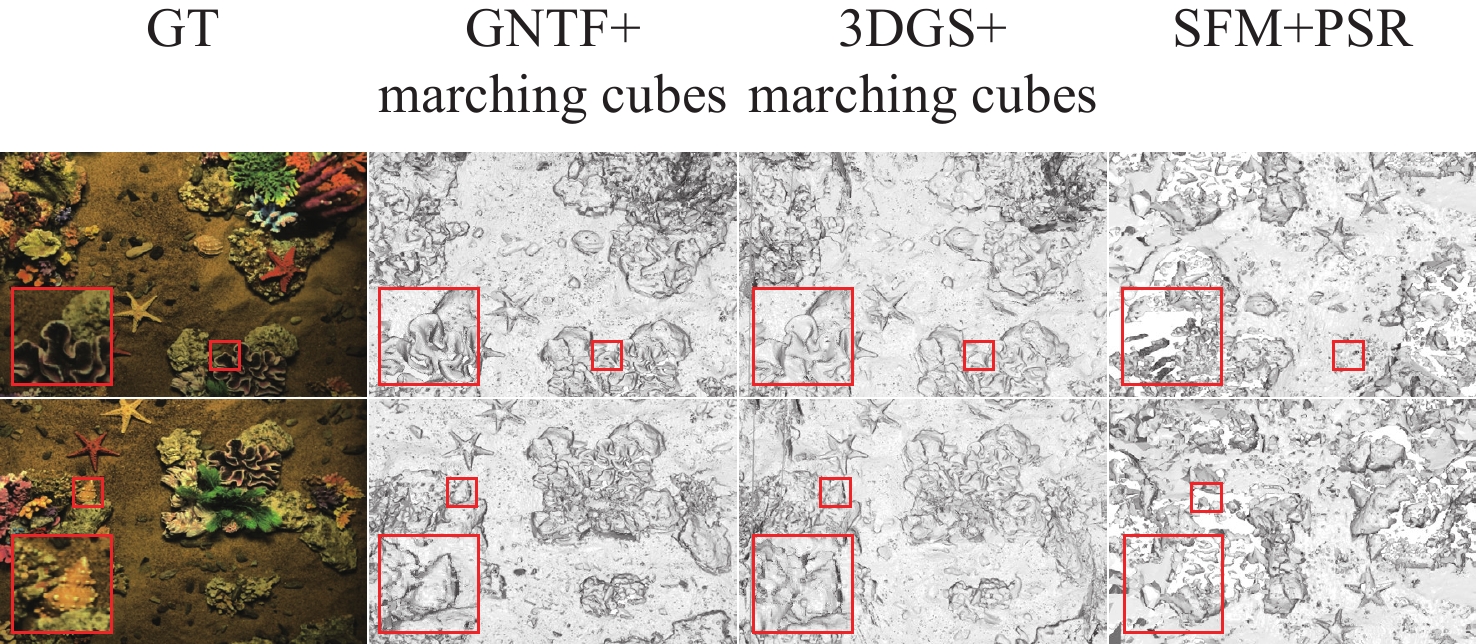
High-Fidelity Seafloor 3D Reconstruction Based on Cross-dimensional Gaussian Normal Transition Field
, Available online , doi: 10.11993/j.issn.2096-3920.2025-0167
Abstract:





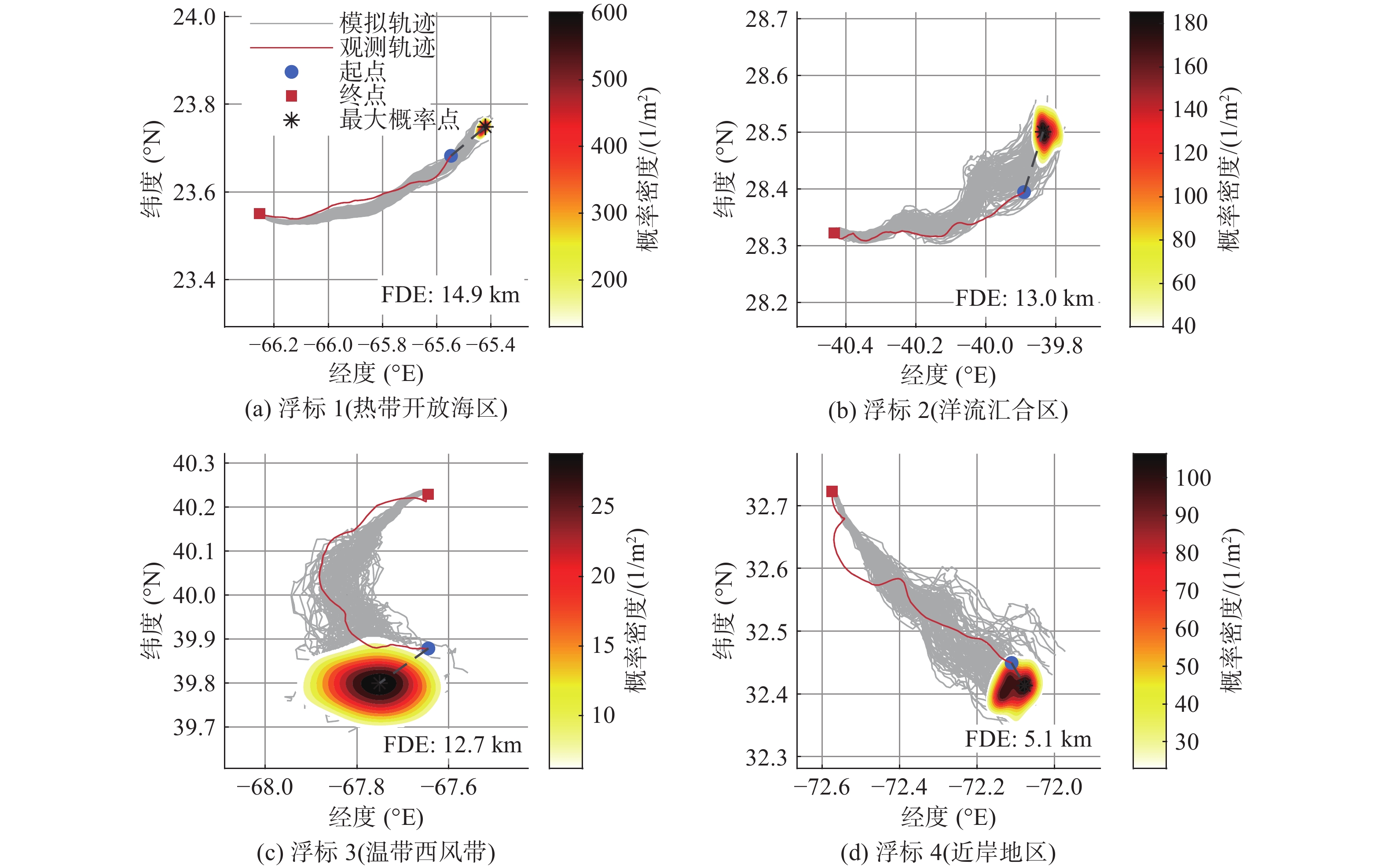
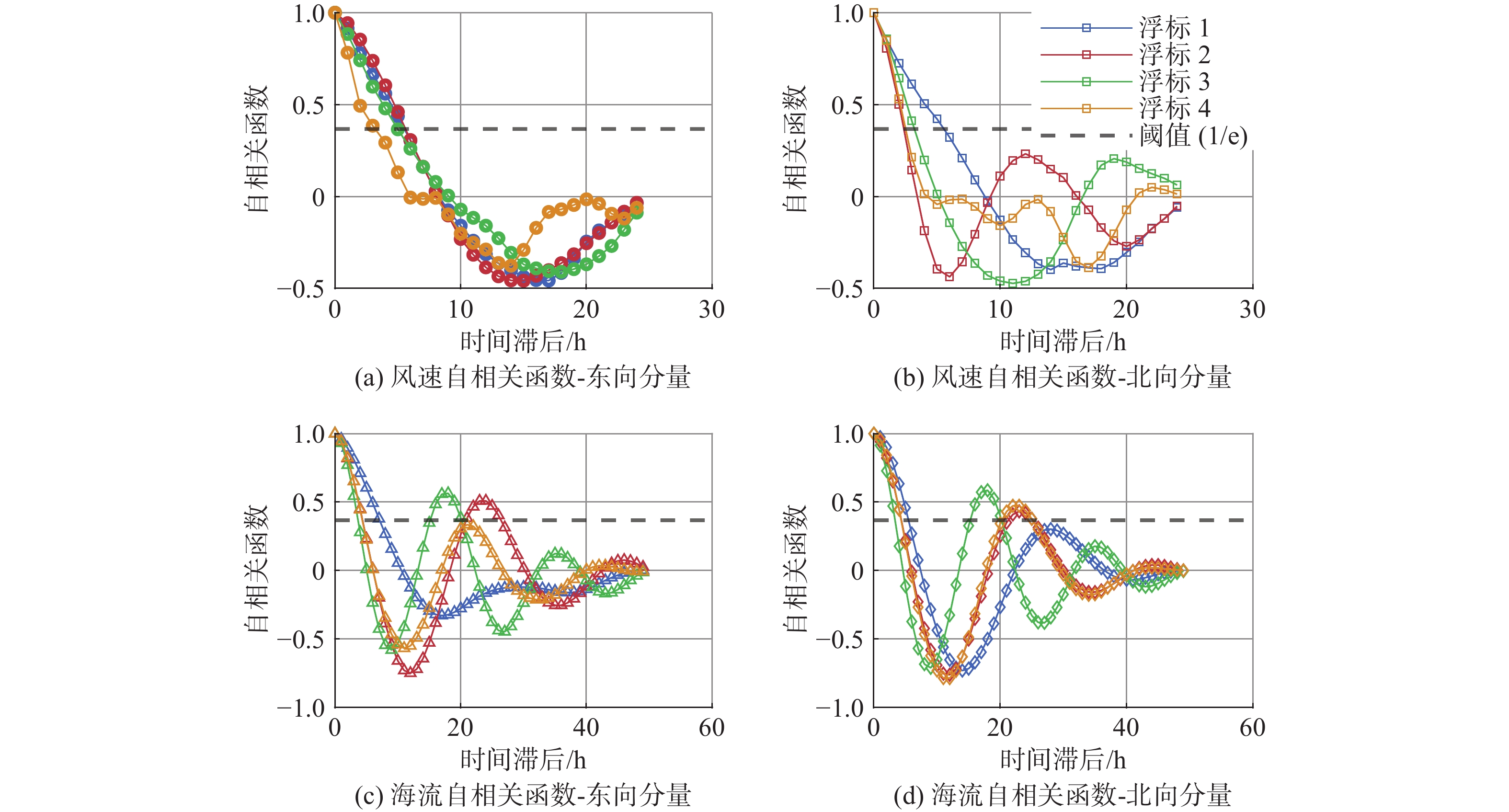
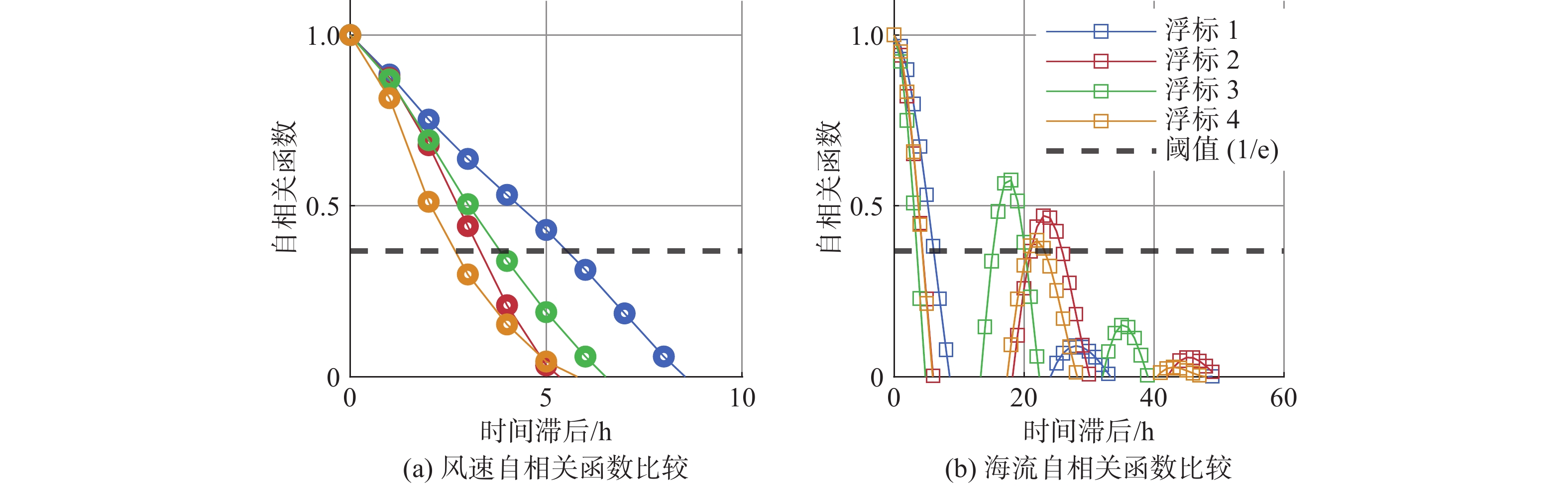
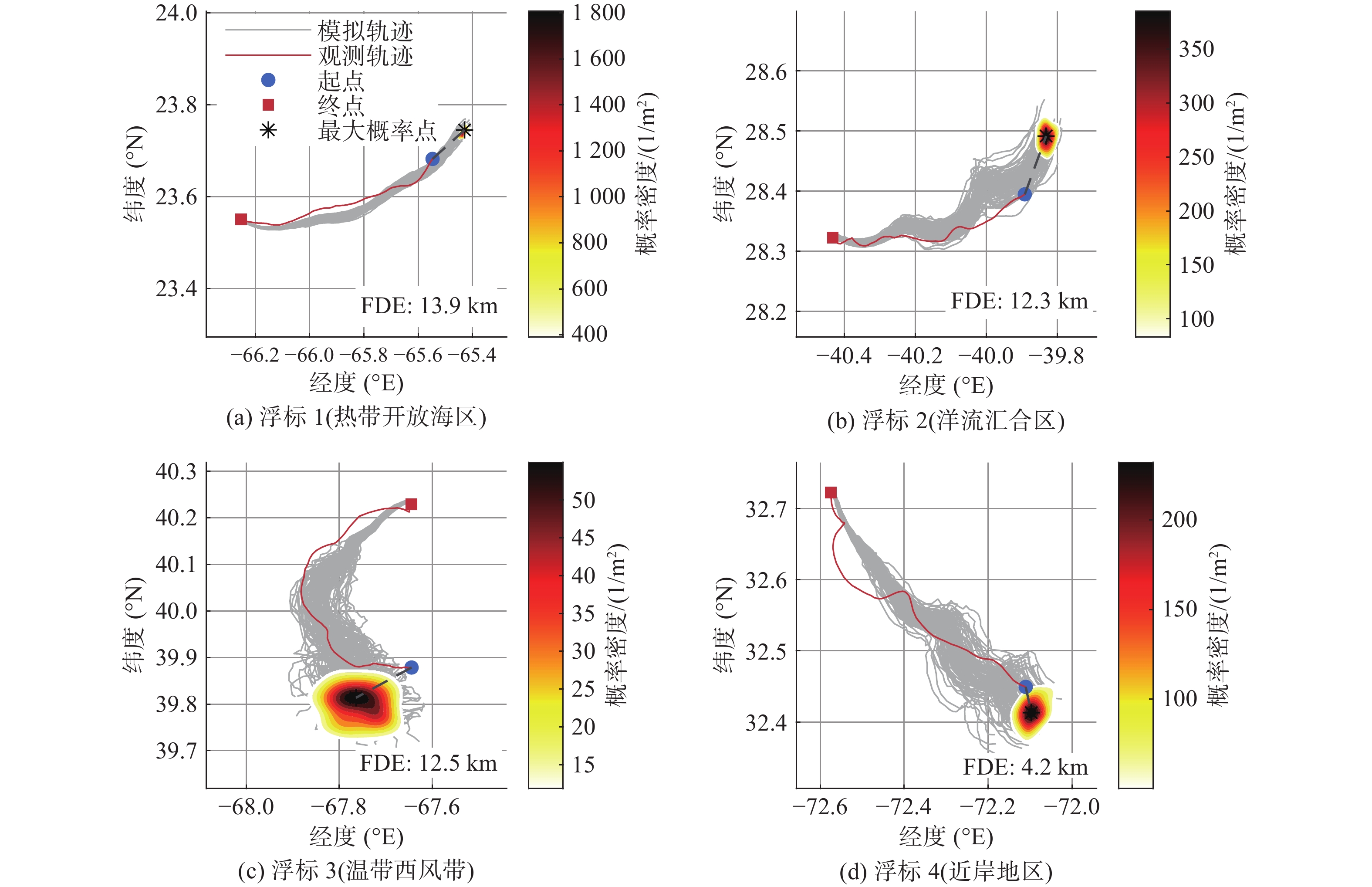

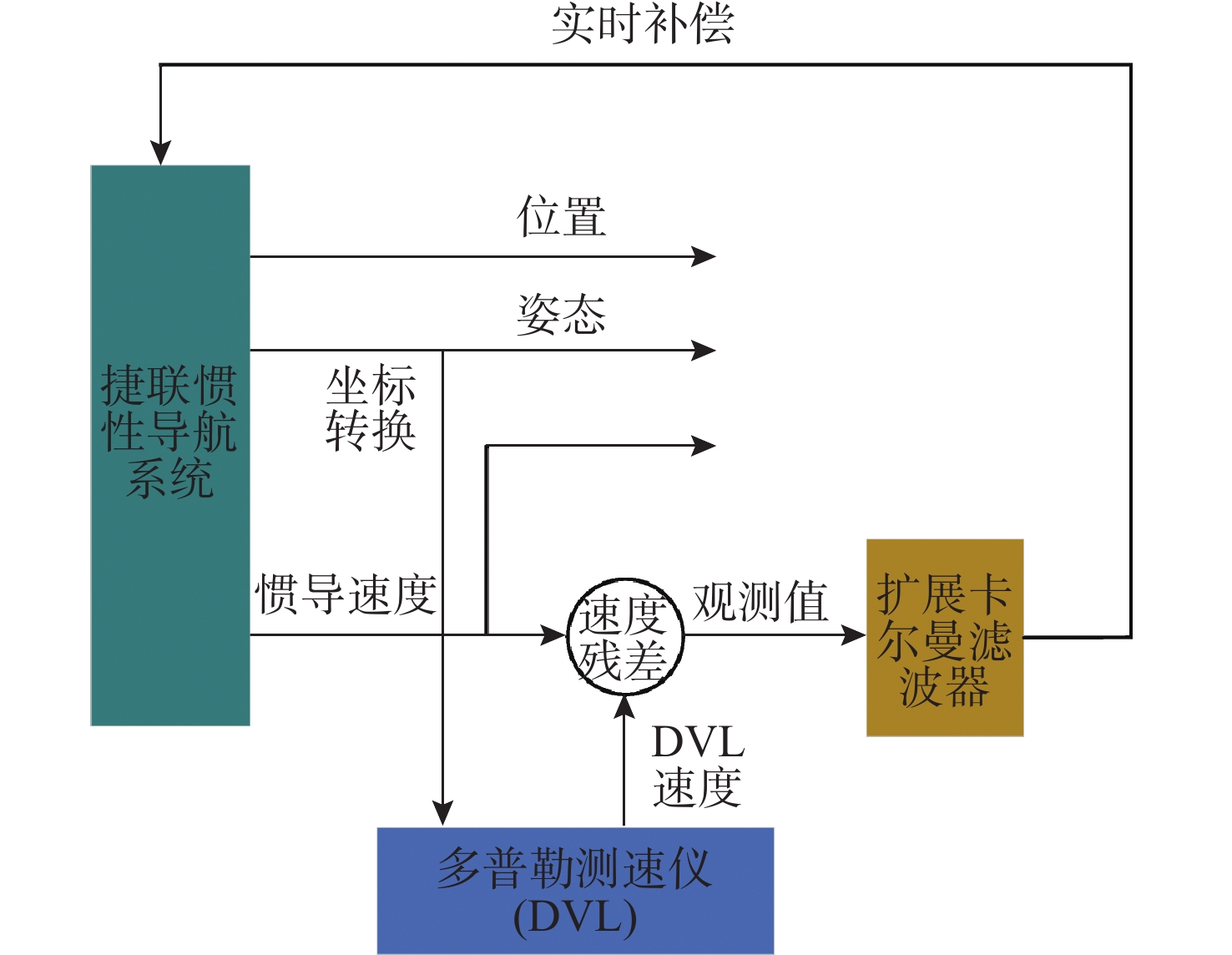
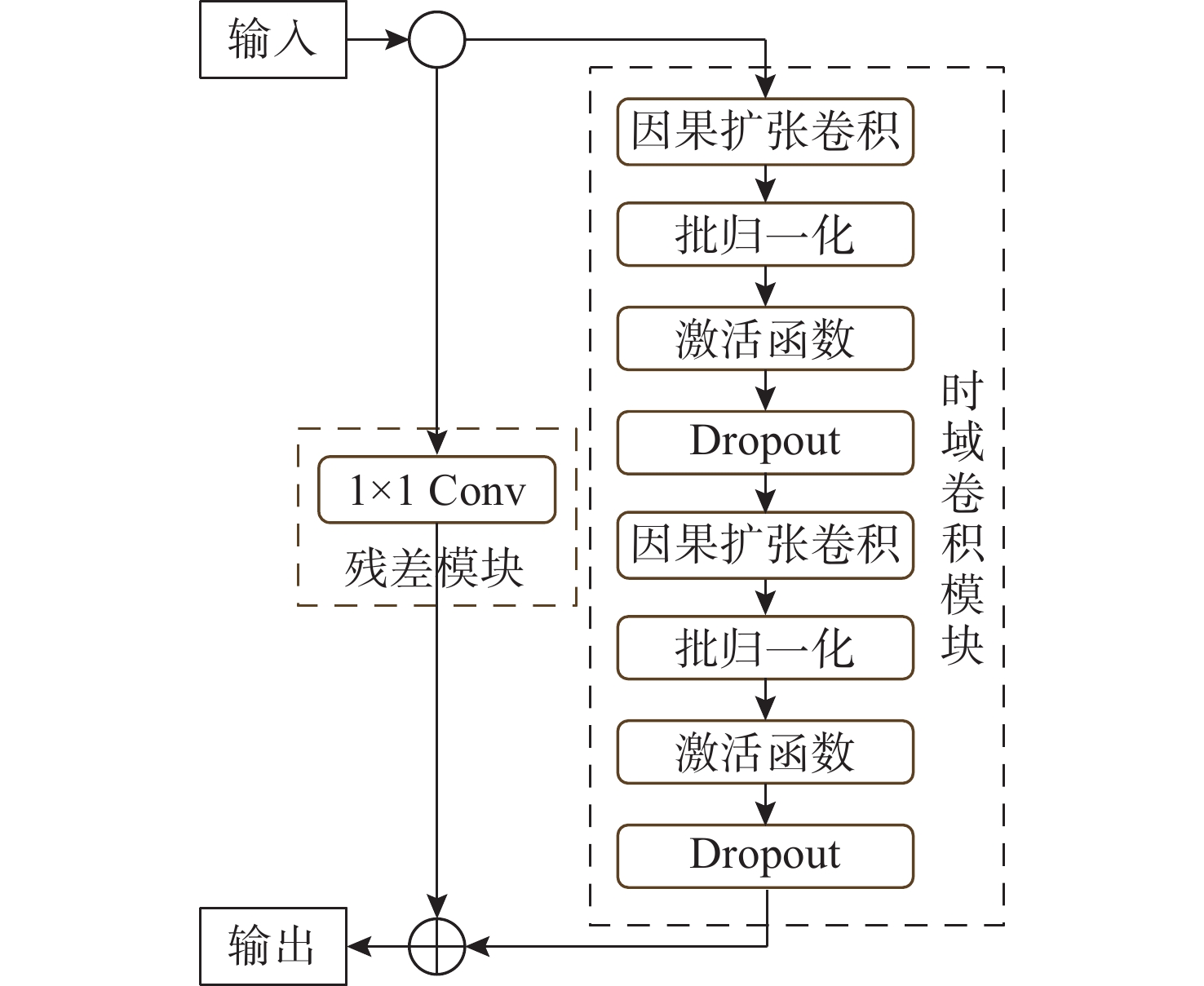
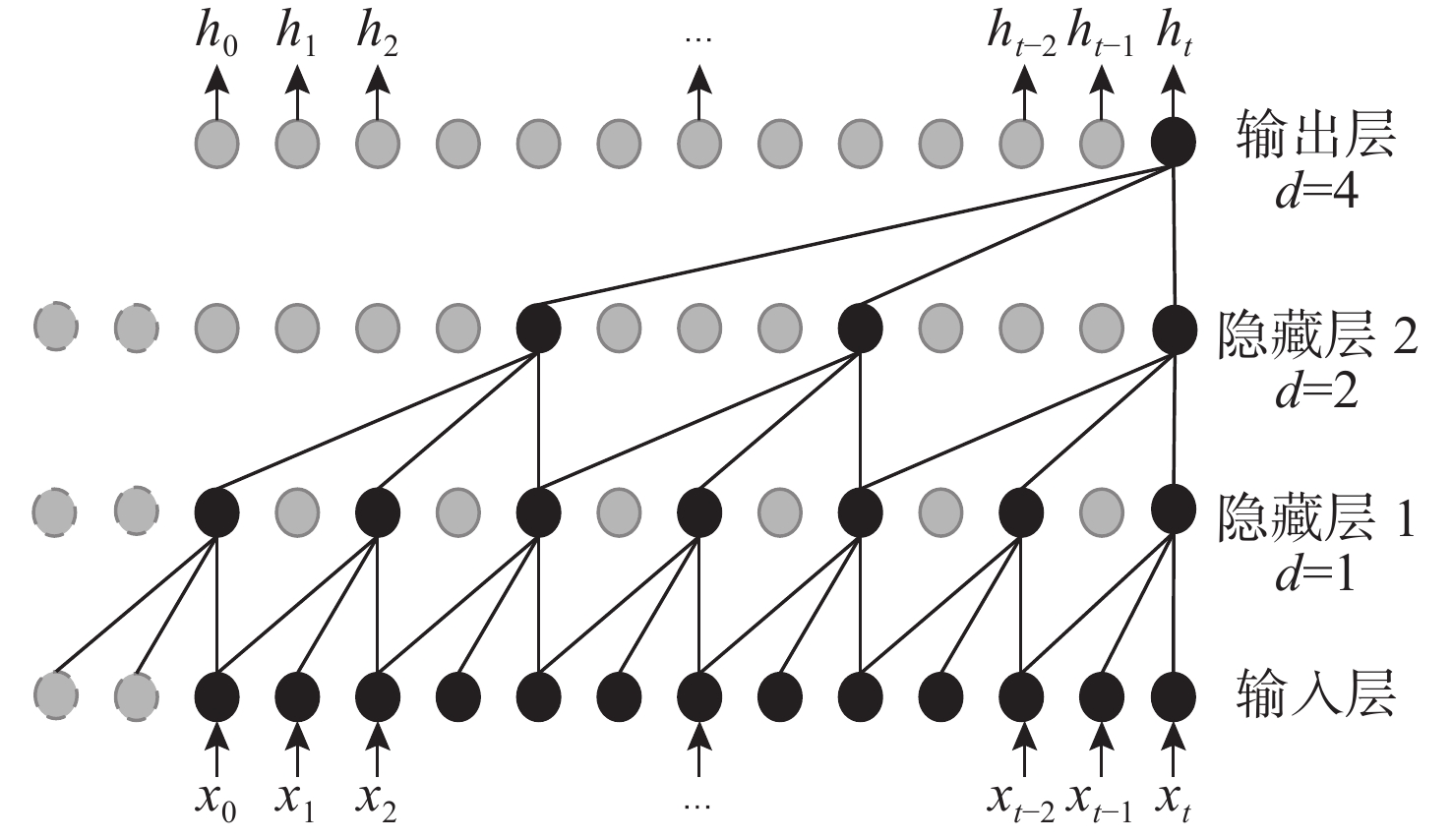
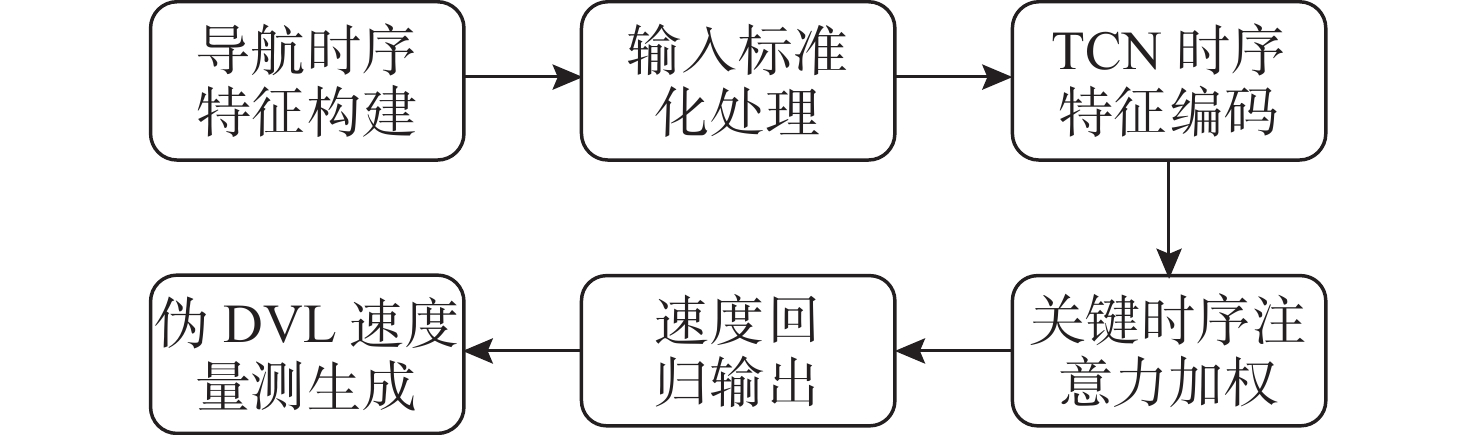
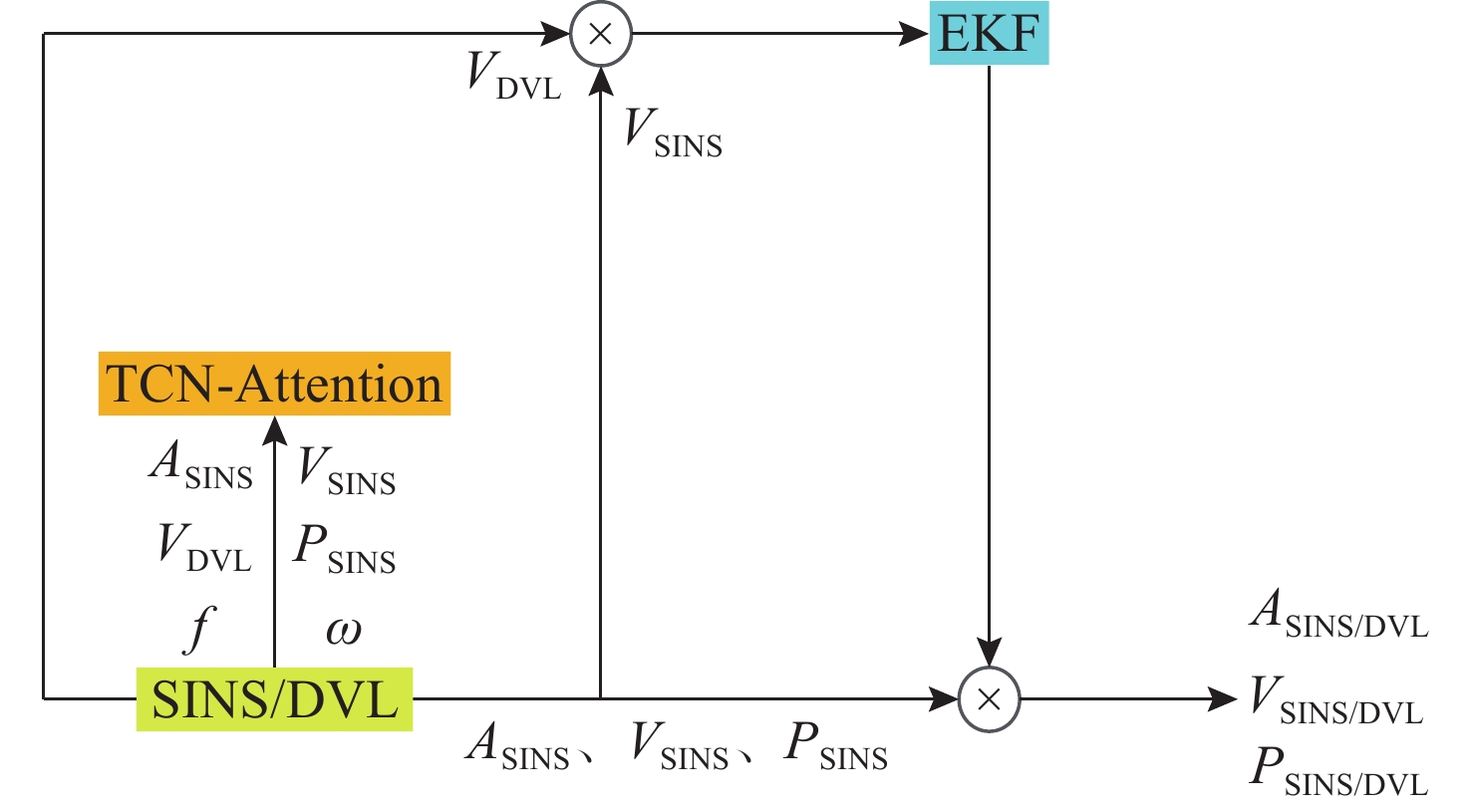
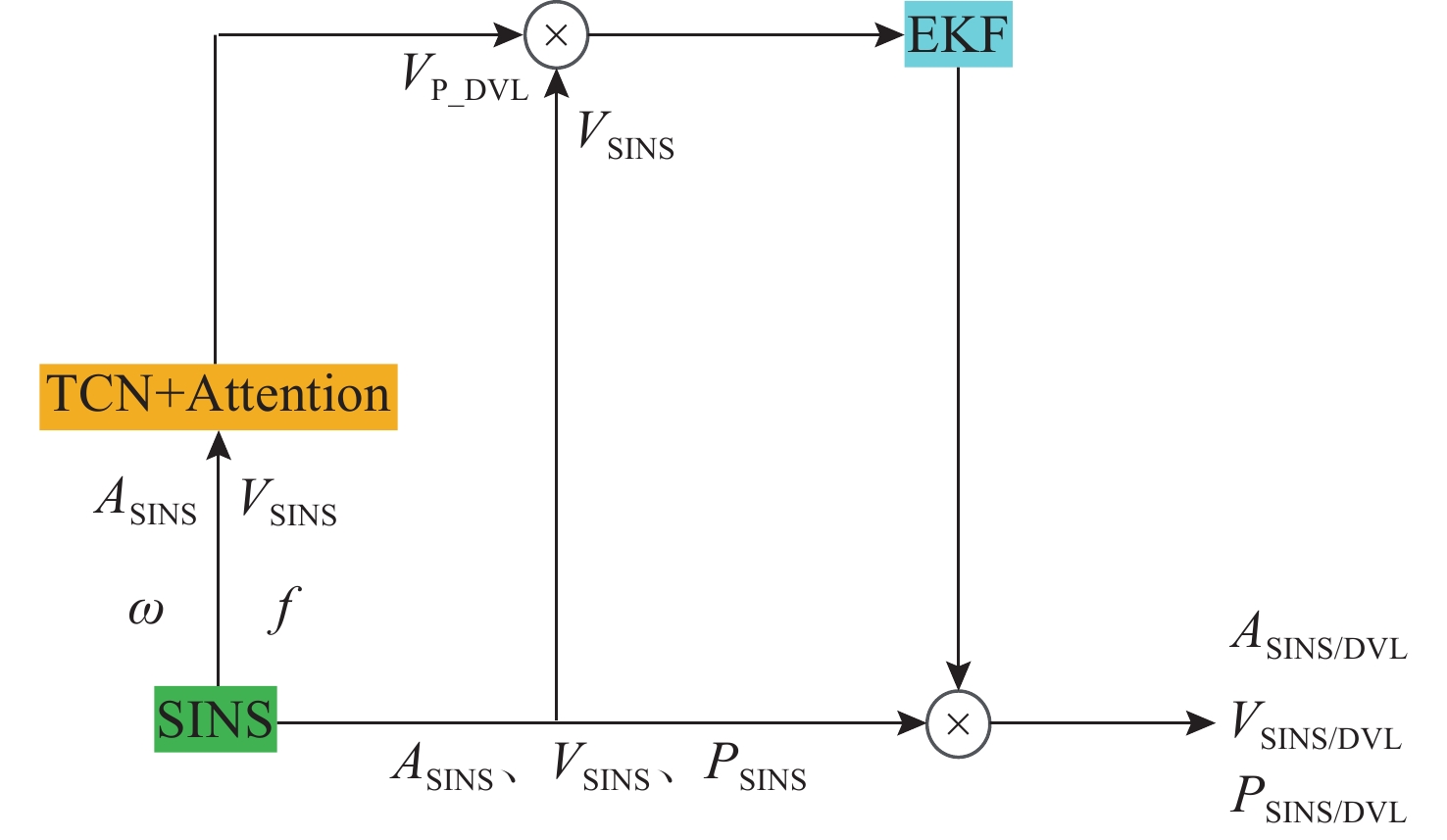
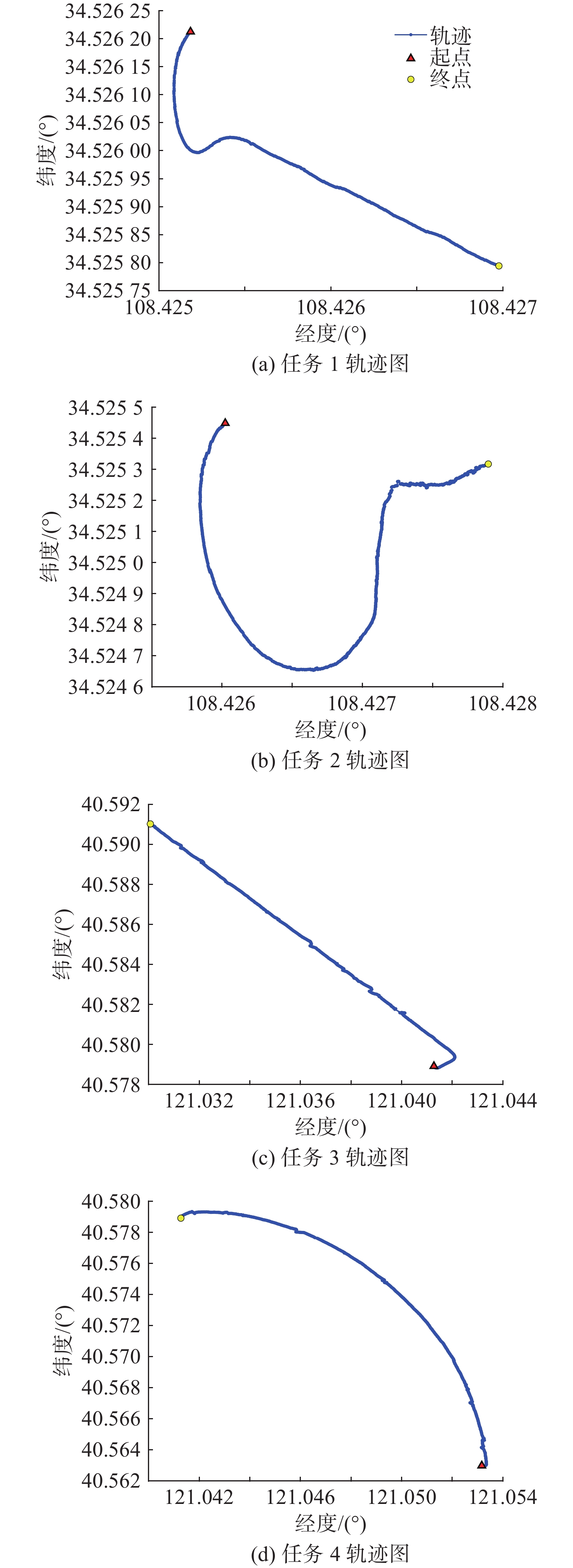
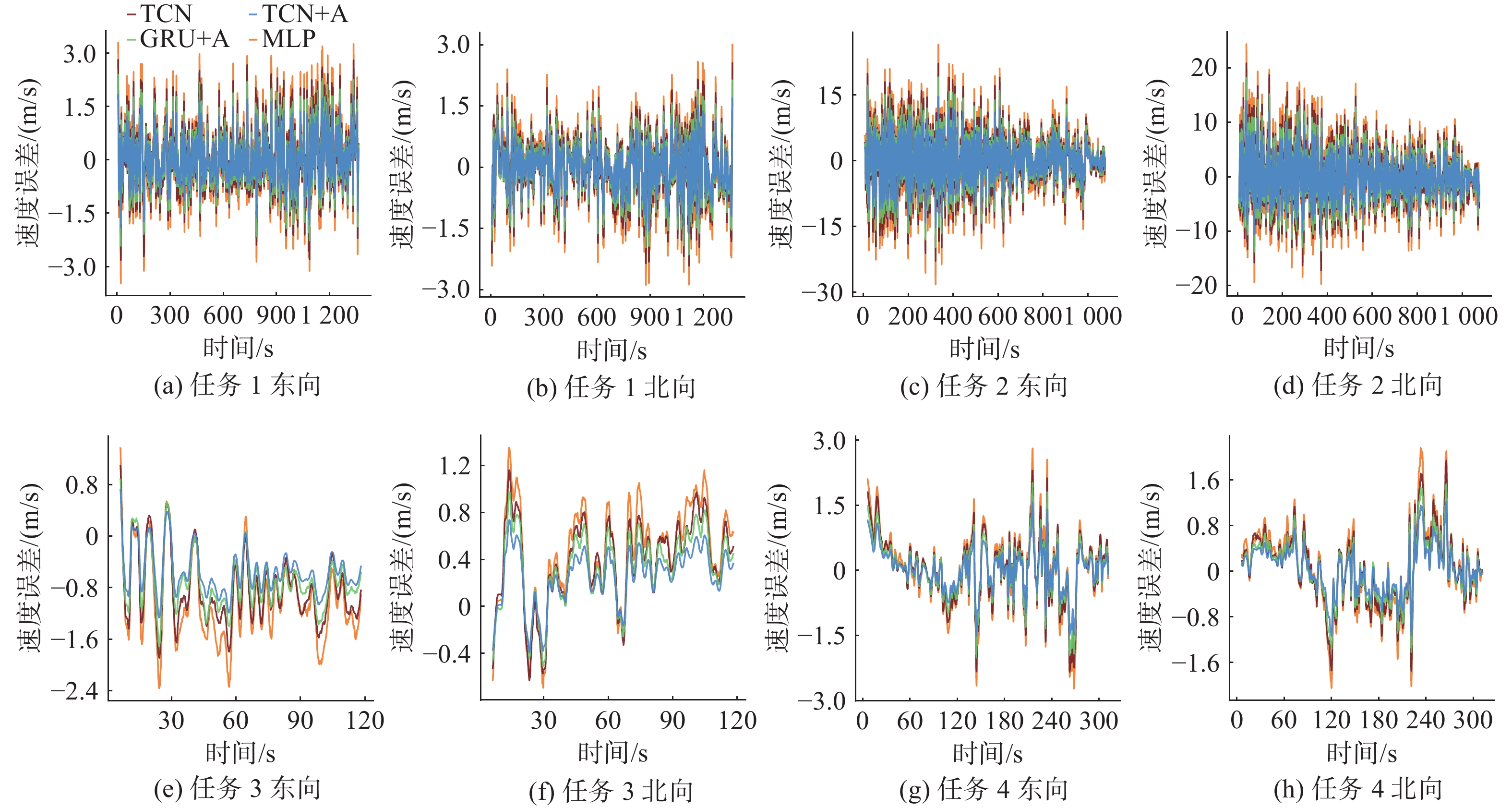
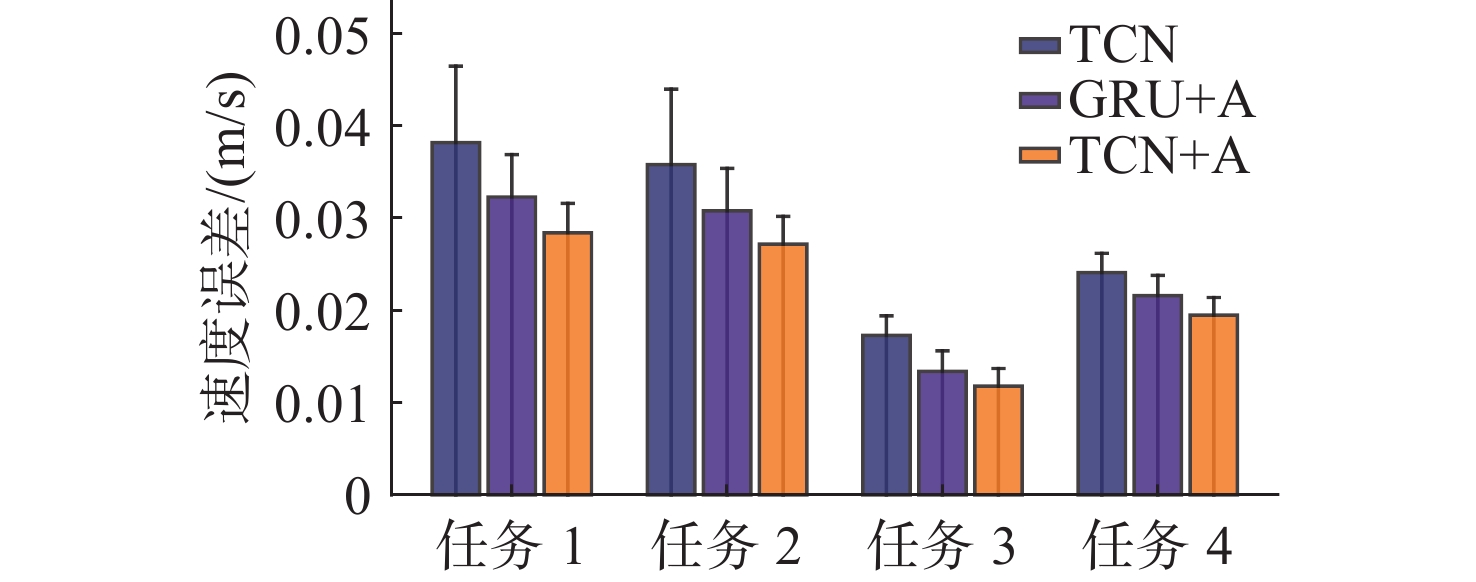
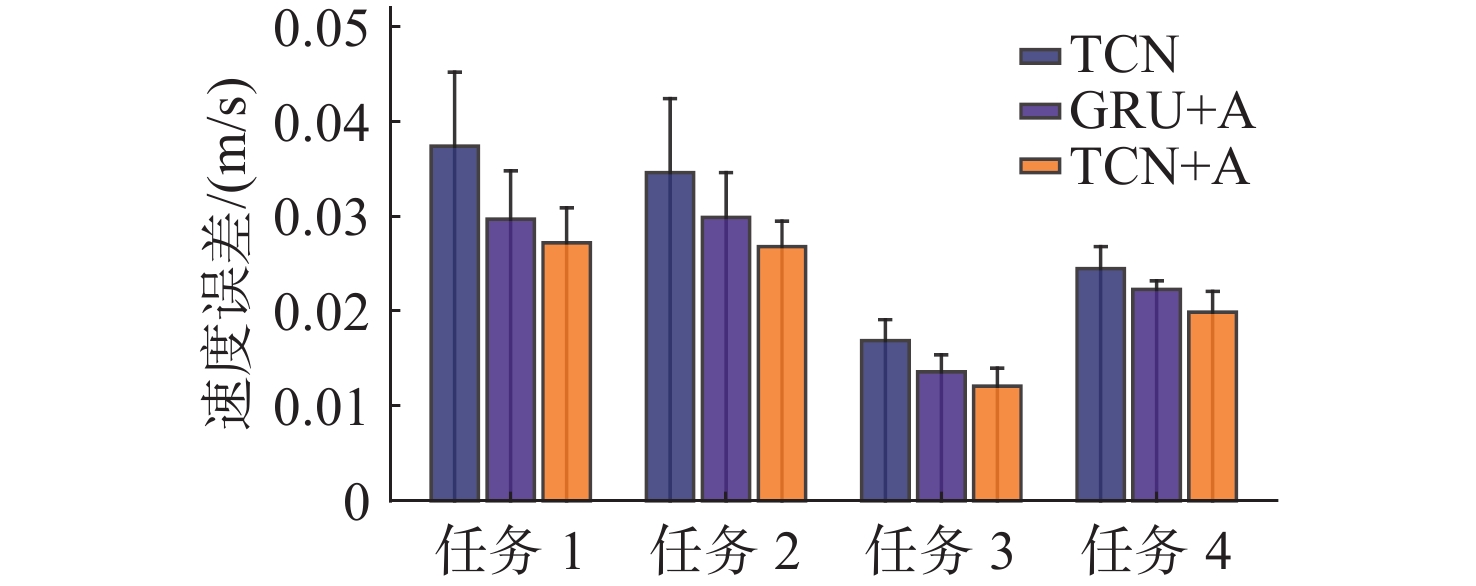
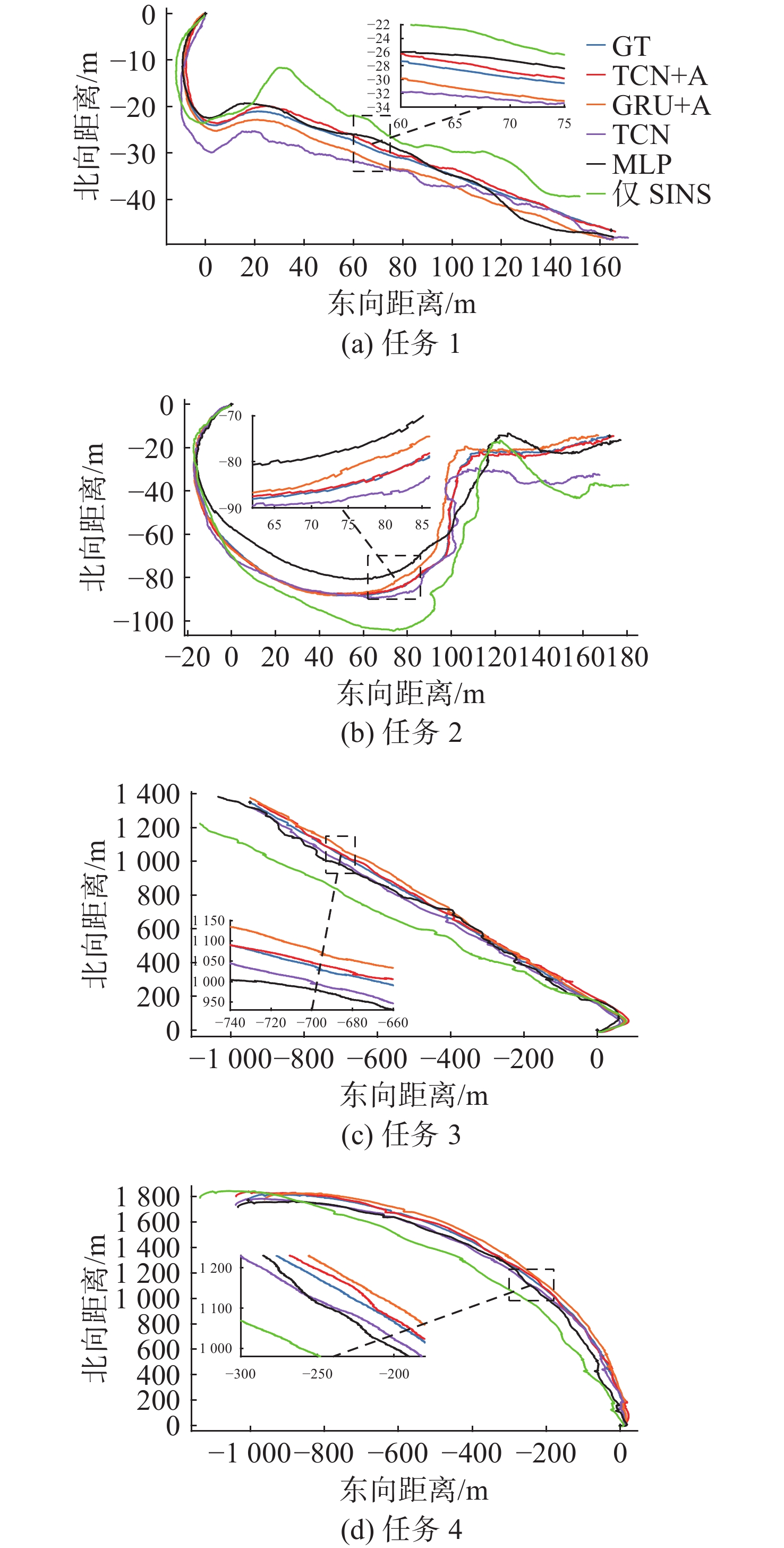
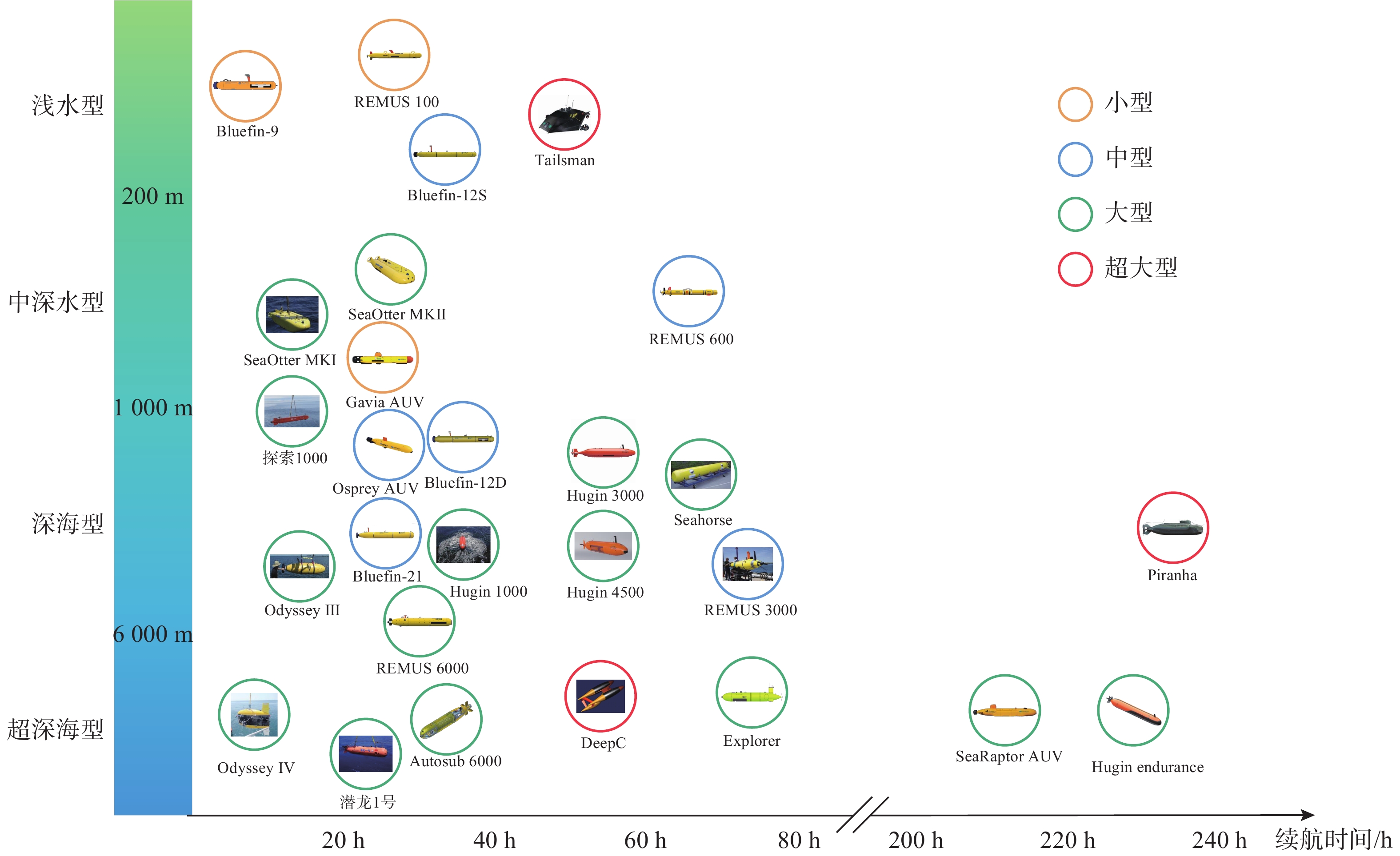





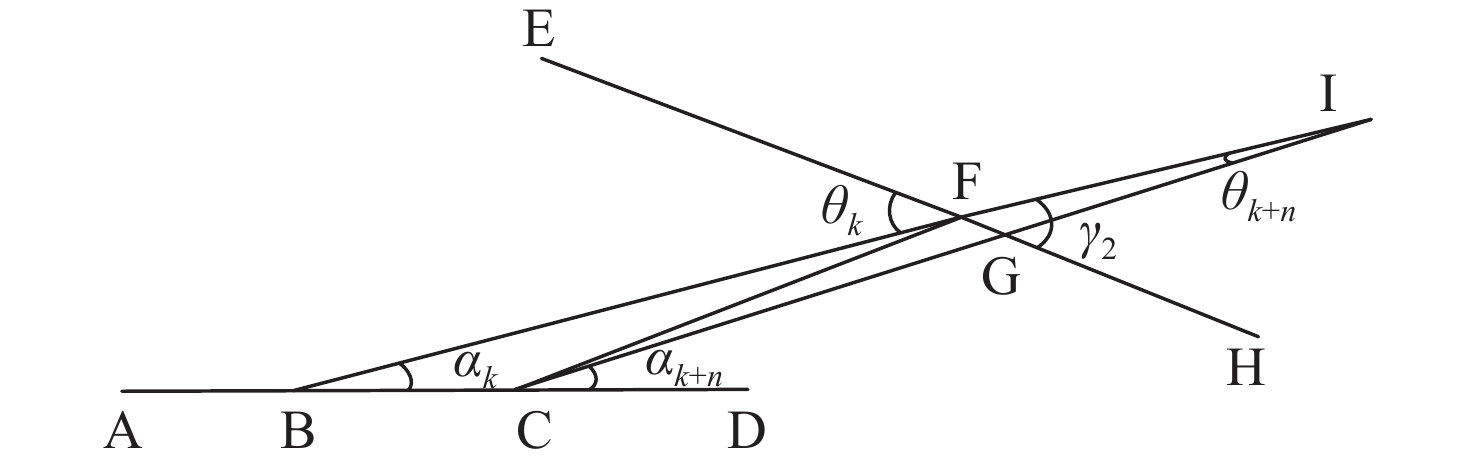
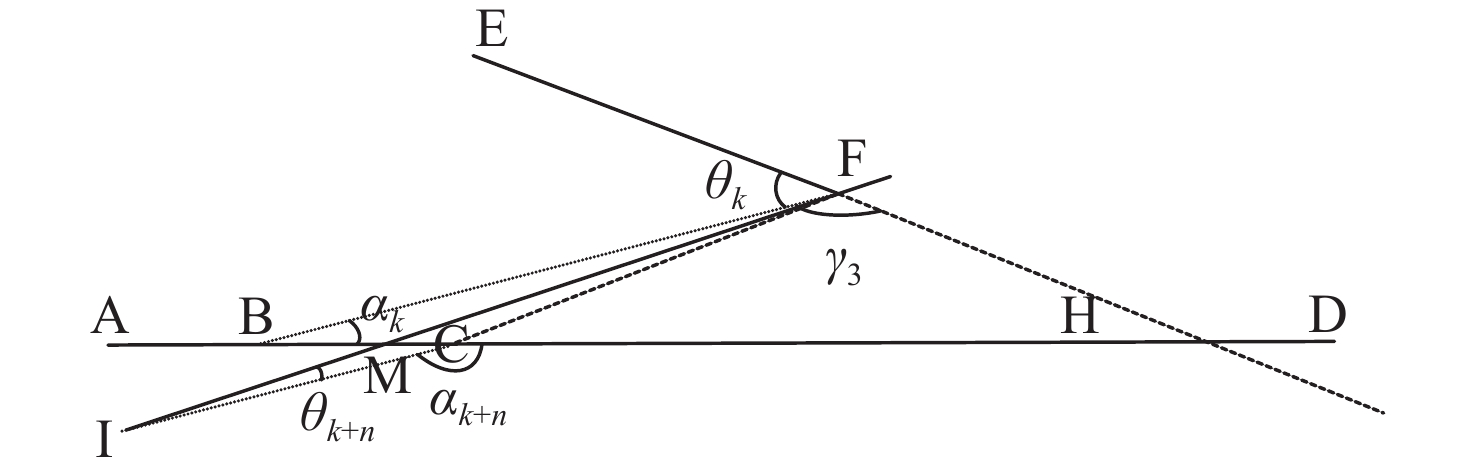
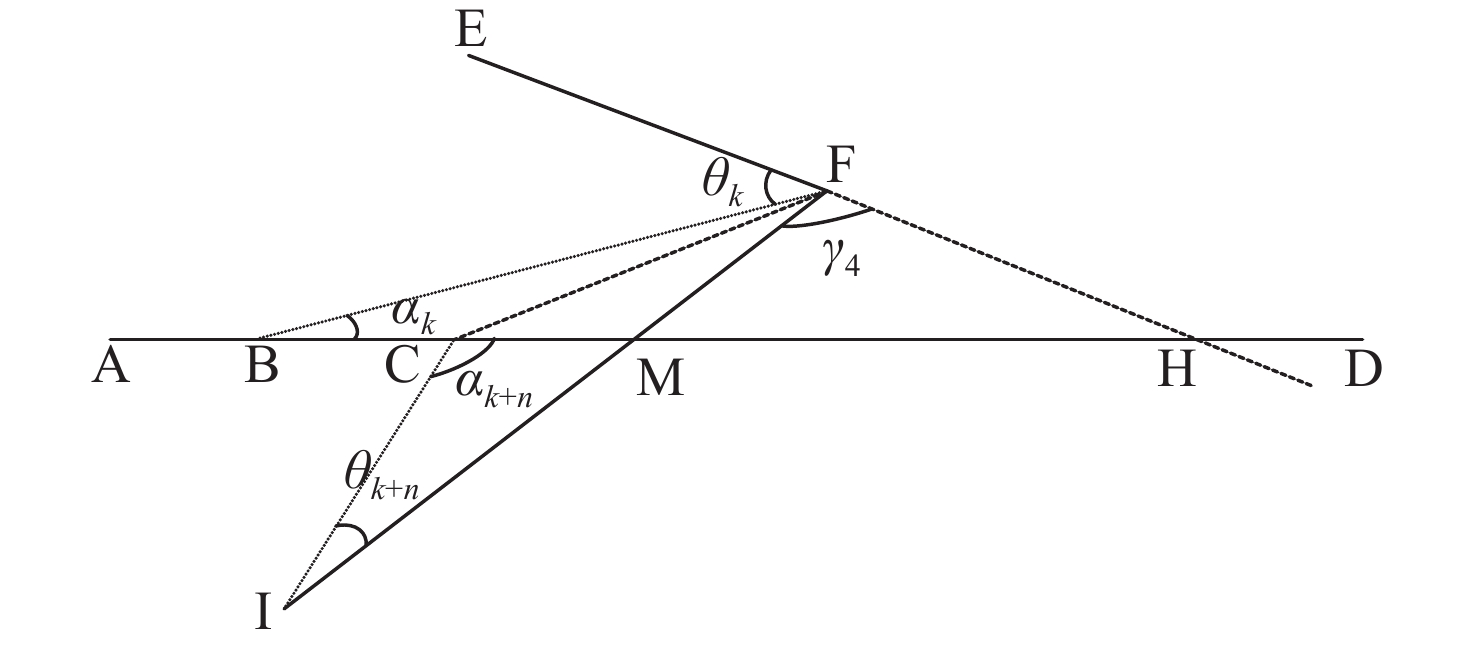
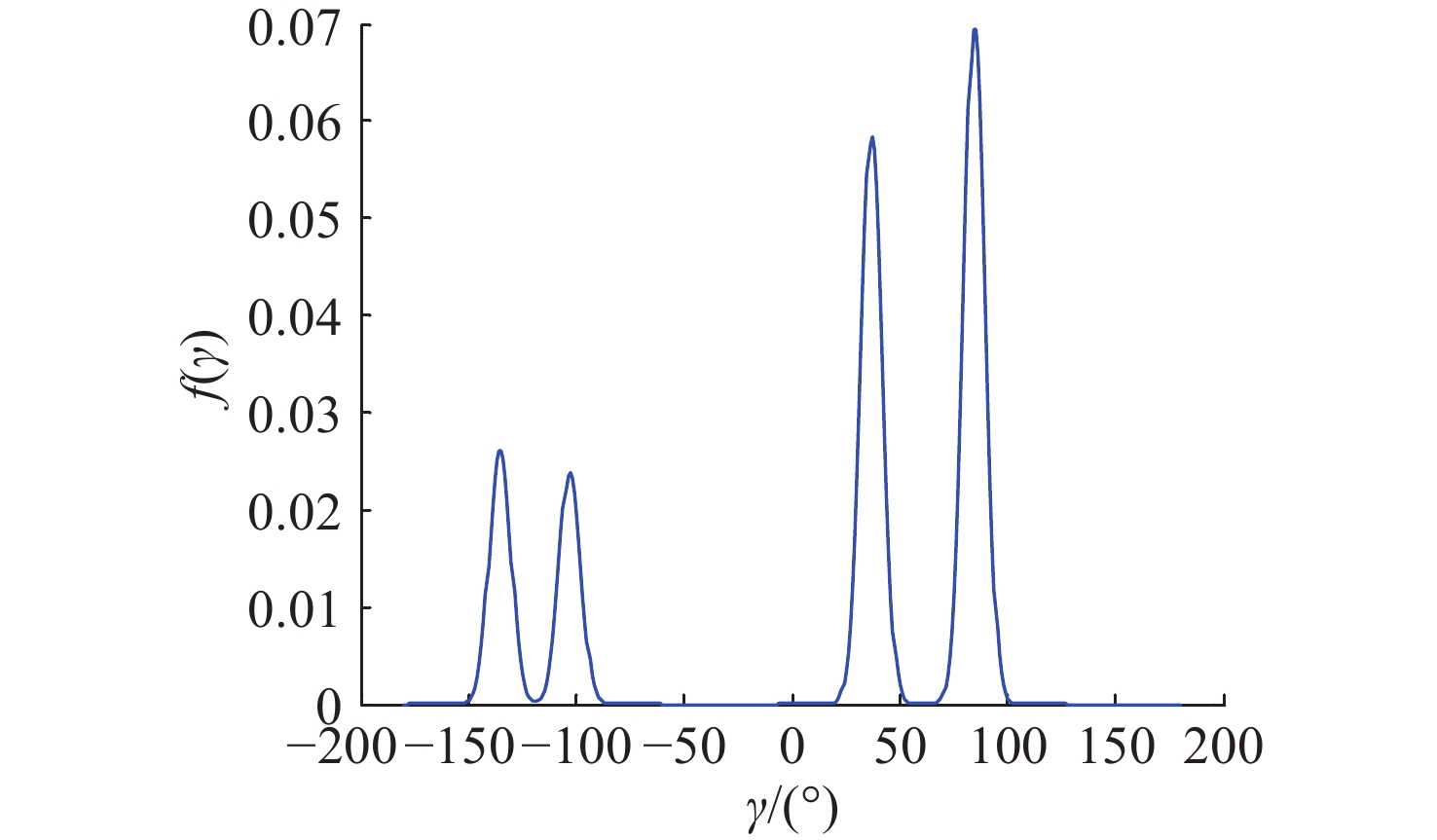
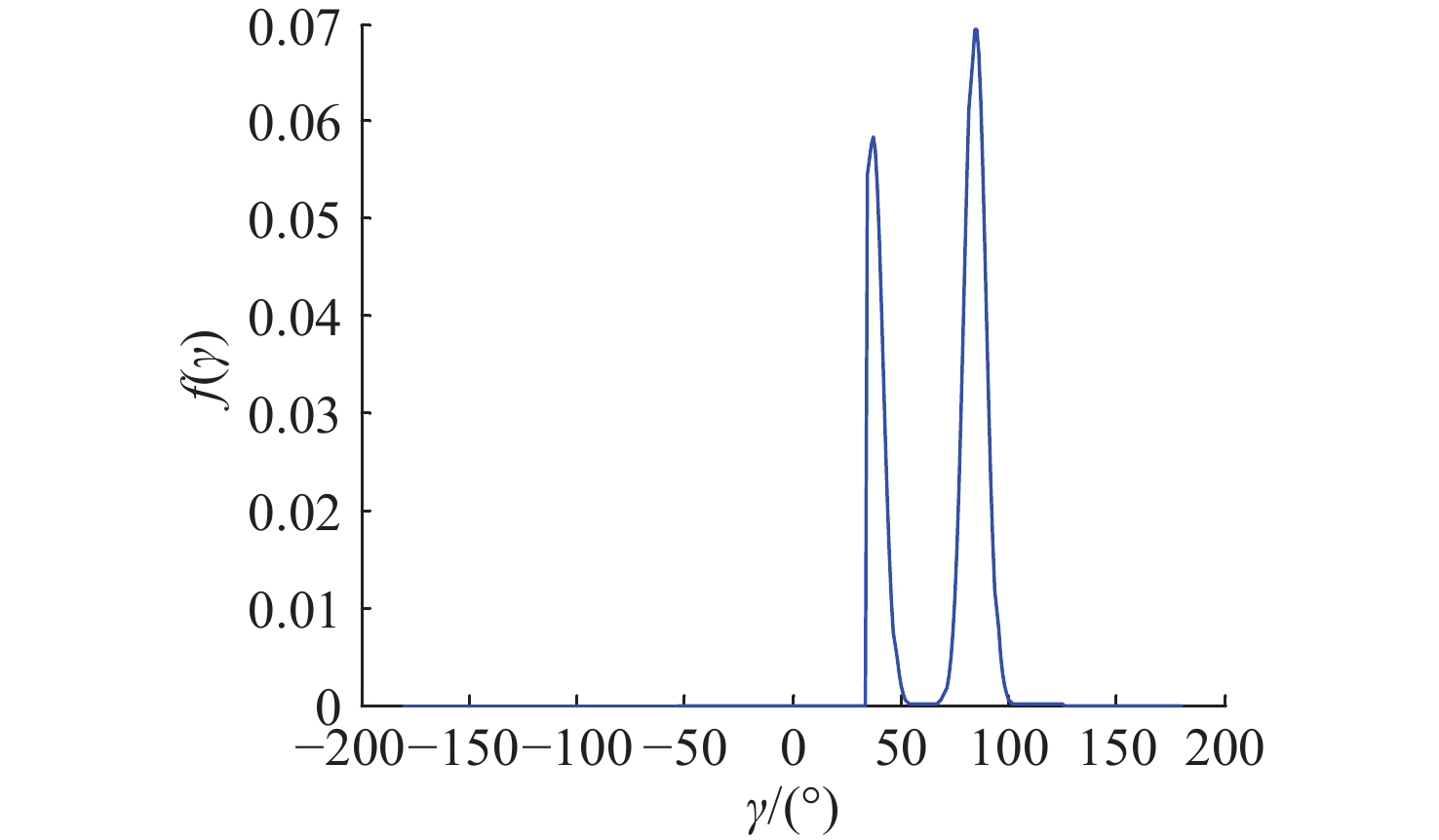
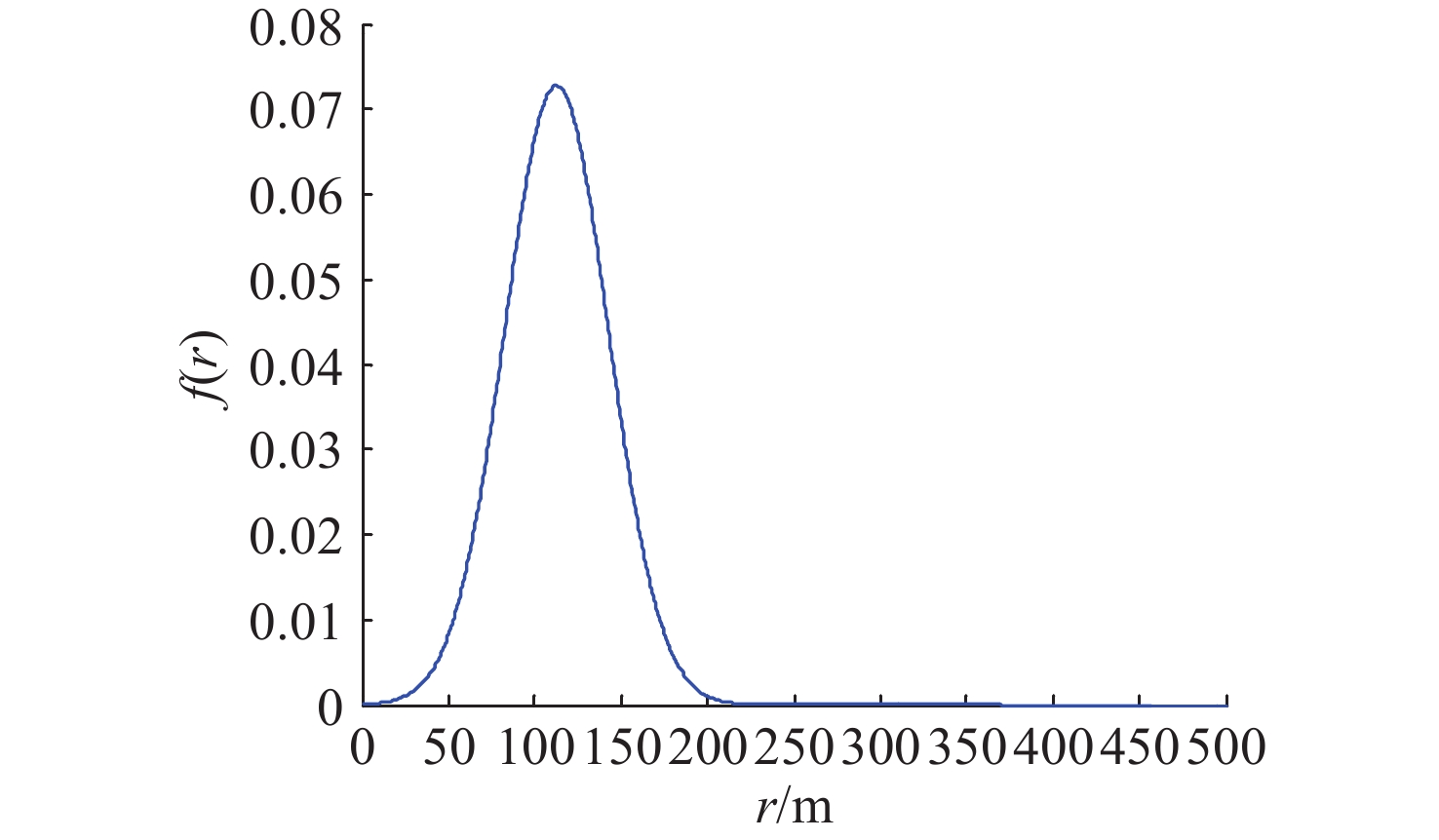
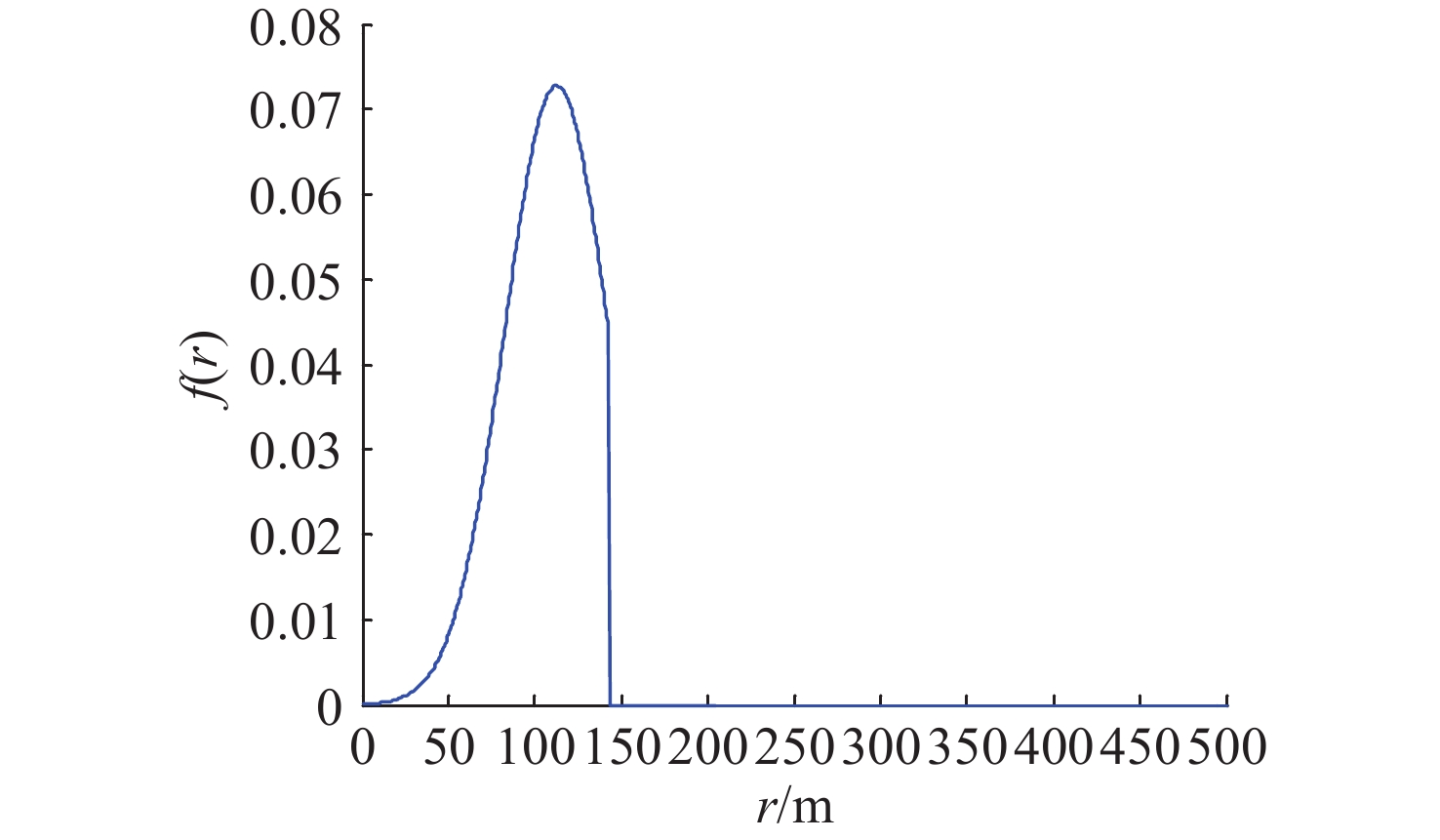
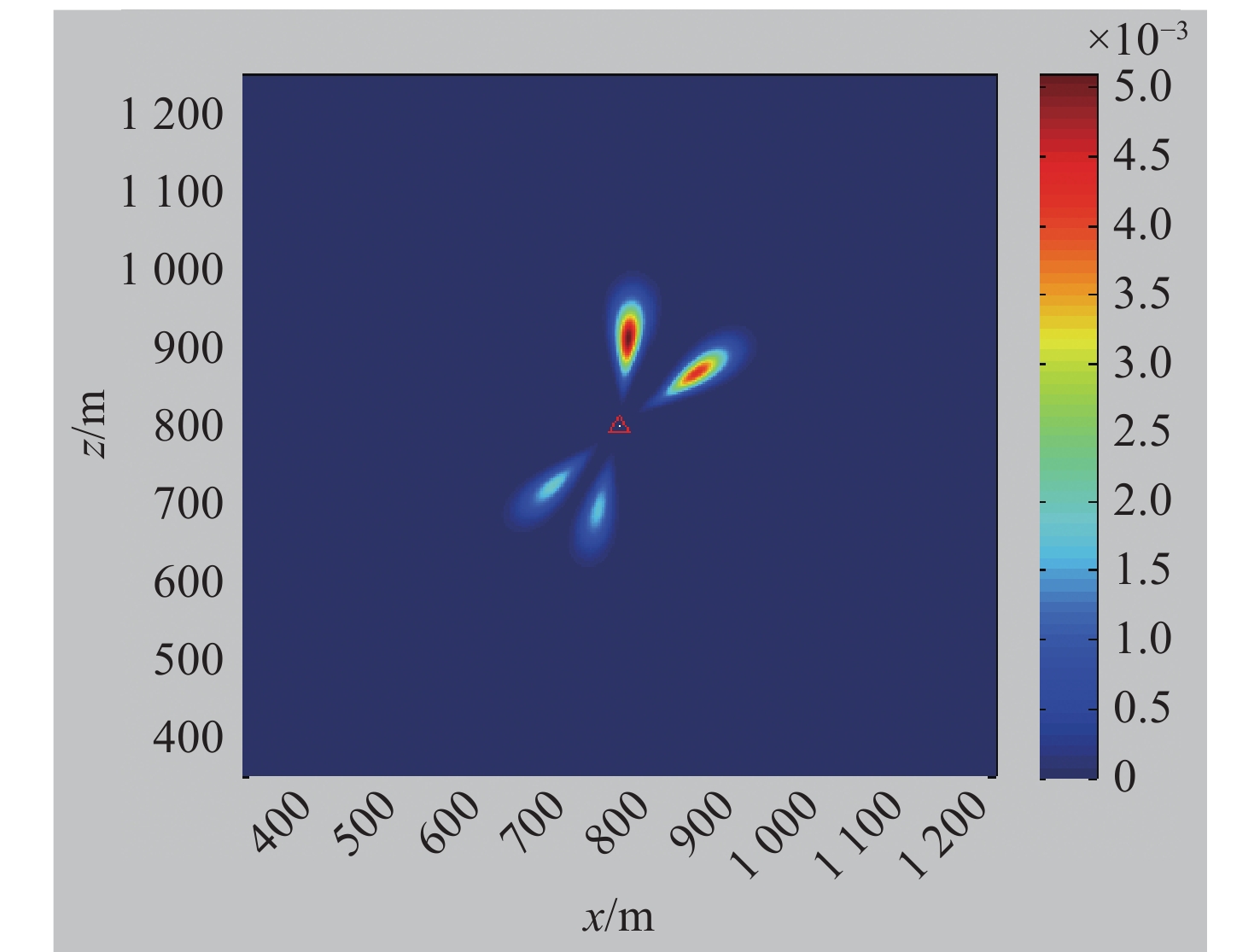
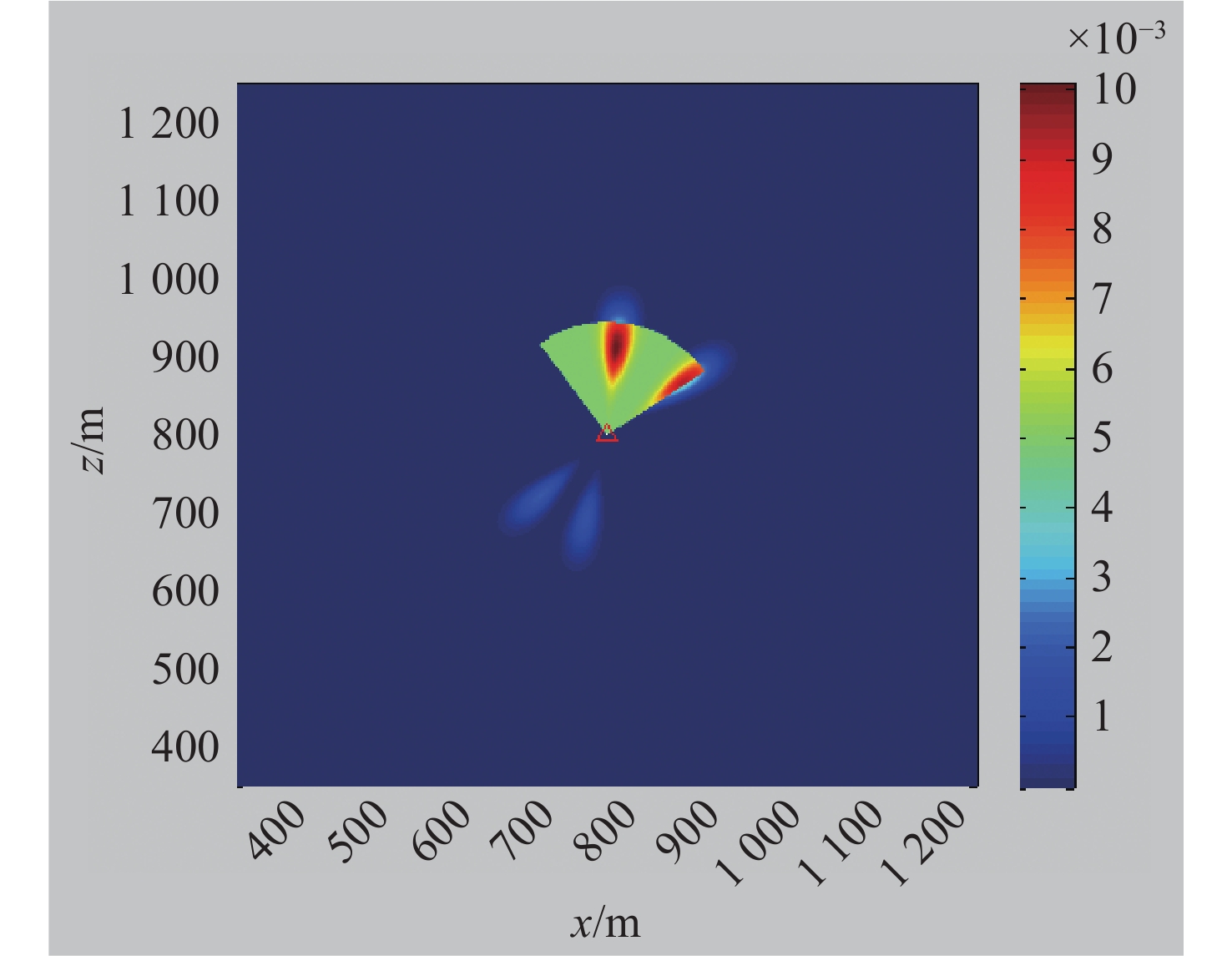
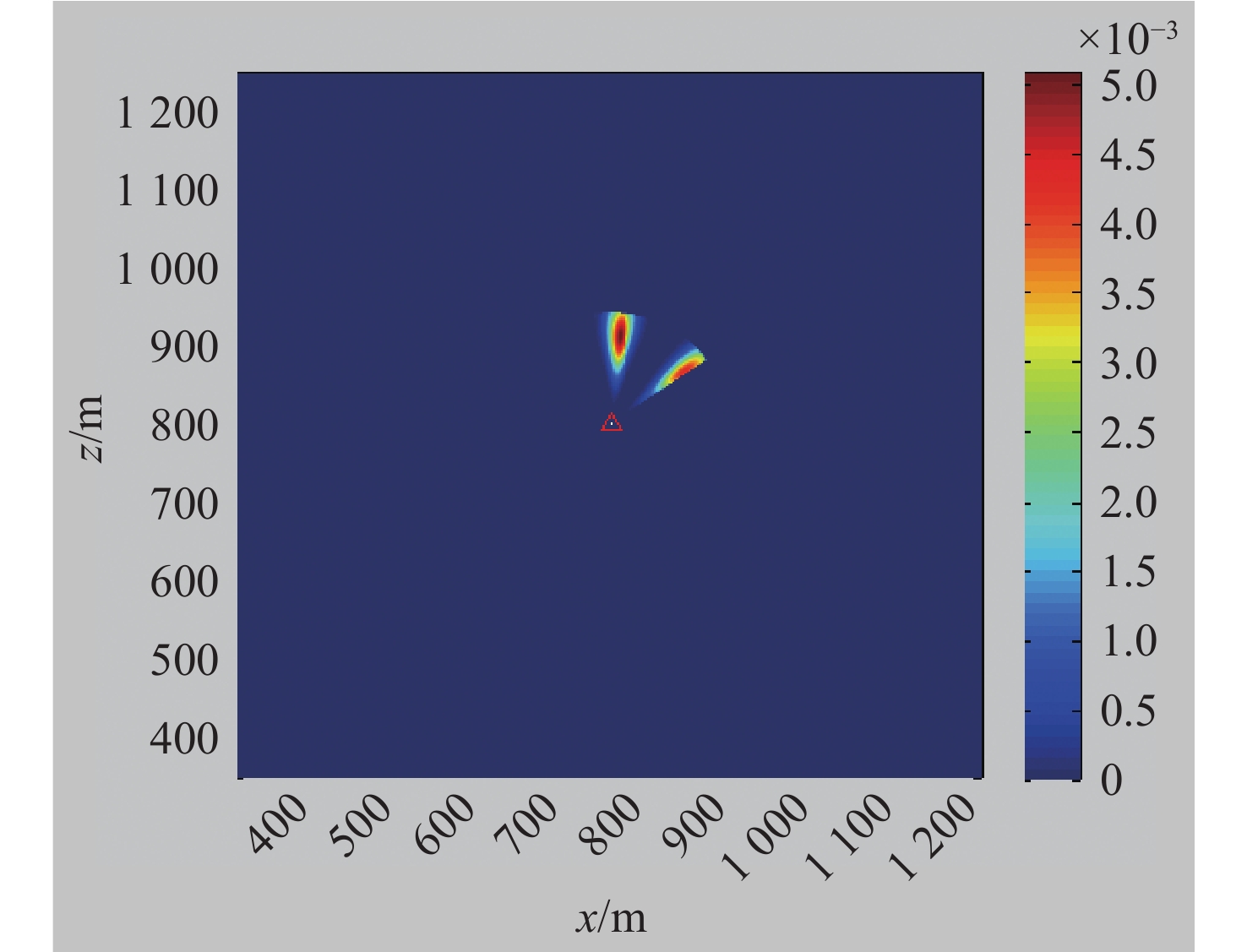
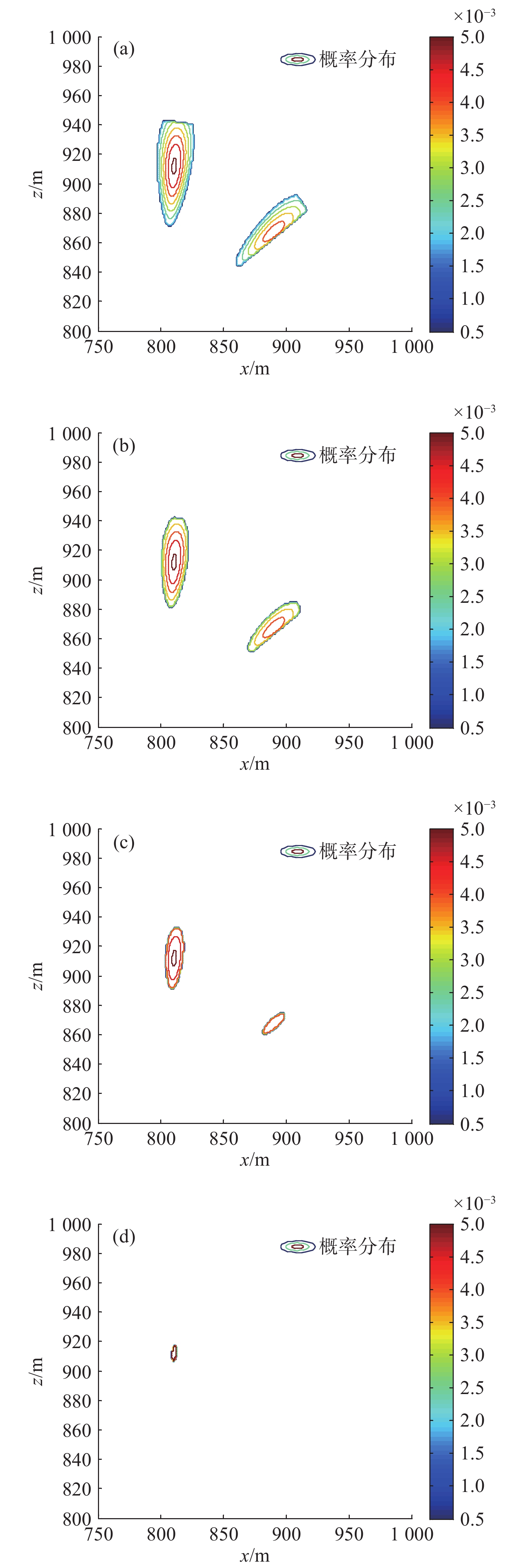
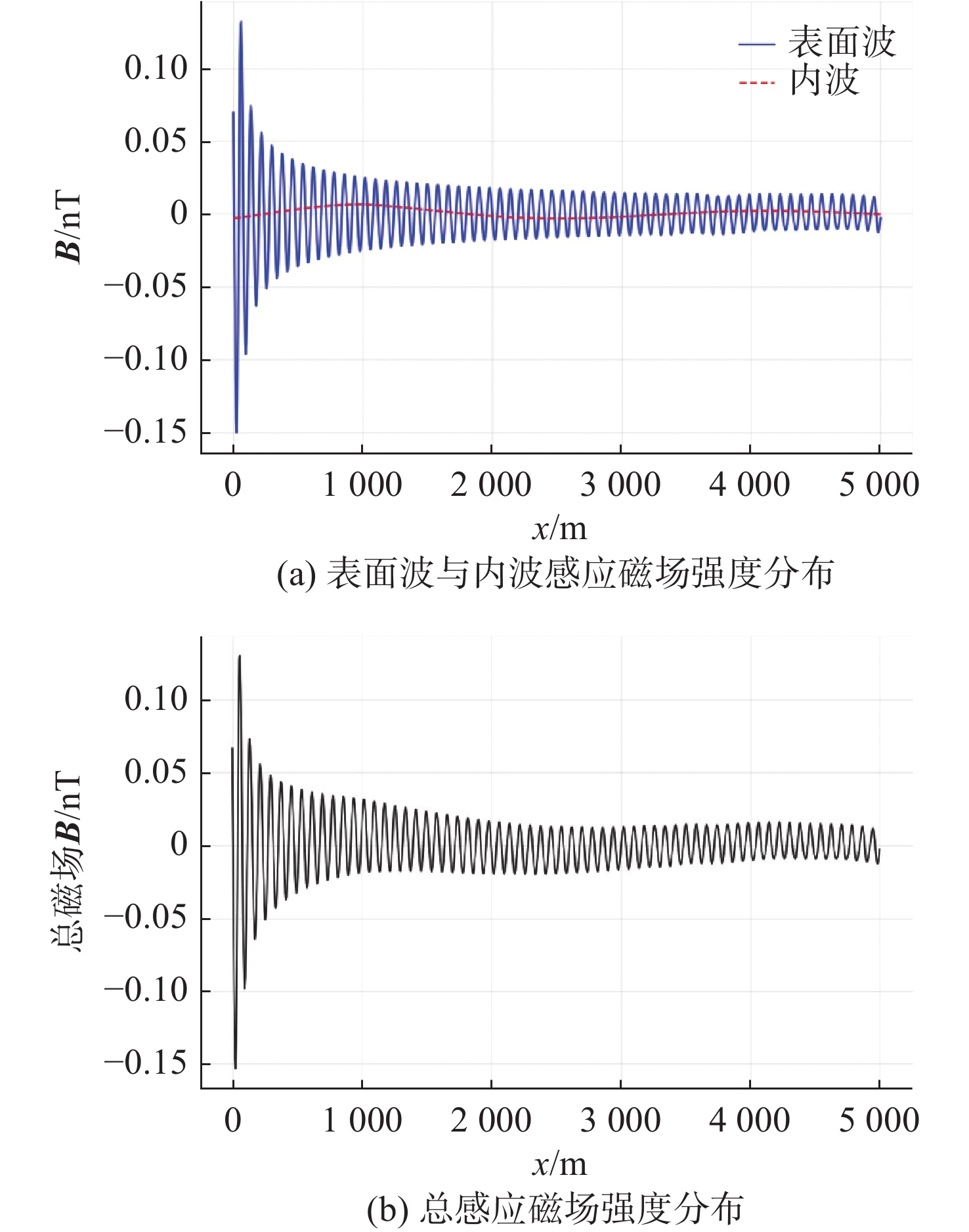
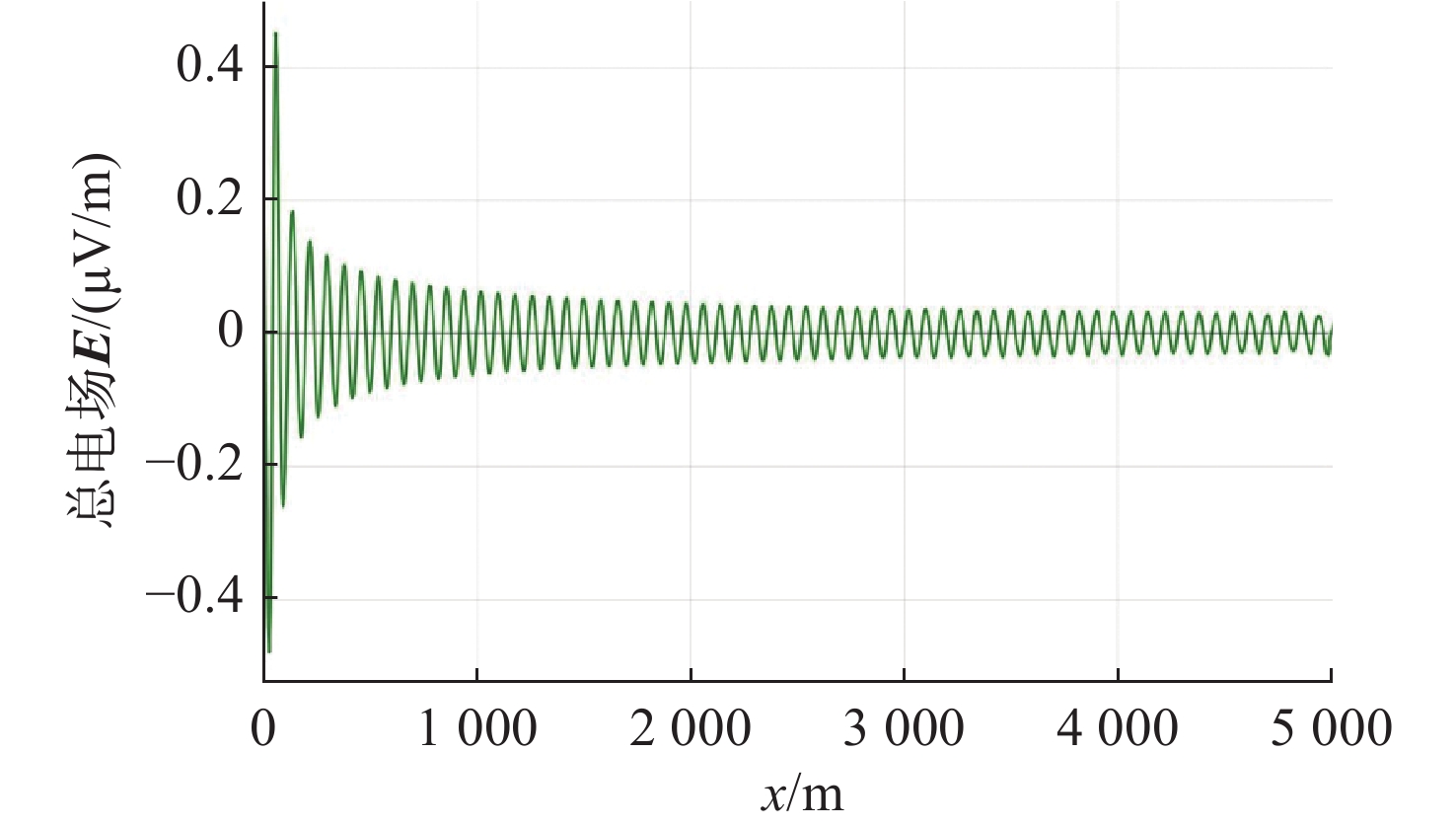
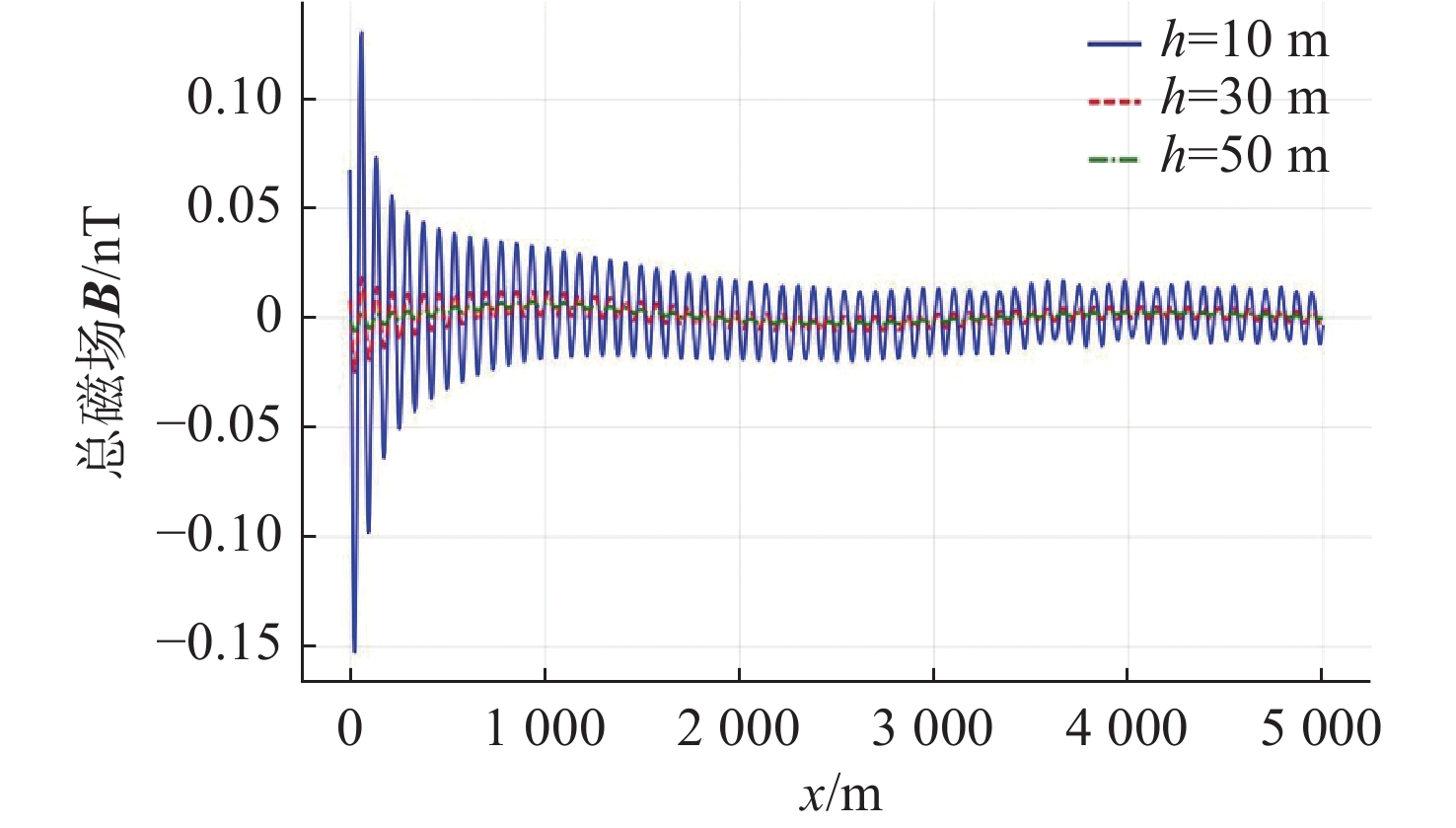
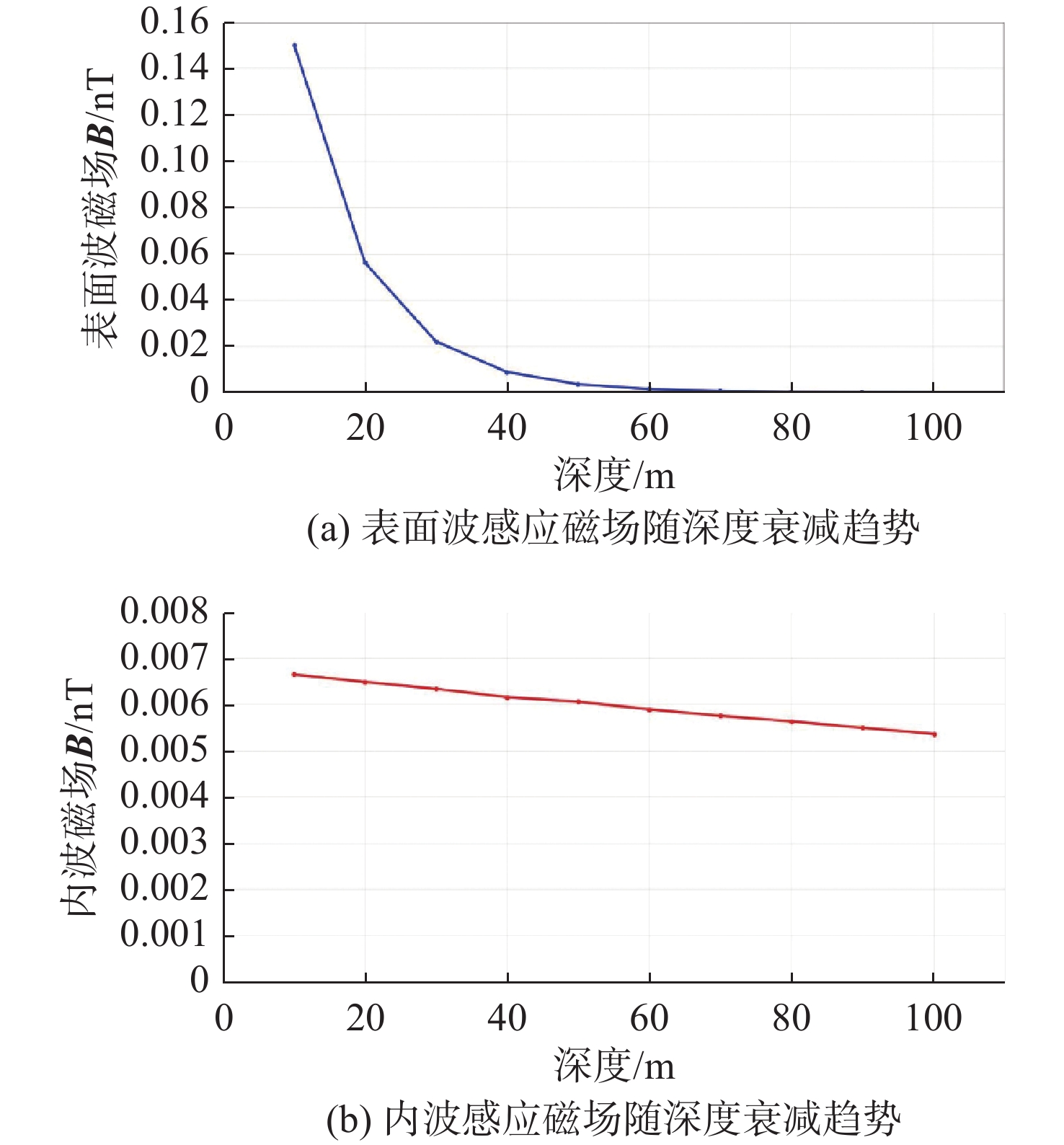
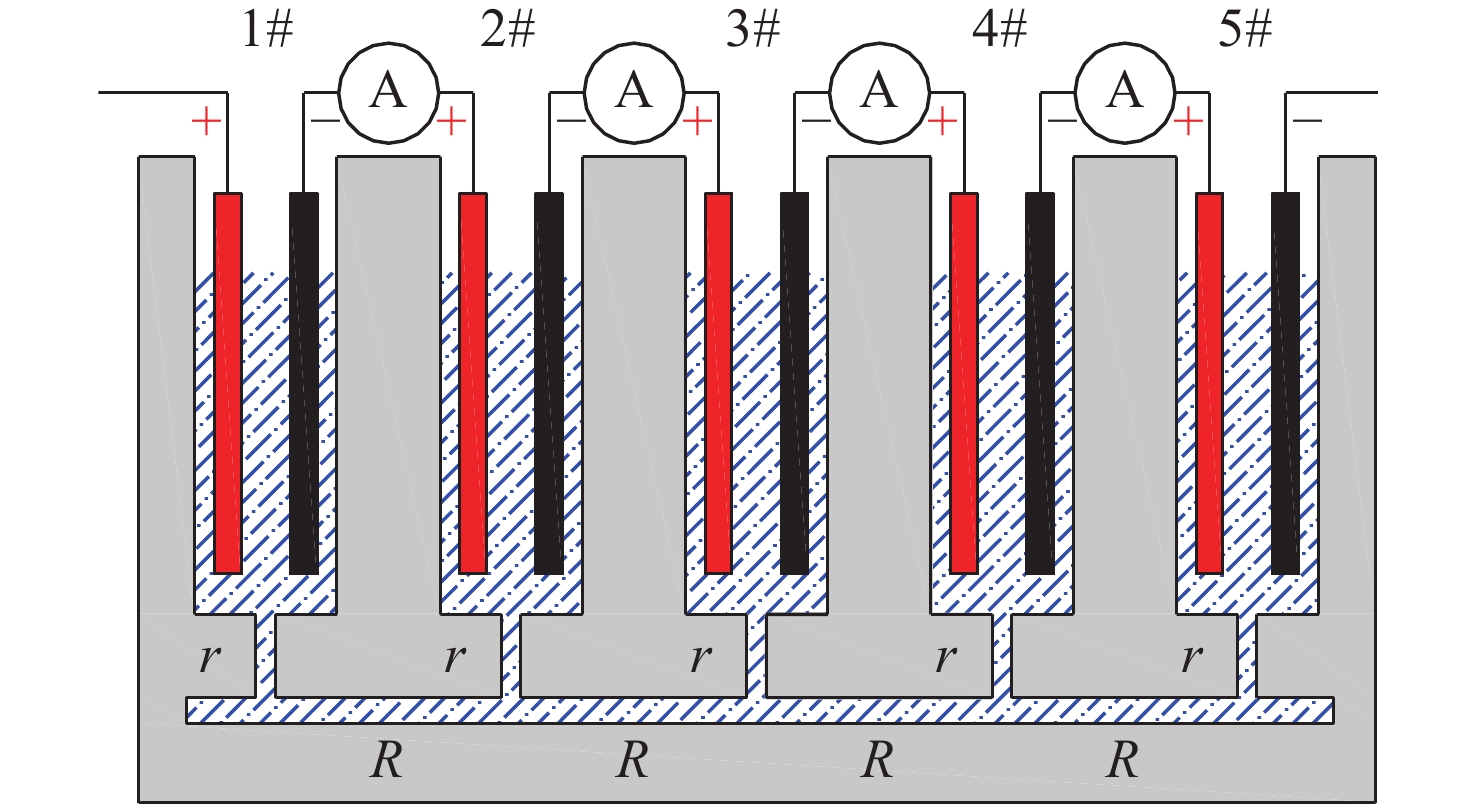
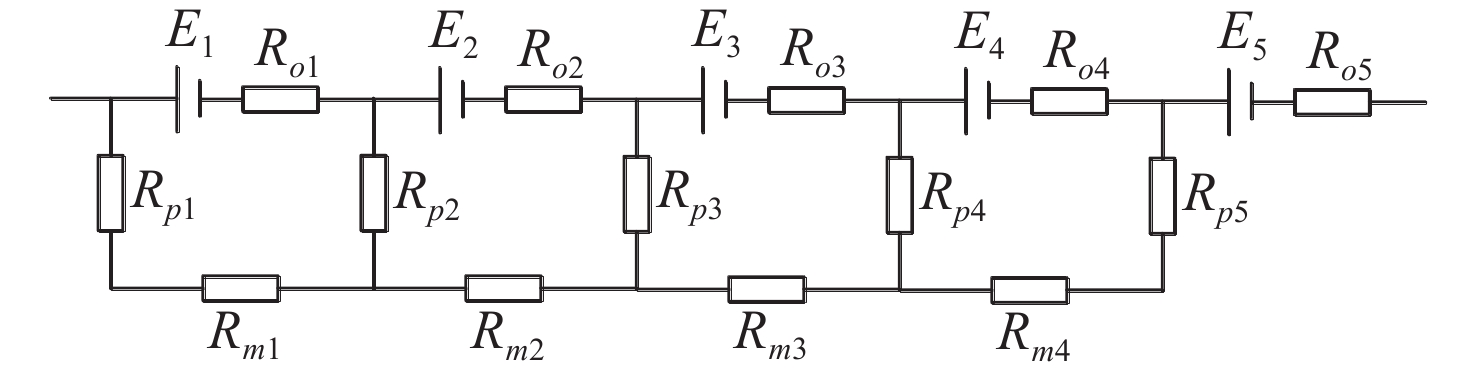
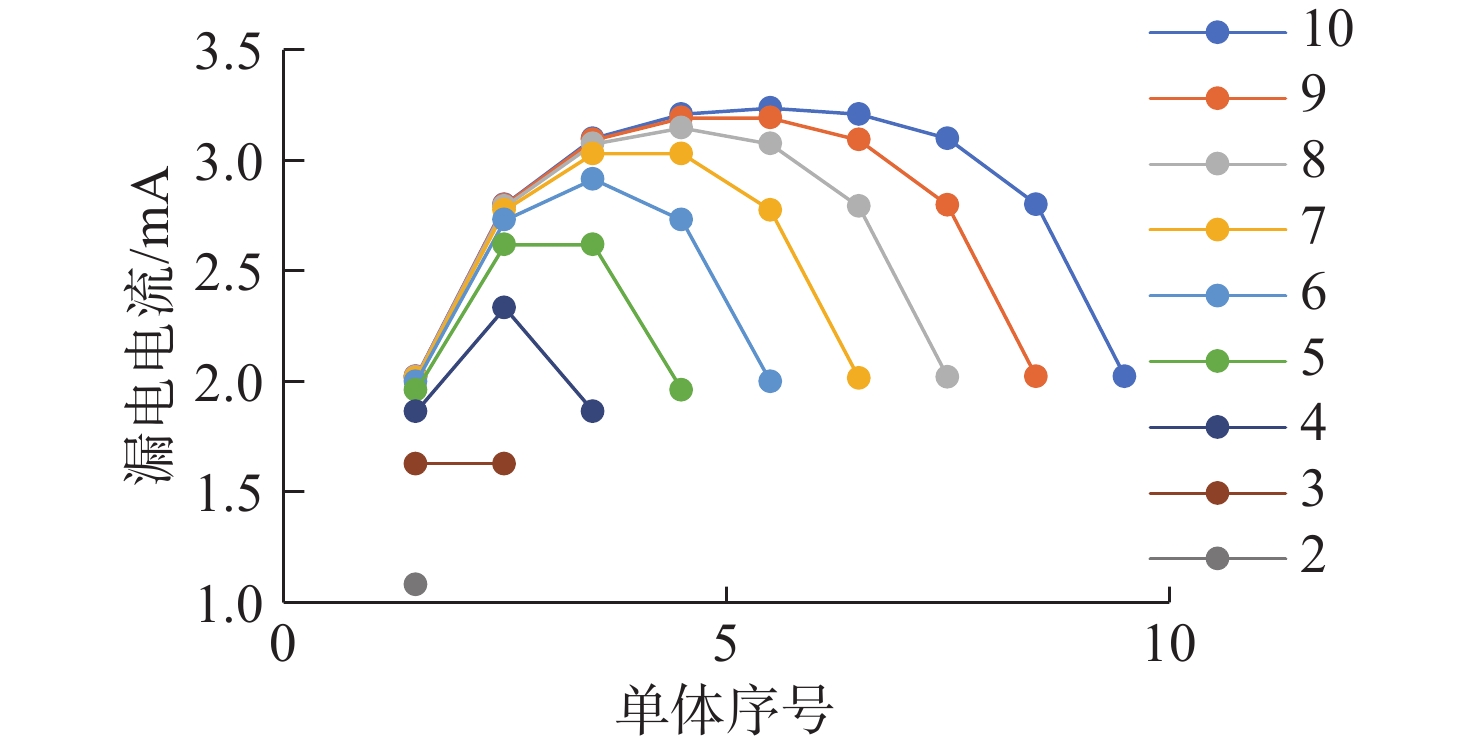
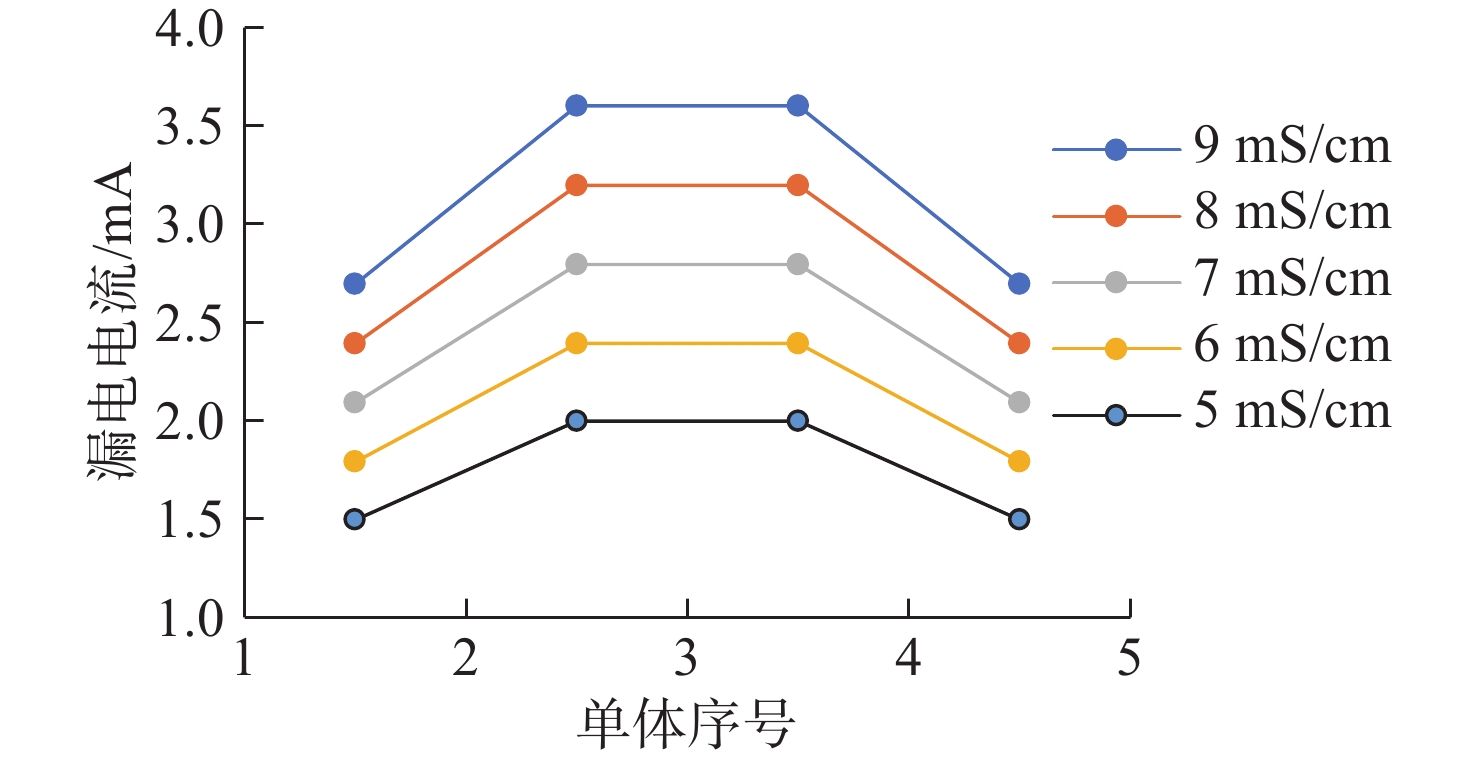

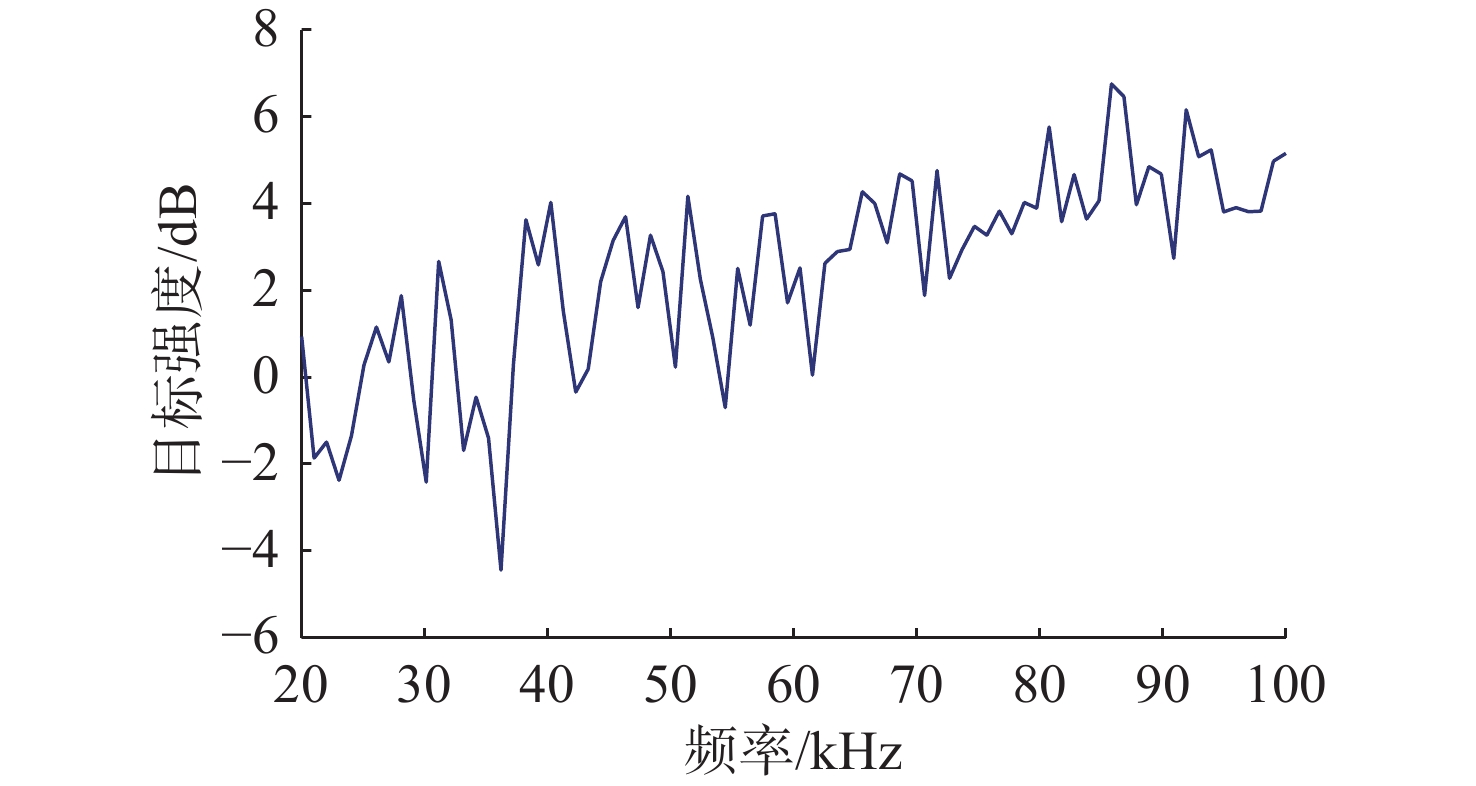

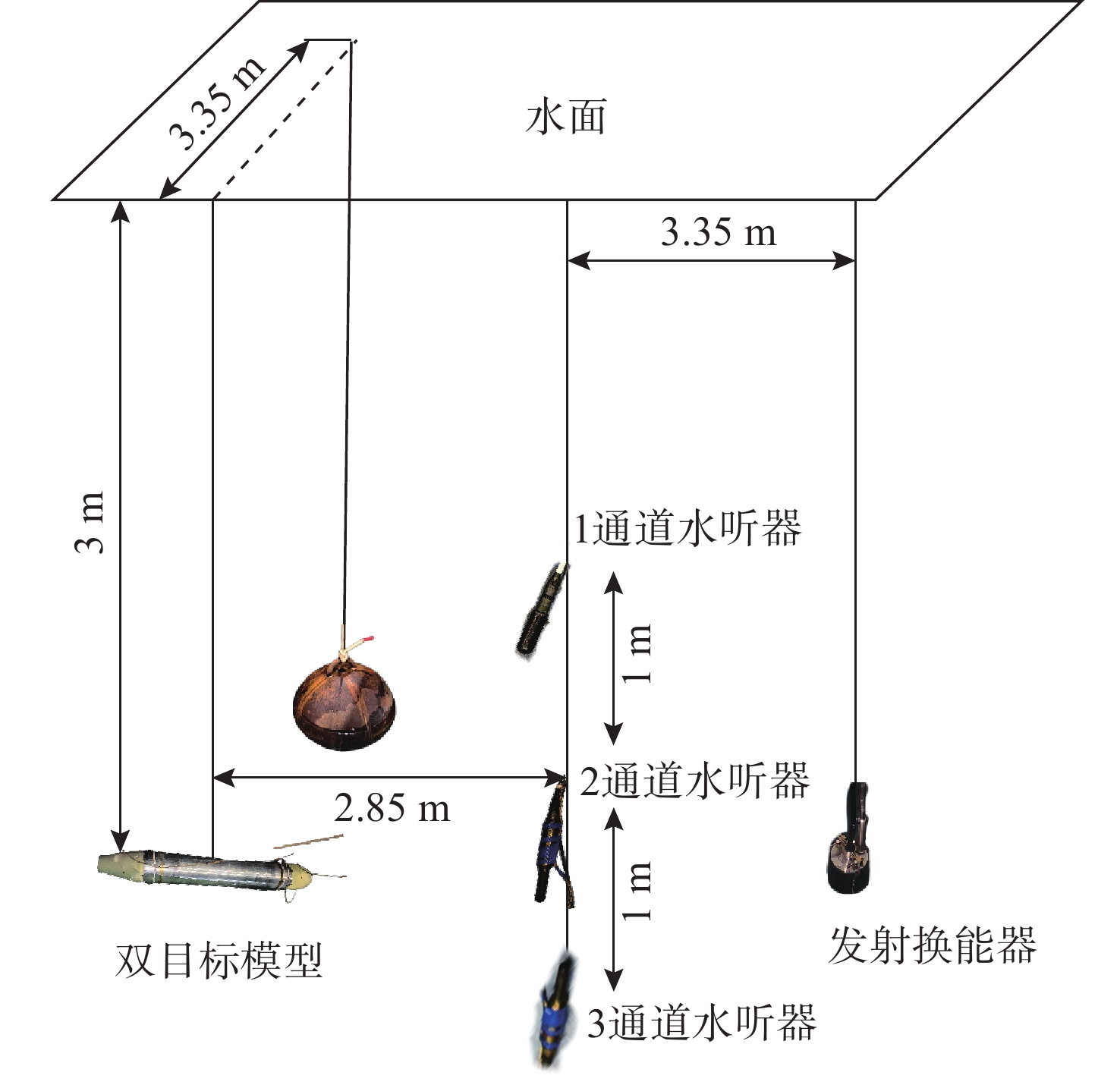

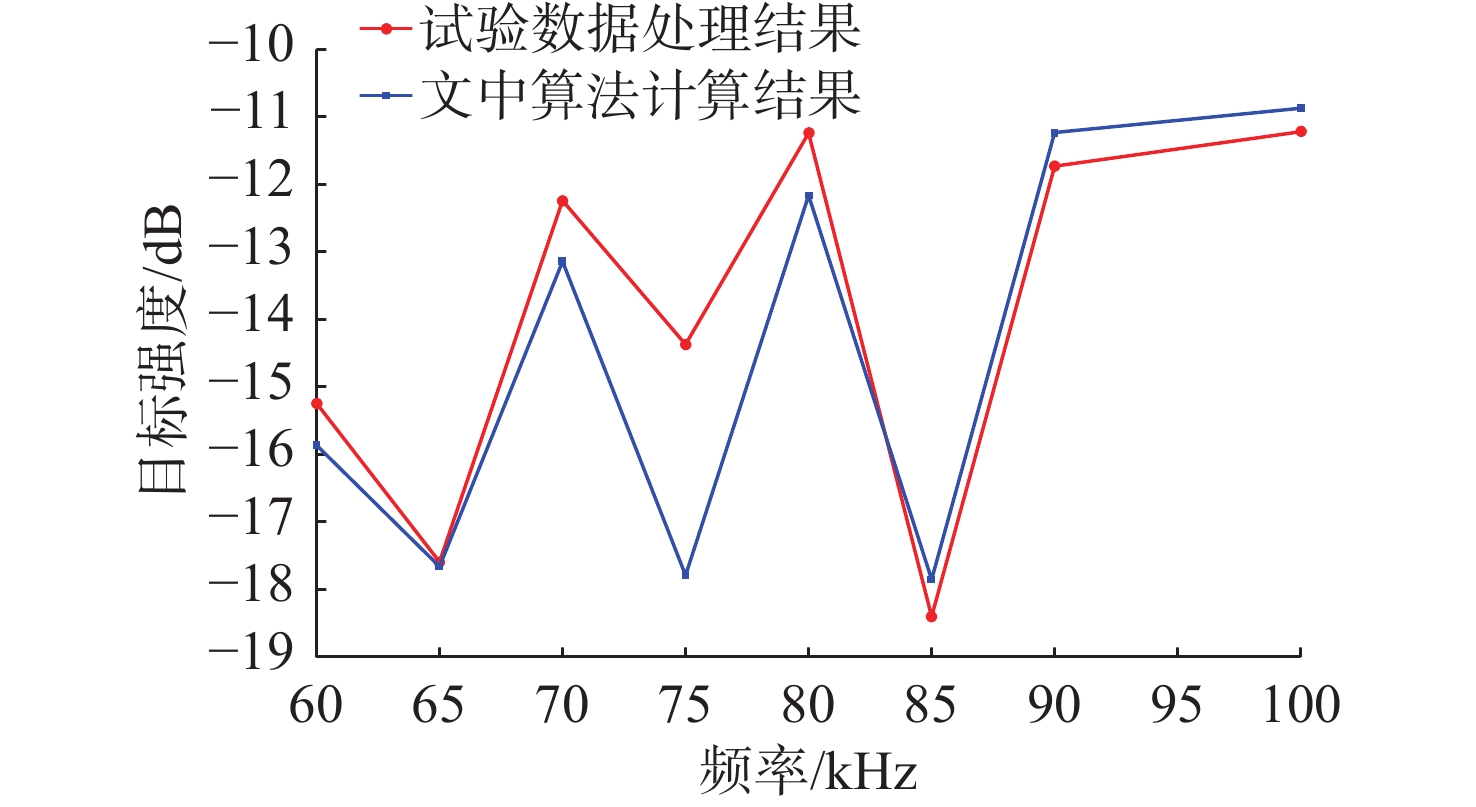
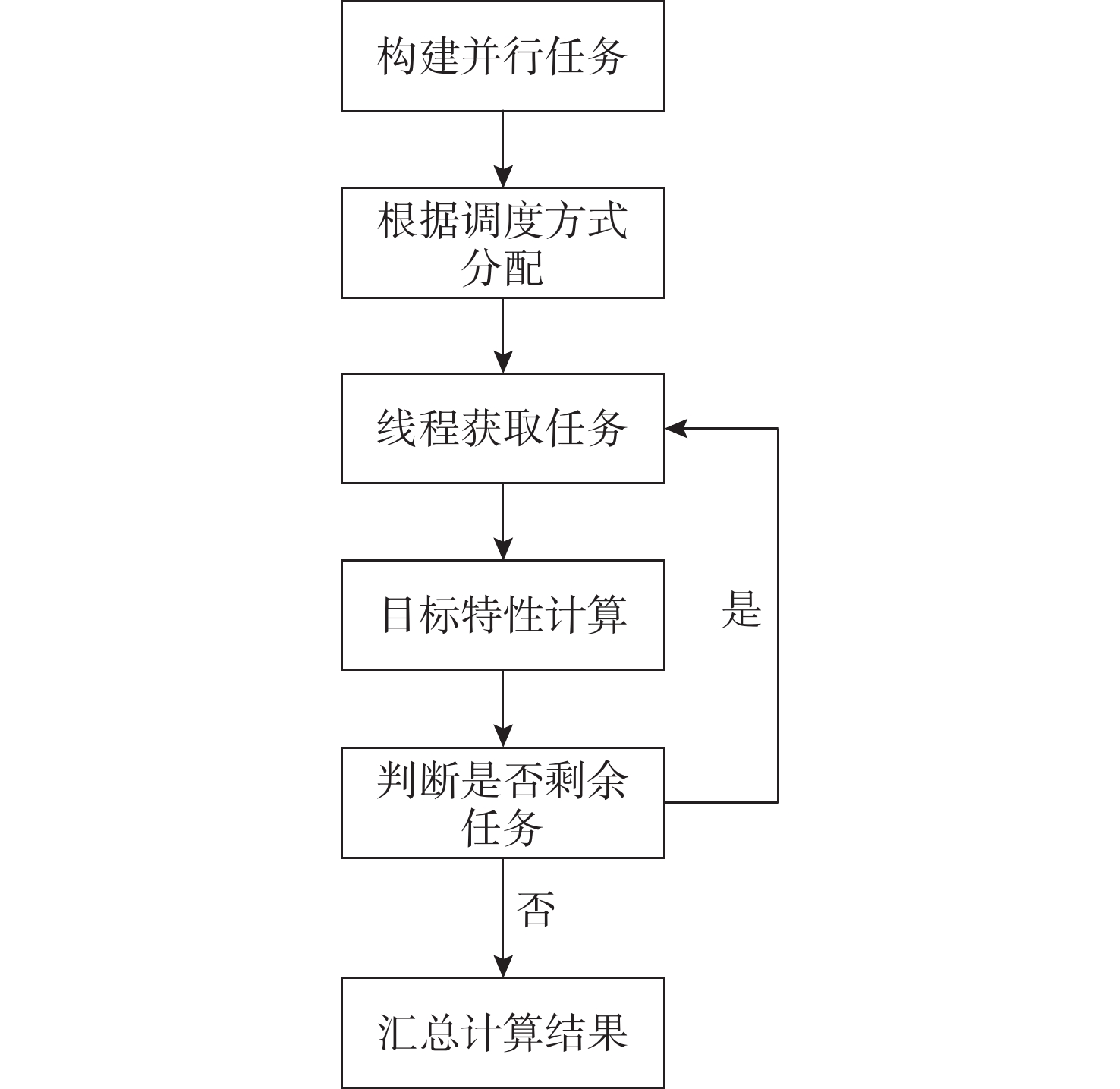
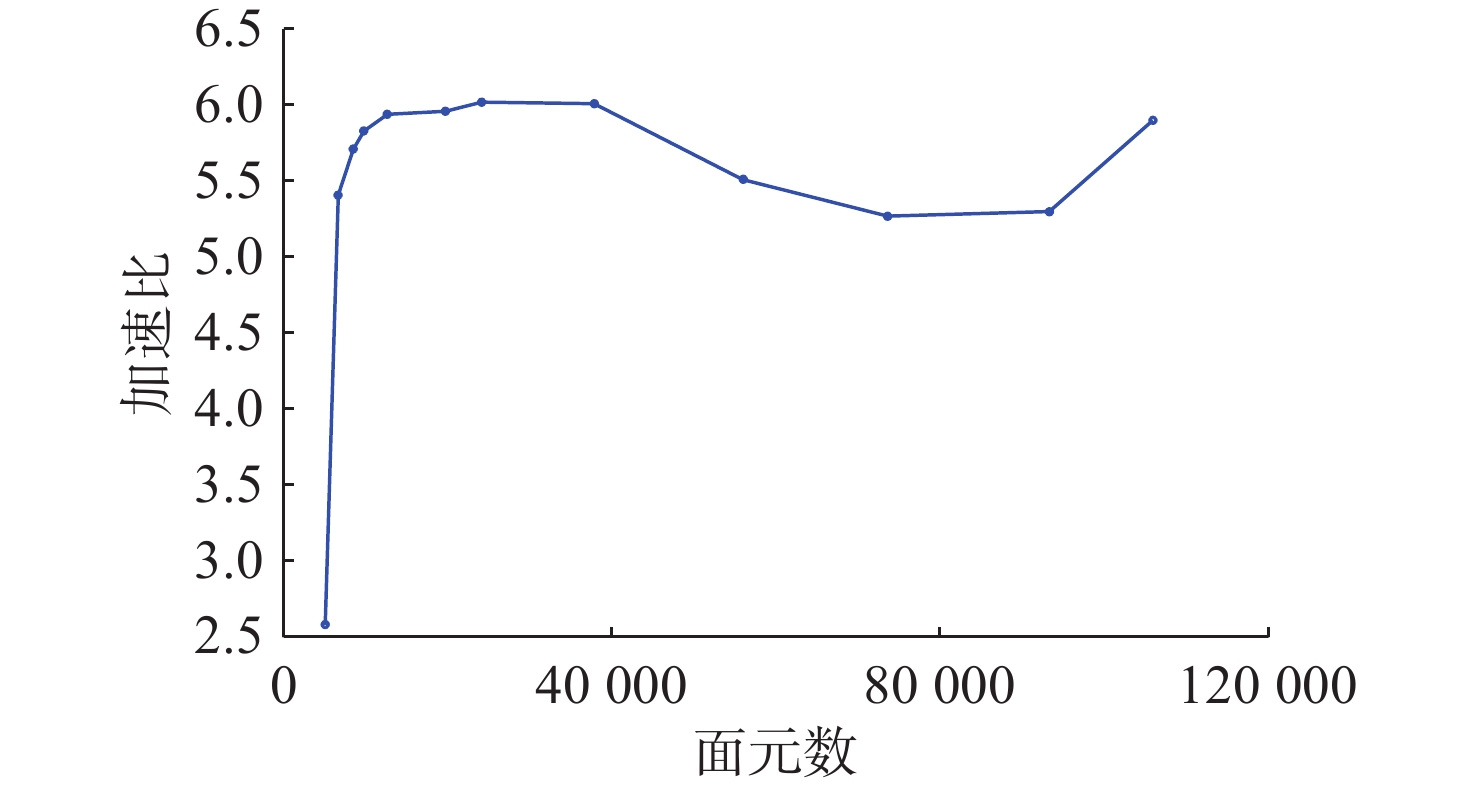
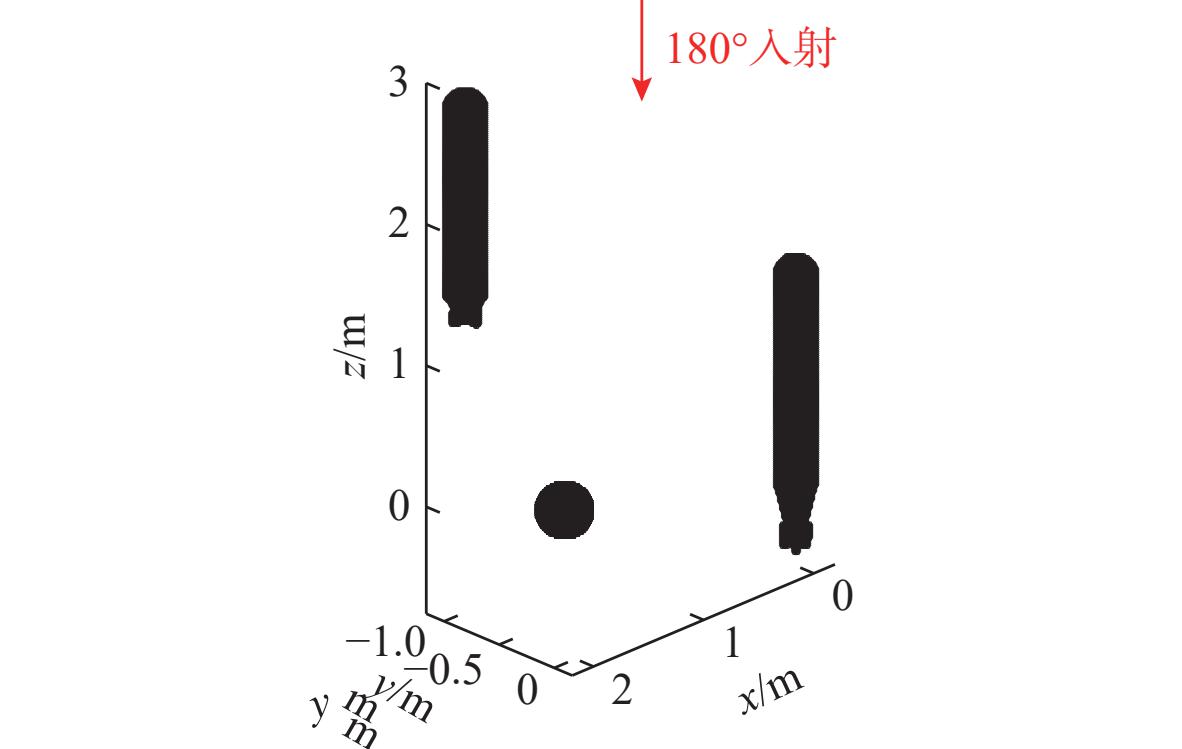
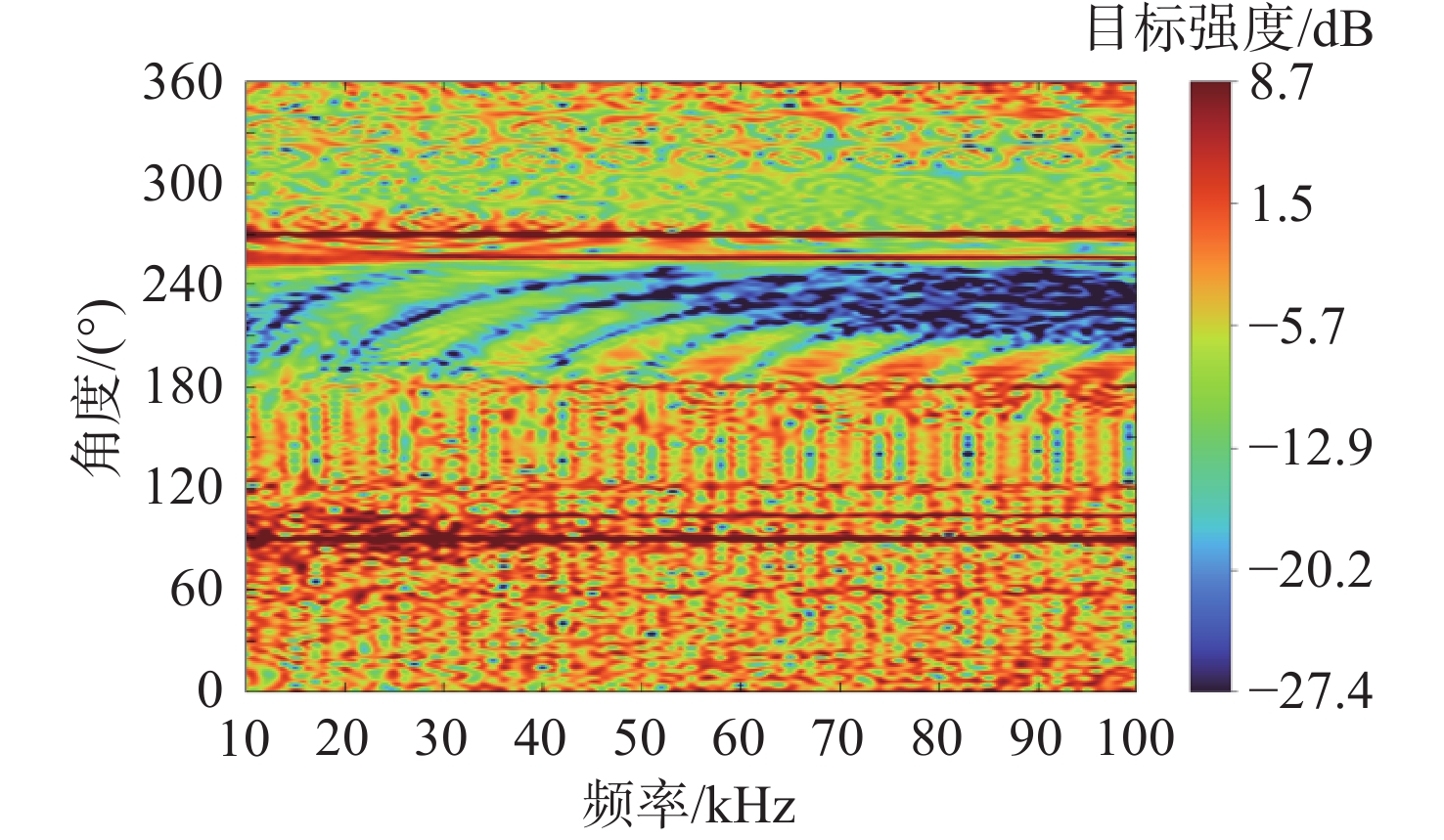
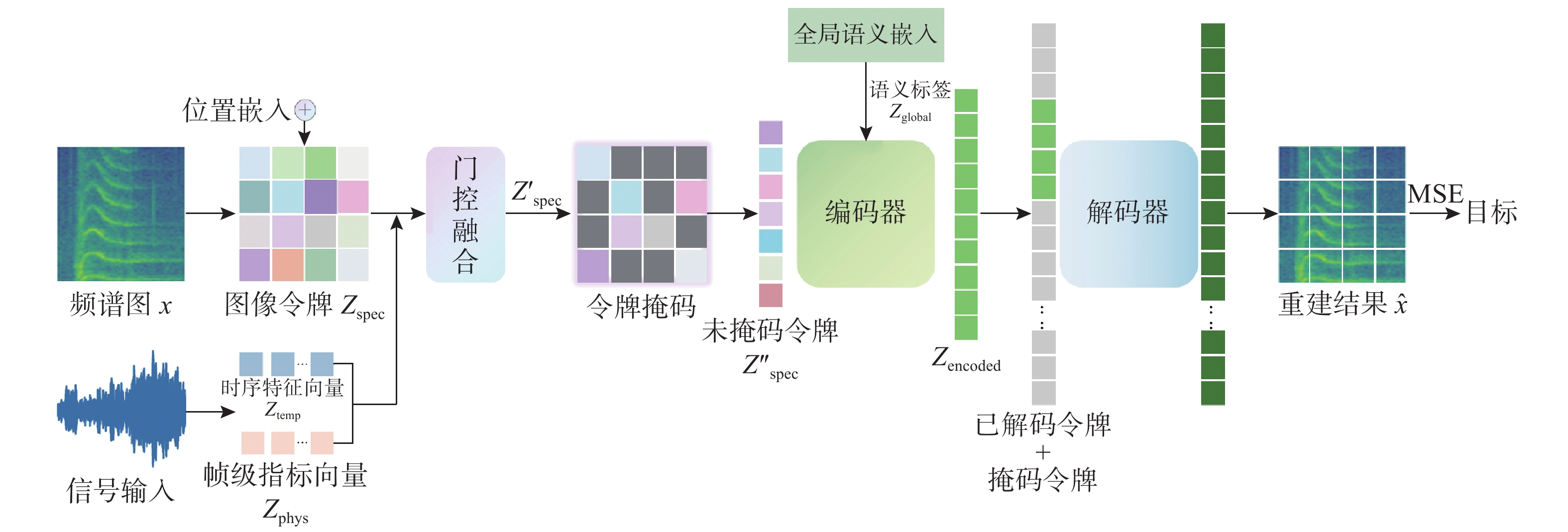
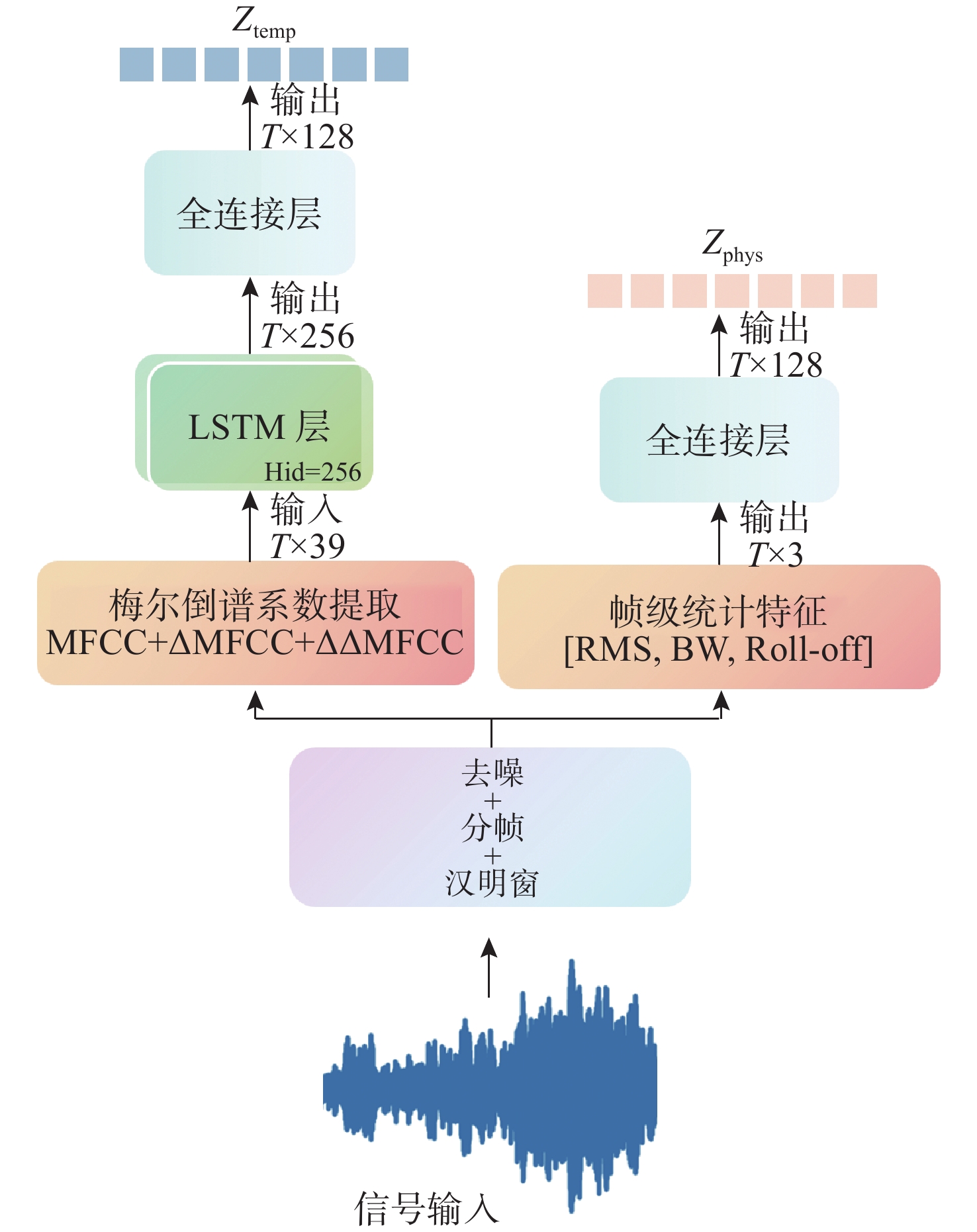
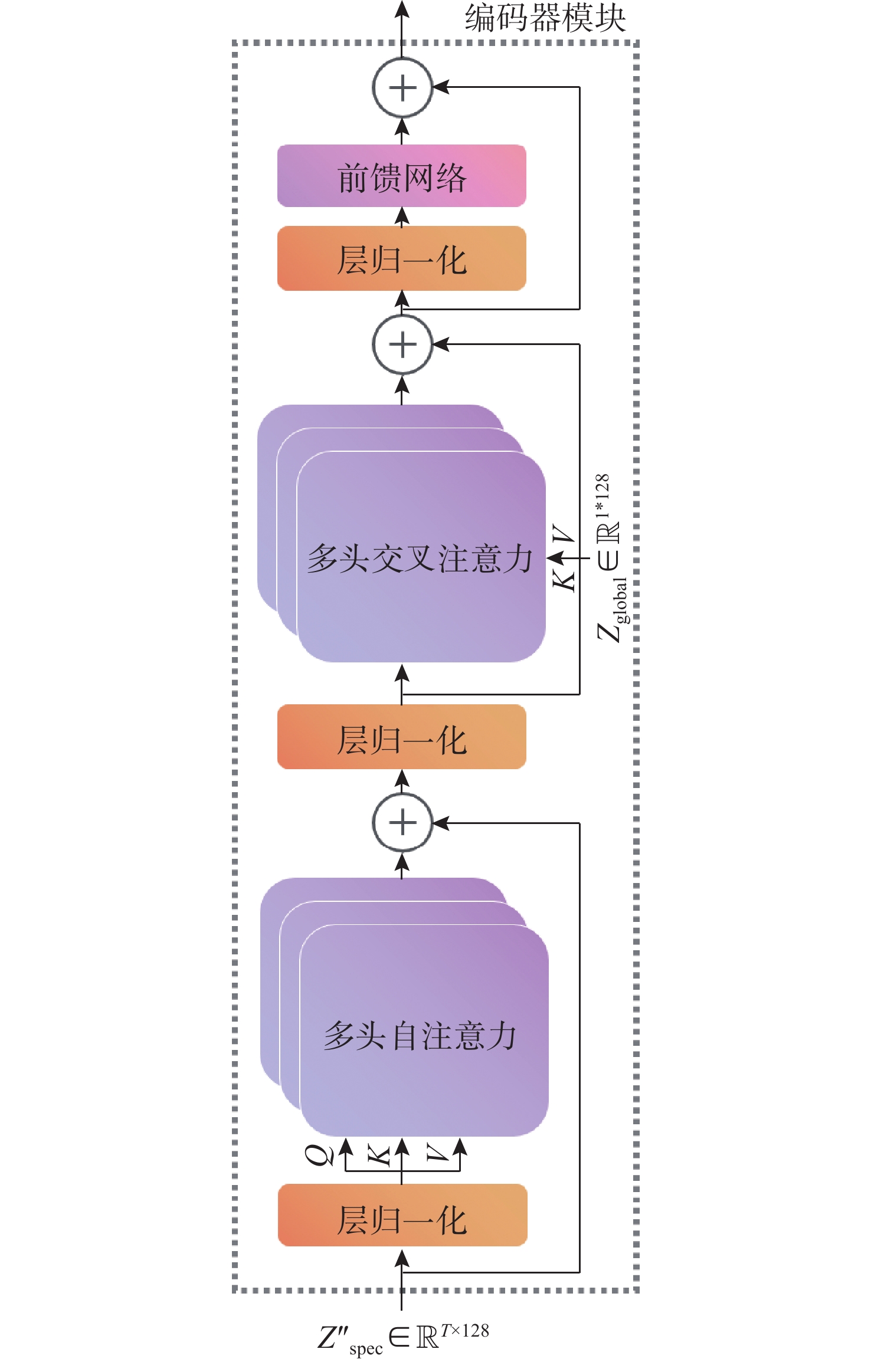
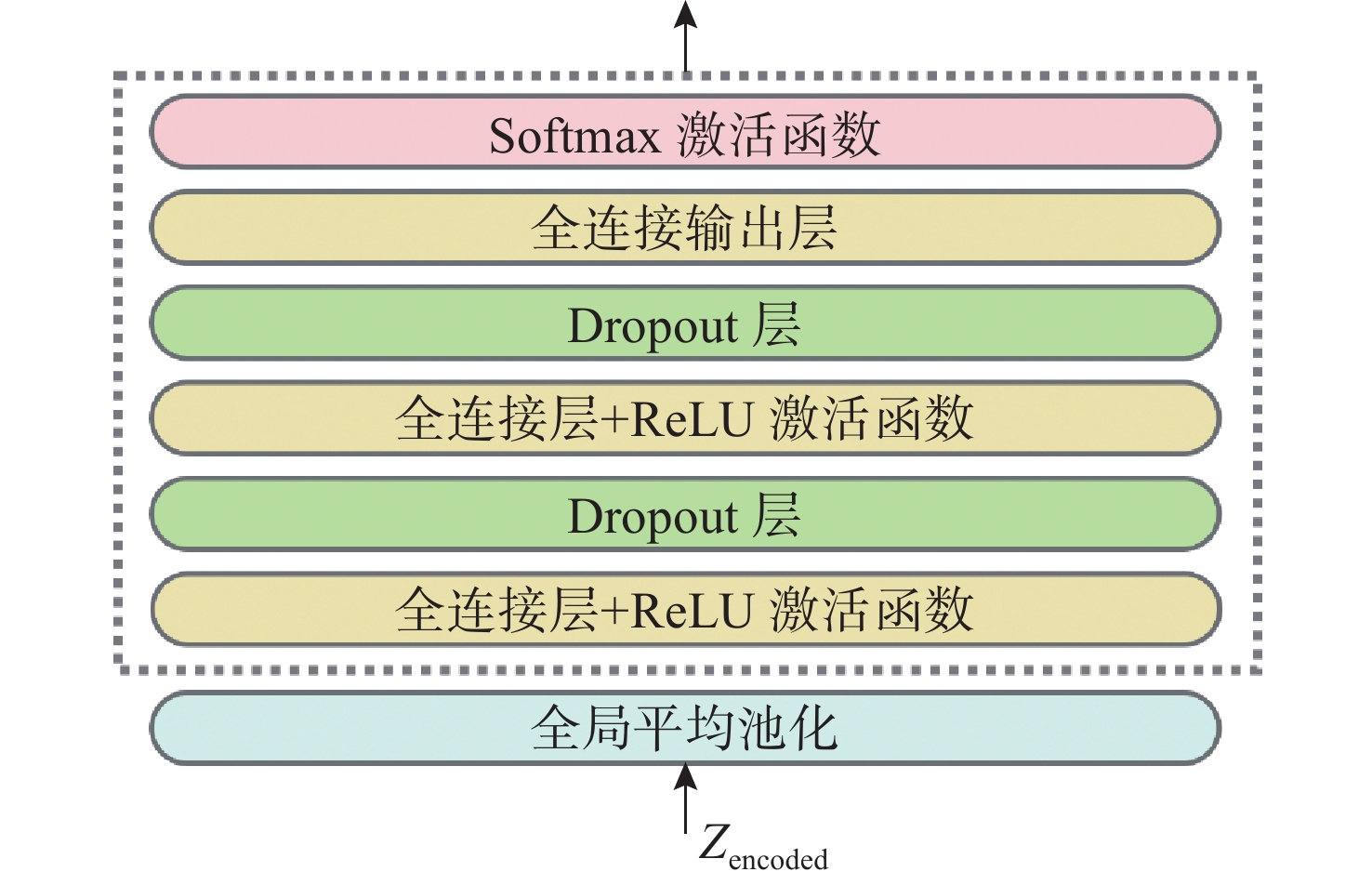
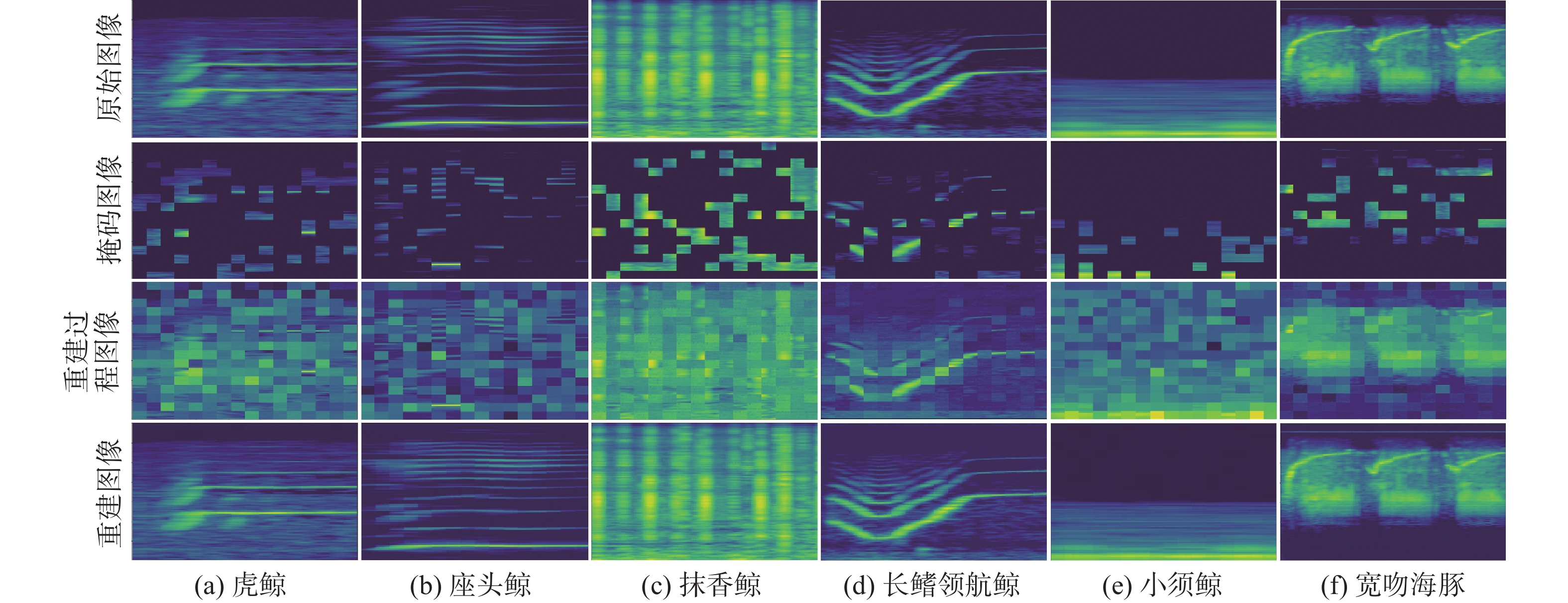
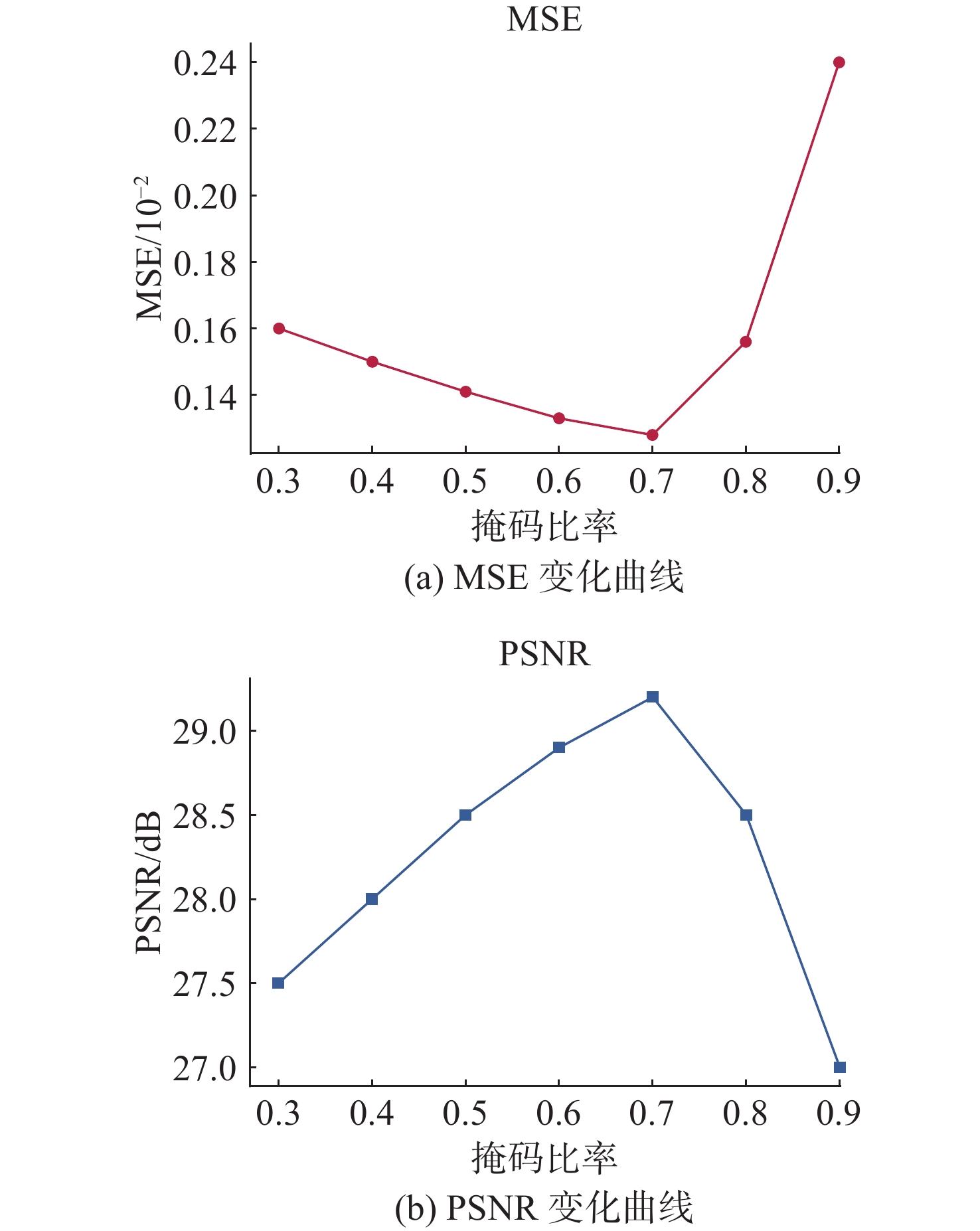
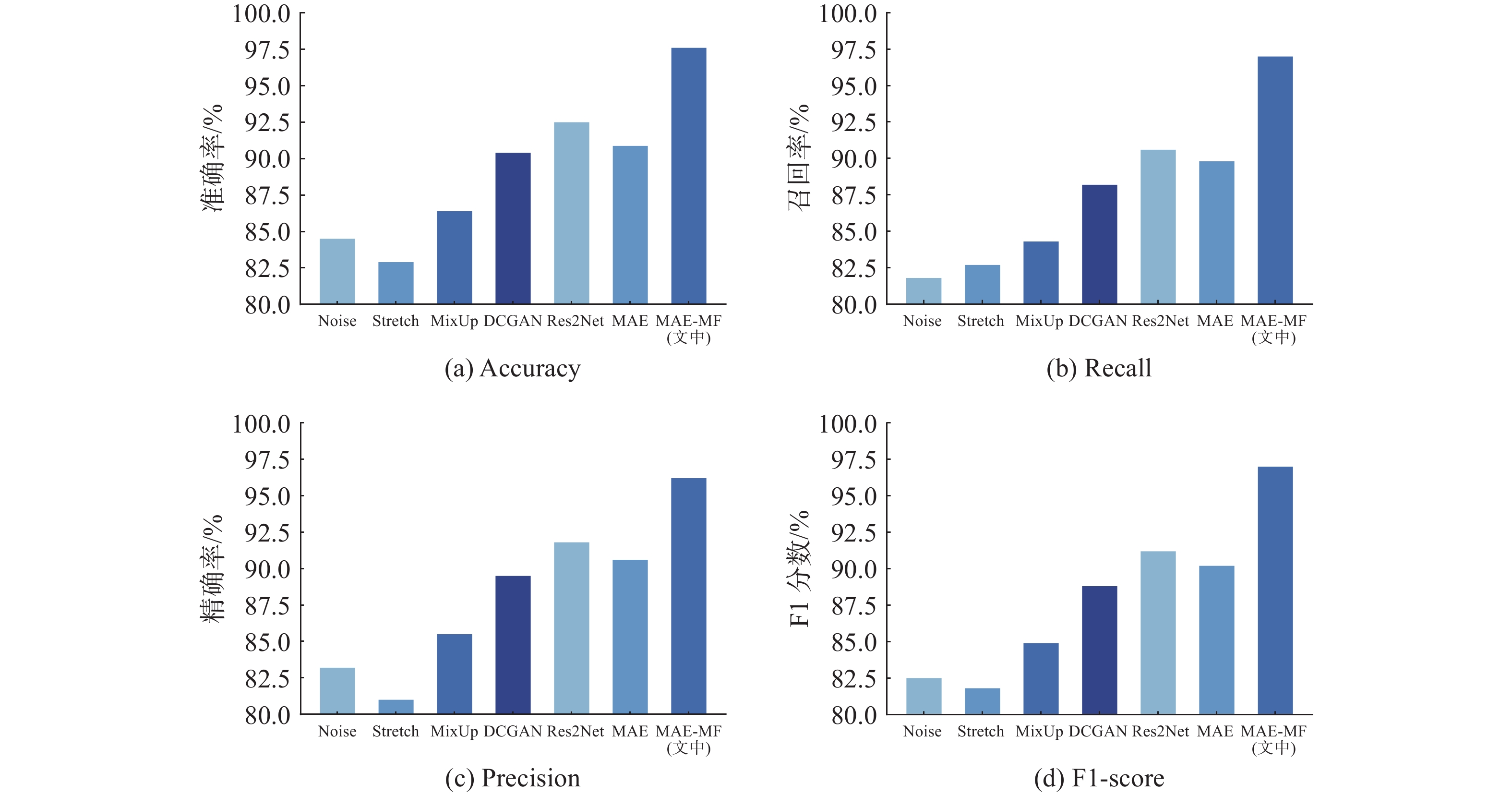
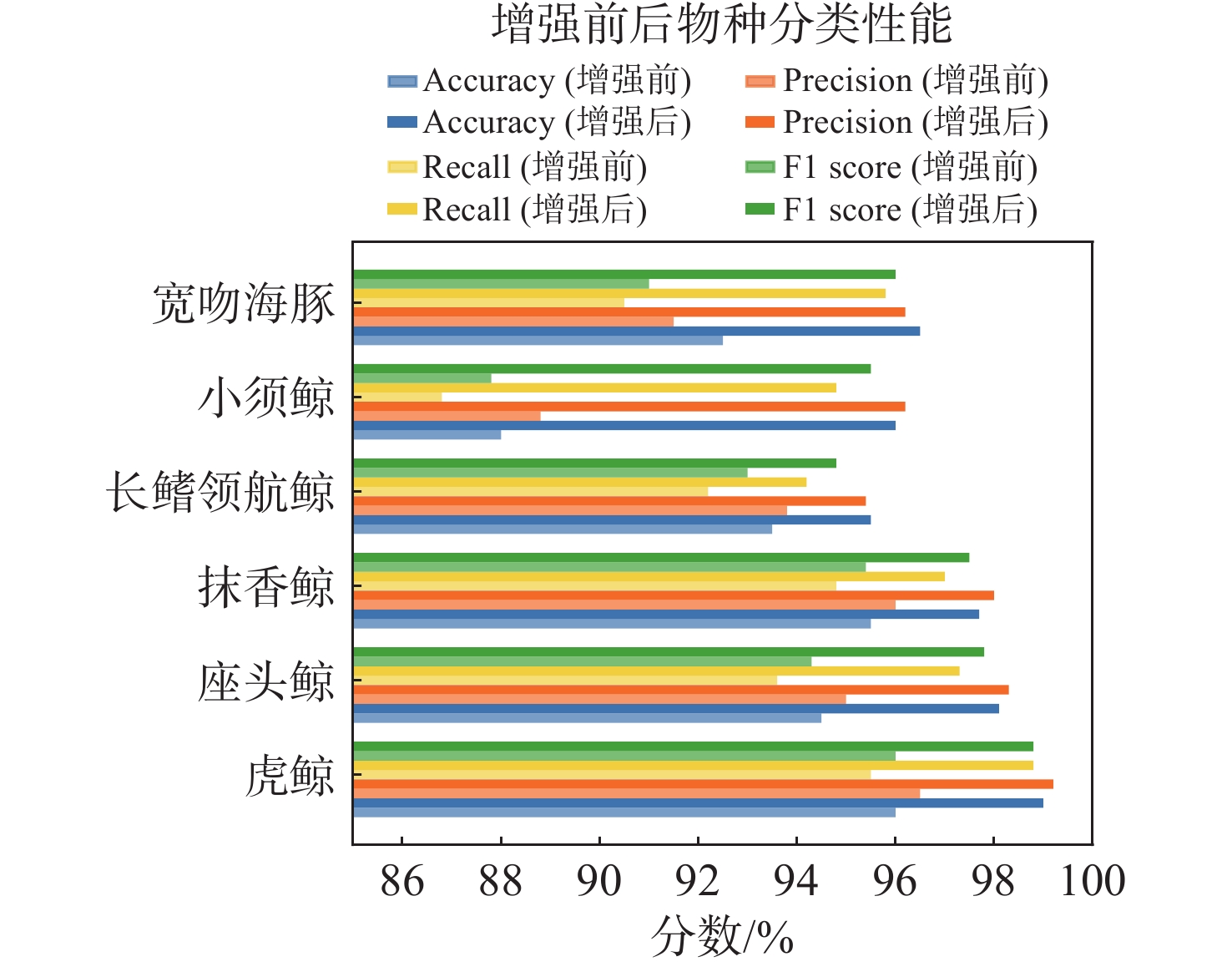
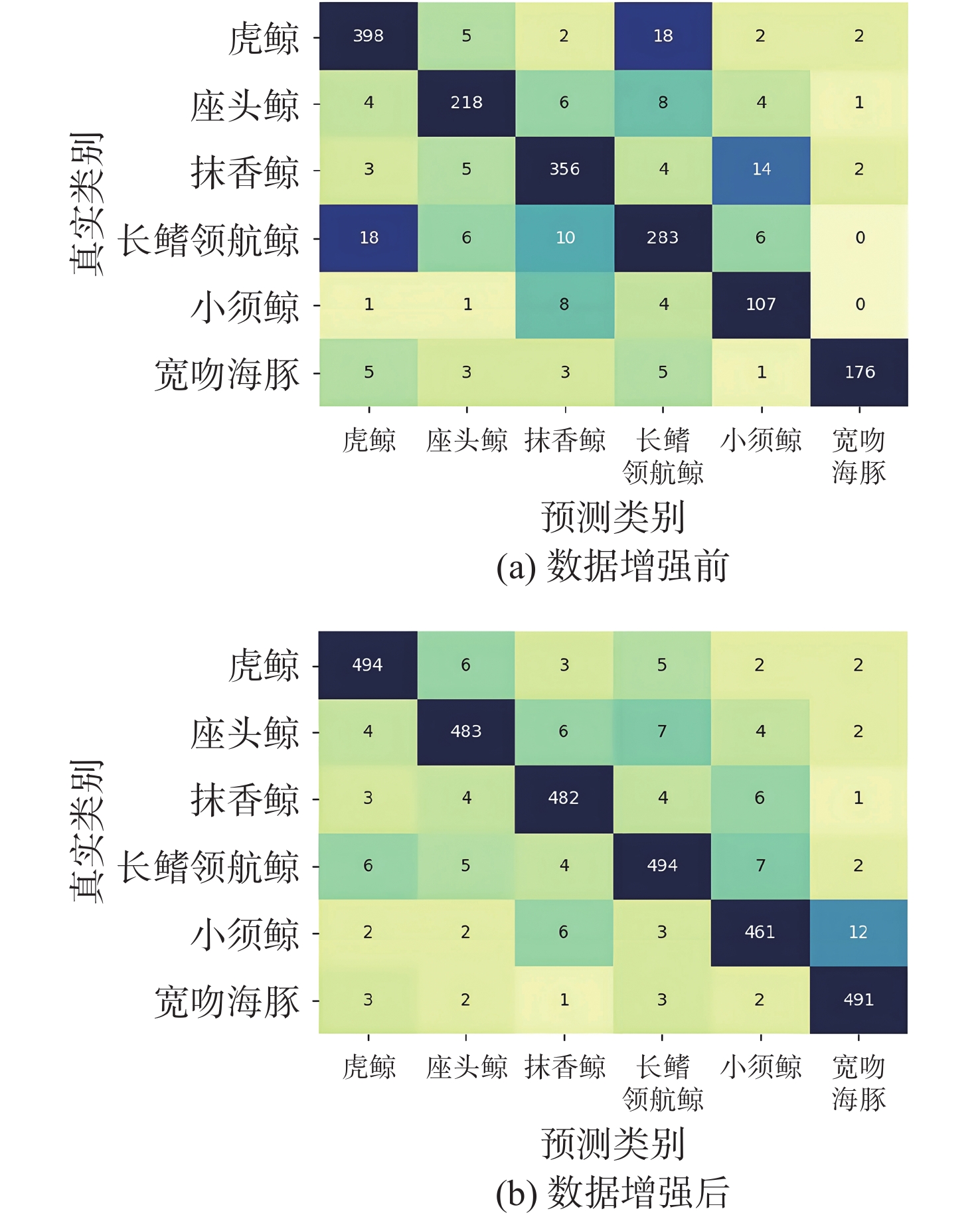
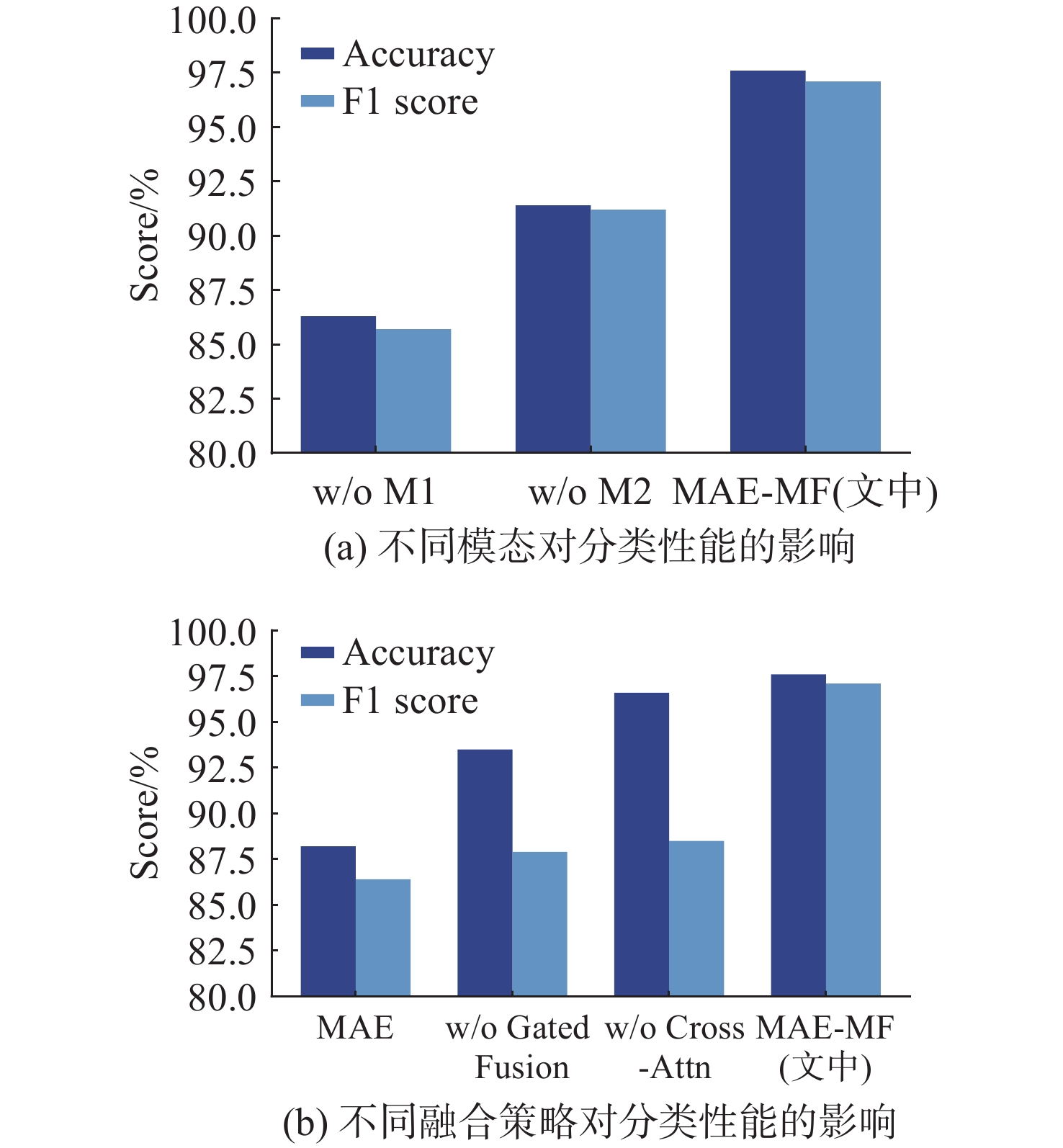
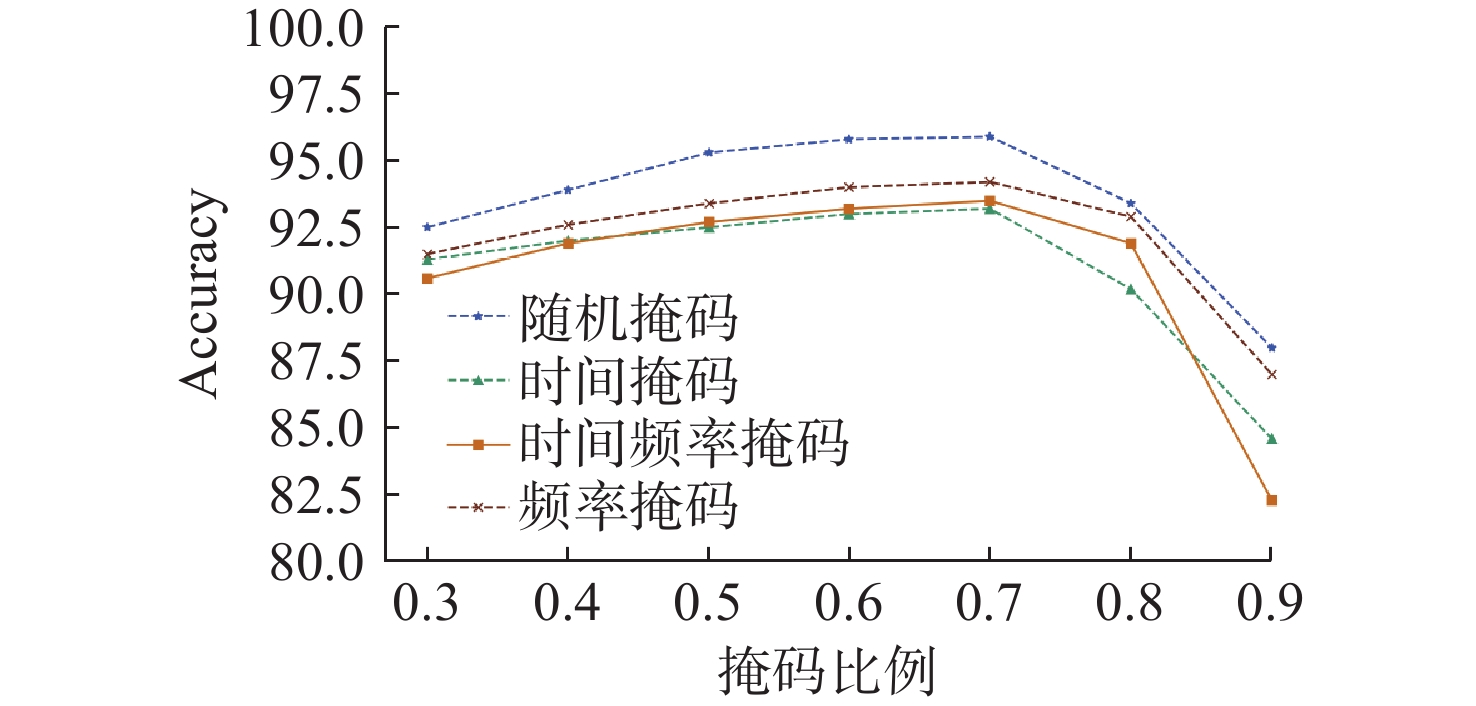
Cetacean call recognition and classification model based on multimodal MAE data augmentation network
, Available online , doi: 10.11993/j.issn.2096-3920.2026-0052
Abstract: