

Underwater Visual Guidance Deep Learning Detection Method for AUV
-
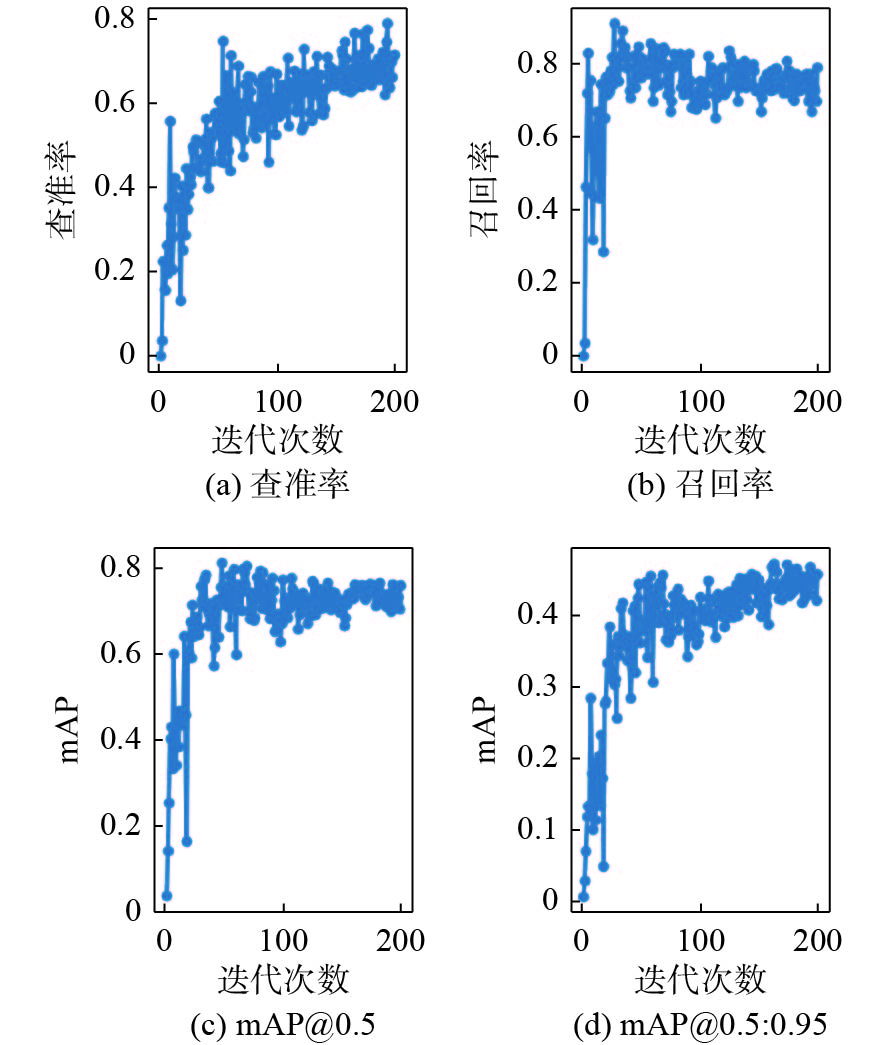
摘要: 自主水下航行器(AUV)自主对接与回收技术主要通过导引定位的方式实现AUV与对接装置的自主归航、接近、对接及锁紧等动作。为满足AUV水下自主对接过程中实时性、高精确性和鲁棒性等要求, 提出一种基于深度学习的水下视觉导引检测方法。针对复杂水下场景下传统图像处理方法检测效果不佳的问题, 使用基于YOLOv5的深度学习视觉导引检测方法对导引光源以及对接装置进行检测。首先, 将目标图像数据接入YOLOv5模型进行迭代训练, 将训练得到的最优模型参数保存用于后续实时检测; 然后, 在水下自主对接过程中, AUV使用机器人操作系统平台实时读取水下数据并调用YOLO服务对水下图像进行检测, 输出导引光源以及对接装置位置信息; 同时通过位置解算, 将检测得到的中心点坐标转化到AUV相机坐标系下; 最后将解算得到的AUV与对接装置的相对位置与AUV的航行方向持续反馈给AUV, 进行引导直至对接完成。在海试中对水下视觉导引的实际检测准确率为97.9%, 检测单帧耗时为45 ms, 试验结果表明该方法满足自主对接与回收技术中对水下对接精度及实时性要求, 具有实际应用价值。Abstract: The autonomous docking and recovery of autonomous undersea vehicle(AUV) technology mainly realizes the autonomous homing, approaching, docking, and locking of the AUV and the docking device by means of guidance and positioning. To satisfy the requirements of real time, high accuracy, and robustness in the process of AUV underwater autonomous docking, an underwater visual guidance detection method based on deep learning is proposed. To address the poor detection effect of traditional image processing methods in complex underwater scenes, the guiding light source and docking device are detected by employing a deep learning visual guidance detection method based on the YOLO(you only look once)v5 model. First, the object images are sent to YOLOv5 model for iterative training, and the optimal model parameters obtained from the training are saved for subsequent real-time detection. Subsequently, in the underwater autonomous docking process, the AUV utilizes the robot operating system(ROS) platform to read the underwater data and call the YOLO service to detect the underwater image in real-time, thereby outputting the location information of the guidance light source and the docking device. Based on position calculation, the detected center coordinates are transformed into the AUV camera coordinate system. Finally, the relative positions of the AUV with respect to the docking device and navigation directions of the AUV are calculated continuously and fed back into the AUV, which provides real-time guidance information until the docking progress is completed. In the sea trail, the actual accuracy of underwater visual guidance detection was 97.9%, and the detection time of a single frame was 45 ms. The test results demonstrate that this method meets the requirements of real-time underwater docking accuracy for autonomous docking and recovery technology, and has practical application value.
-

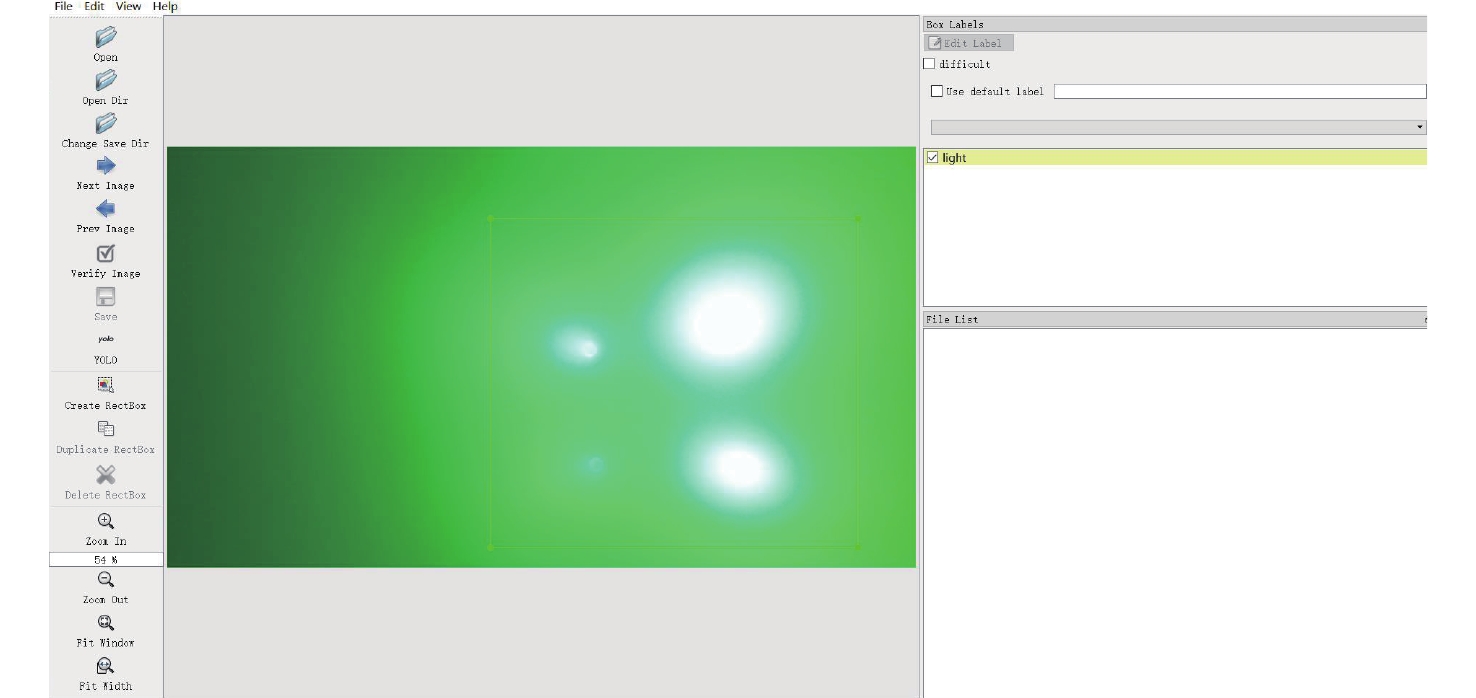
图 12 入坞试验水下图像实时检测结果
Figure 12. Real time detection results of underwater image of docking test
表 1 摄像机内参数和几何畸变系数
Table 1. Inside parameters of the camera and geometric distortion coefficients
相机参数和几何畸变系数 数值(水下) 焦距 ${k_x}/{\rm{mm}}$ 2 040.171 446 000 焦距 ${k_y}/{\rm{mm}}$ 1 961.473 938 000 主点${u_0}$ 1 226.527 241 000 主点 ${v_0}$ 436.187 531 400 径向畸变 ${k_{v1}}$ 1.340 839 079 径向畸变 ${k_{v2}}$ −0.135 553 263 切向畸变${k_{u1}}$ −0.111 415 771 切向畸变${k_{u2}}$ 0.169 324 890  下载: 导出CSV
下载: 导出CSV
-
[1] Liam P, Sajad S, Mae S, et al. AUV navigationand localization: A review[J]. IEEE Journal of Oceanic Engineering, 2014, 39(1): 131-149. doi: 10.1109/JOE.2013.2278891 [2] Inzartev A V, Matvienko Y V, Pavin A M, et al. Investigation of autonomous docking system elements for long term AUV[C]//Proceedings of MTS/IEEE Oceans. Washington, USA: IEEE, 2005: 388-393. [3] 孙叶义, 武皓微, 李晔, 等. 智能无人水下航行器水下回收对接技术综述[J]. 哈尔滨工程大学学报, 2019, 40(1): 1-11. doi: 10.11990/jheu.201712014Sun Yeyi, Wu Haowei, Li Ye, et al. Review of underwater docking technology for intelligent unmanned underwater vehicle[J]. Journal of Harbin Engineering University, 2019, 40(1): 1-11. doi: 10.11990/jheu.201712014 [4] 赵霞, 袁家政, 刘宏哲. 基于视觉的目标定位技术的研究进展[J]. 计算机科学, 2016, 43(6): 10-16, 43. doi: 10.11896/j.issn.1002-137X.2016.06.002Zhao Xia, Yuan Jiazheng, Liu Hongzhe. Advances in vision-based target location technology[J]. Computer Science, 2016, 43(6): 10-16, 43. doi: 10.11896/j.issn.1002-137X.2016.06.002 [5] 朱志鹏, 朱志宇. 一种基于双目视觉的水下导引光源检测和测距方法[J]. 水下无人系统学报, 2021, 29(1): 65-73. doi: 10.11993/j.issn.2096-3920.2021.01.010Zhu Zhipeng, Zhu Zhiyu. Method for detecting and ranging an underwater guided light source based on binocular vision[J]. Journal of Unmanned Undersea Systems, 2021, 29(1): 65-73. doi: 10.11993/j.issn.2096-3920.2021.01.010 [6] 姜言清. AUV回收控制的关键技术研究[D]. 哈尔滨: 哈尔滨工程大学, 2016. [7] 张梦辉. 基于机器视觉的自主式水下航行器末端导引系统关键技术研究[D]. 杭州: 浙江大学, 2018. [8] 胡震. 基于自主作业的AUV视觉系统[J]. 机器人, 2001, 23(6): 6. doi: 10.3321/j.issn:1002-0446.2001.06.011Hu Zhen. AUV optical vision system based on autonomous task[J]. Robot, 2001, 23(6): 6. doi: 10.3321/j.issn:1002-0446.2001.06.011 [9] Lecun Y, Bottou L. Gradient-based learning applied to document recognition[J]. Proceedings of the IEEE, 1998, 86(11): 2278-2324. doi: 10.1109/5.726791 [10] 彭玉青, 赵晓松, 陶慧芳, 等. 复杂背景下基于深度学习的手势识别[J]. 机器人, 2019, 41(4): 9. doi: 10.13973/j.cnki.robot.180568Peng Yuqing, Zhao Xiaosong, Tao Huifang, et al. Hand gesture recognition against complex background based on deep learning[J]. Robot, 2019, 41(4): 9. doi: 10.13973/j.cnki.robot.180568 [11] Shuang L, Ozay M, Okatani T, et al. A vision based system for underwater docking[J/OL]. arXiv, 2017, 12: 1-27. [2022-05-20]. https://arxiv.org/abs/1712.04138 [12] Girshick R, Donahue J, Darrell T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation[C]//IEEE Conference on computer vision and pattern recognition. Piscataway, USA: IEEE, 2014: 580-587. [13] Girshick R. Fast R-CNN[C]//IEEE International conference on computer vision. Santiago, USA: IEEE, 2015: 1017-1025. [14] Ren S, He K, Girshick R, et al. Faster R-CNN: Towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2017, 39(6): 1137-1149. [15] Liu W, Anguelov D, Erhan D, et al. SSD: Single shot multibox detector[C]//European conference on computer vision. Berlin, Germany: Springer, 2016: 21-37. [16] Redmon J, Divvala S, Girshick R, et al. You only look once: Unified, real-time object detection[C]//IEEE Conference on computer vision and pattern recognition. Piscataway, USA: IEEE, 2016: 779-788. [17] He K, Zhang X, Ren S, et al. Spatial pyramid pooling in deep convolutional networks for visual recognition[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015, 37(9): 1904-1916. doi: 10.1109/TPAMI.2015.2389824 [18] Wang C Y, Mark L H Y, Wu Y H, et al. CSPNet: A new backbone that can enhance learning capability of CNN[C]//IEEE/CVF Conference on computer vision and pattern recognition workshops(CVPRW). Piscataway, USA: IEEE, 2020: 1571-1580. [19] Rezatofighi H, Tsoi N, Gwak J A, et al. Generalized intersection over union: A metric and a loss for bounding box regression[C]//IEEE/CVF Conference on computer vision and pattern recognition. Piscataway, USA: IEEE, 2019: 658-666. [20] Sun X Y, Duan J. Design of multi-parameter target used in calibration of high precision CCD camera[J]. Optik-International Journal for Light and Electron Optics, 2016, 127(2): 548-552. doi: 10.1016/j.ijleo.2015.10.109 -







 点击查看大图
点击查看大图

图(13) / 表(1)
计量
- 文章访问数: 137
- HTML全文浏览量: 201
- PDF下载量: 59
- 被引次数: 0




